先看最终效果:
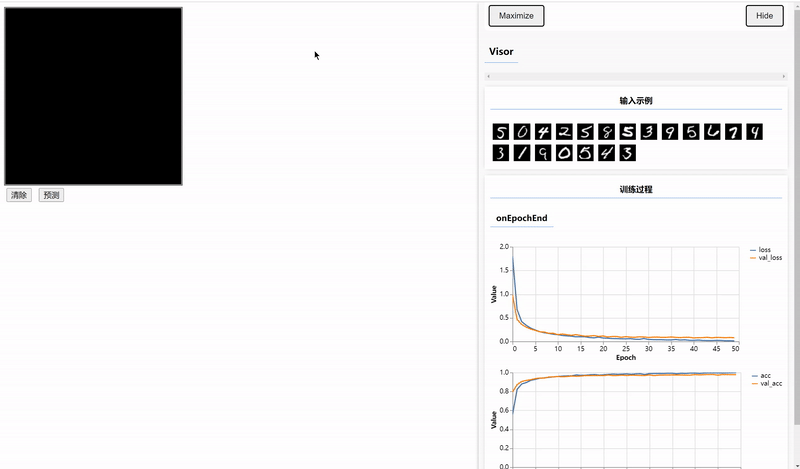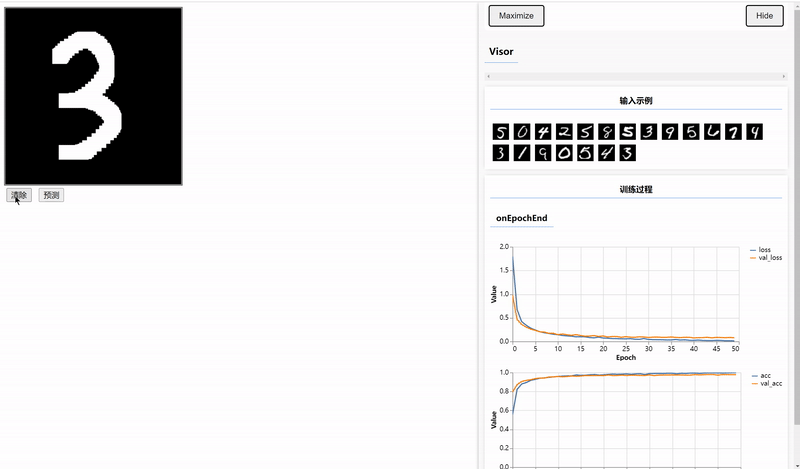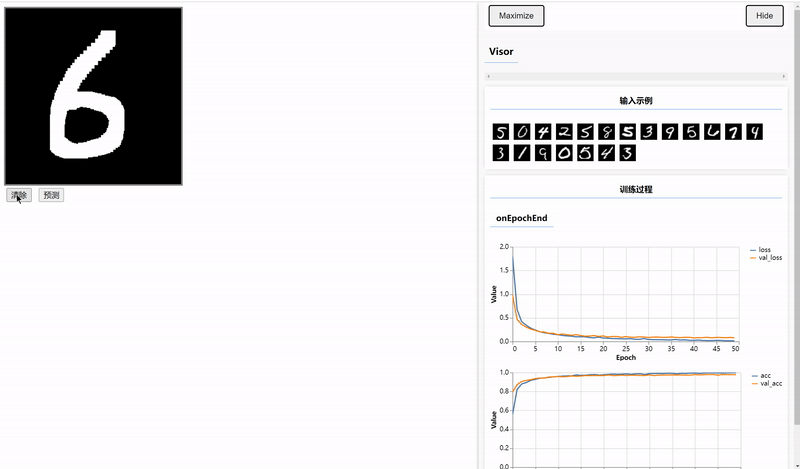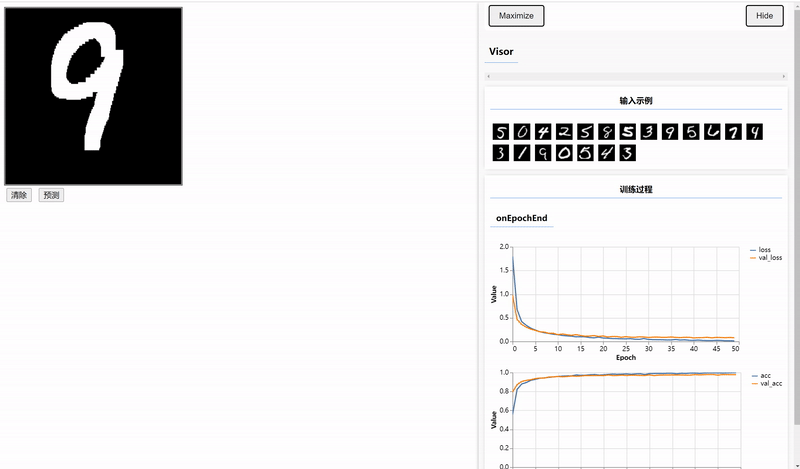
一、加载MNIST数据集
使用预先准备好的脚本加载MNIST数据集,脚本可在文章末尾的源码里面获取。
为了避免从国外直接下载数据集花费太多时间,所以脚本文件里面已经将地址改成本地的,因此你需要现将MNIST数据保存在本地,数据集也可以在源码力获取。
脚本里面关于MNIST路径的配置如下:
const MNIST_IMAGES_SPRITE_PATH =
'http://127.0.0.1:8080/mnist/mnist_images.png';
const MNIST_LABELS_PATH =
'http://127.0.0.1:8080/mnist/mnist_labels_uint8';因此在VsCode中需要先在本地来一个8080的端口,用于加载数据集。
npm i http-server -g
http-server data --cors第一句表示安装一个全局的http-server。
第二局是启动一个8080的端口,默认就是8080的端口,端口号与脚本中数据的路径开端口一致。data是项目中保存MNIST数据的文件夹名称,–cors是防止跨域问题。
配置成功就可以直接在浏览器输入数据地址直接访问数据了。
关于http-server的使用,可以参考:
http-server基本使用_echohye的技术博客_51CTO博客
创建index.html入口文件,跳转到script.js,主要功能代码写在js文件中。
<script src="script.js"></script>在js文件中加载数据。
import * as tf from "@tensorflow/tfjs"
import * as tfvis from "@tensorflow/tfjs-vis"
import {MnistData} from "./data"
window.onload = async () => {
// 创建MNIST对象
const data = new MnistData();
// 加载数据
await data.load();
// 获取数据查看数据结构
const samples = data.nextTestBatch(20);
console.log(samples)
}运行项目
parcel mnist/*html注意之前启动8080端口的终端是不能关掉的,所以需要重新启动一个终端输入上面命令运行项目。
结果:
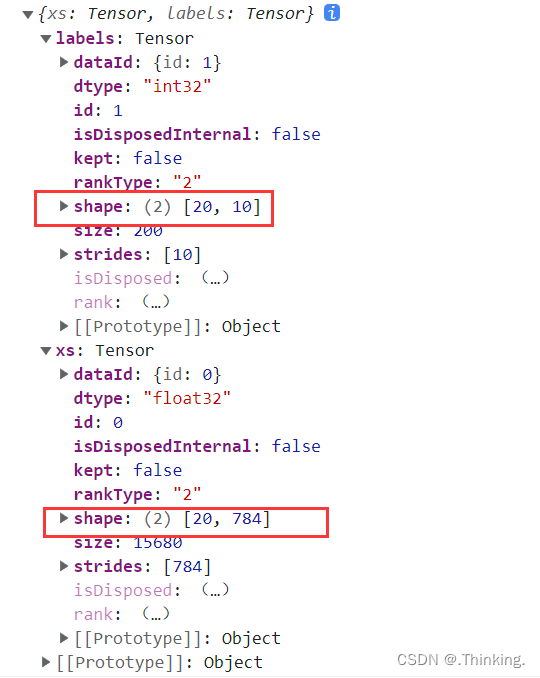
可以看见标签的形状是[20, 10],表示20个数据,我们在代码中就是取20数据查看的,10表示0~9总共10个标签,标签采用独热码形式。
特征的形状是[20,784],20还是一样表示20个数据,784表示每个数据的像素点总数,由于MNIST图片是28*28的。
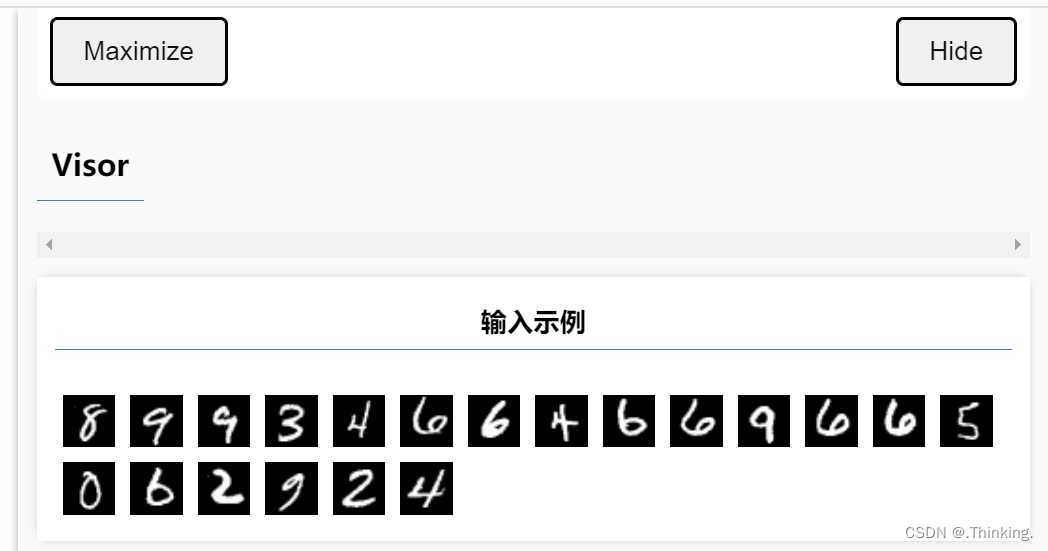
可视化数据集
// 创建sutface对象用于显示图片
const surface = tfvis.visor().surface({name: "输入示例"})
for(let i=0;i<20;i++){
const imageTensor = tf.tidy(() => {
return samples.xs.slice([i, 0], [1, 784]).reshape([28,28,1]);
});
// 创建Canvas对象
const canvas = document.createElement("canvas");
canvas.width = 28;
canvas.height = 28;
// 每张图片外边距4px
canvas.style = "margin: 4px";
// 可视化图片
await tf.browser.toPixels(imageTensor, canvas);
surface.drawArea.appendChild(canvas)
}浏览器可显示我们提取的20张图片:
二、构建卷积神经网络并训练
两层卷积层+两层最大池化层+一层全连接层。第二层卷积层不需要设置输入数据的形状,网络会根据第一层的结果自动算出来,全连接层的神经元个数与分类类别数一致,我们需要识别0~9总共10个数字,所以神经元个数设置为10。
// 构建卷积神经网络
const model = tf.sequential();
// 添加卷积层
model.add(tf.layers.conv2d({
inputShape: [28, 28, 1],
kernelSize: 5,
filters: 8,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceSaling'
}));
// 添加最大池化层
model.add(tf.layers.maxPool2d({
poolSize: [2 ,2],
strides: [2, 2]
}));
// 添加卷积层
model.add(tf.layers.conv2d({
kernelSize: 5,
filters: 16,
strides: 1,
activation: 'relu',
kernelInitializer: 'varianceSaling'
}));
// 添加最大池化层
model.add(tf.layers.maxPool2d({
poolSize: [2 ,2],
strides: [2, 2]
}));
// 展平
model.add(tf.layers.flatten());
// 全连接层
model.add(tf.layers.dense({
units: 10,
activation: 'softmax',
kernelInitializer: 'varianceSaling'
}))
设置损失函数和优化器。
// 配置损失函数和优化器
model.compile({
loss: "categoricalCrossentry",
optimizer: tf.train.adam(),
metrics: 'accuracy'
});准备训练集和验证集。
// 准备训练集和验证集
const [train_x, train_y] = tf.tidy(() => {
const train_data = data.nextTrainBatch(5000);
return [
// 需要将训练数据成卷积第一层的输入形状
train_data.xs.reshape([5000, 28, 28, 1]),
train_data.labels,
]
});
const [val_x, val_y] = tf.tidy(() => {
const val_data = data.nextTestBatch(1000);
return [
// 需要将训练数据成卷积第一层的输入形状
val_data.xs.reshape([1000, 28, 28, 1]),
val_data.labels,
]
});
训练模型并可视化训练过程。
// 训练模型并可视化训练过程
await model.fit(train_x, train_y, {
validationData: [val_x, val_y],
batchSize: 32,
epochs: 50,
callbacks: tfvis.show.fitCallbacks(
{name: '训练过程'},
['loss', 'val_loss', 'acc', 'val_acc'],
{callbacks: ['onEpochEnd']}
)
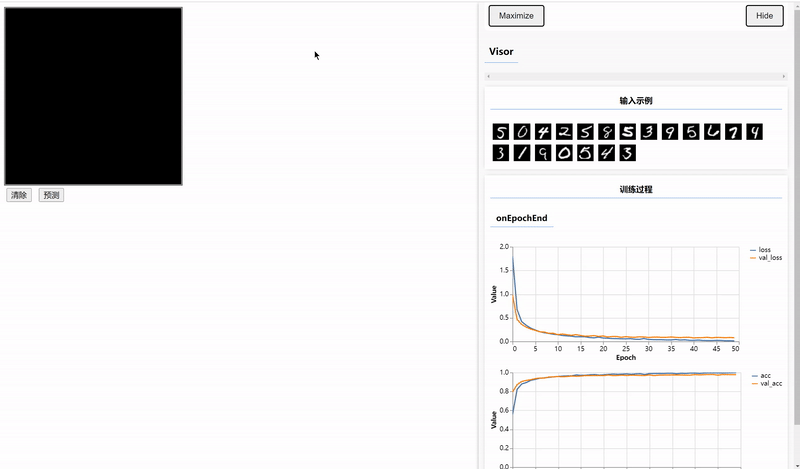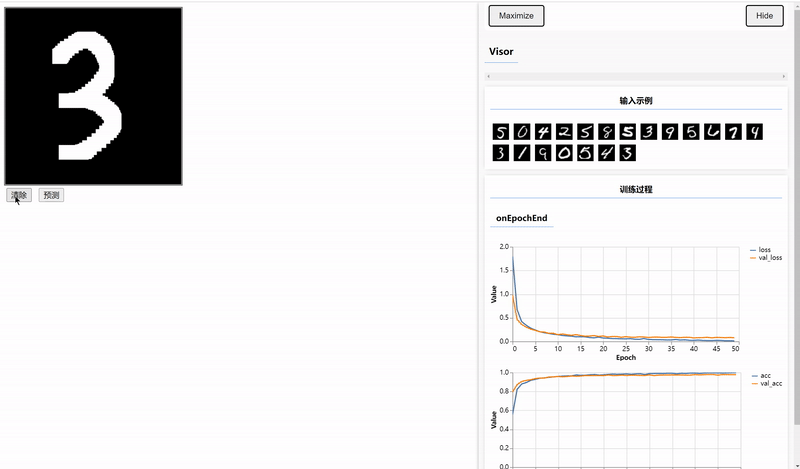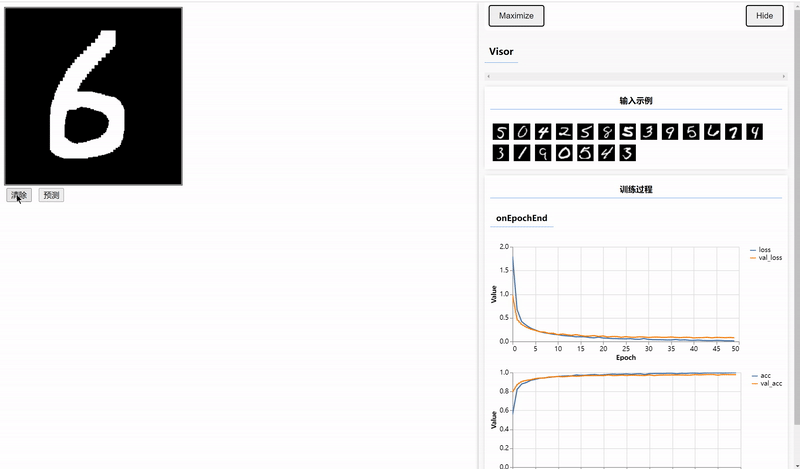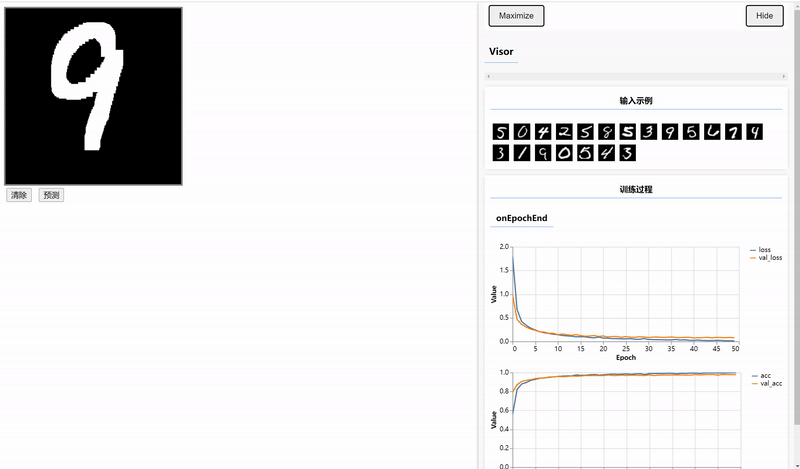
});结果如图,可以看出训练集和验证集的准确率都非常高。

三、使用Canvas绘制数据并预测
编写前端页面输入待预测的数据,需要在index.html文件中编写Canvas容器和设置两个按钮。
<script src="script.js"></script>
<canvas width="300" height="300" style="border: 2px solid #666"></canvas><br>
<button onclick="window.clear();" style="margin:4px">清除</button>
<button onclick="window.predict();" style="margin:4px">预测</button>在script.js文件中实现clear和predict两个方法,由于训练图片是黑底白字的,所以clear方法用于实现每次书写之前,铺一个黑底。
const canvas = document.querySelector('canvas');
// 绑定鼠标事件:按住左键移动绘制线条(利用矩阵连起来书写数字)
canvas.addEventListener("mousemove", (e) => {
if(e.buttons === 1){
const ctx = canvas.getContext('2d');
ctx.fillStyle = 'rgb(255,255,255)',
ctx.fillRect(e.offsetX,e.offsetY,25,25)
}
})
window.clear = () => {
const ctx = canvas.getContext('2d');
ctx.fillStyle = 'rgb(0,0,0)',
ctx.fillRect(0,0,300,300)
}
实训训练好的模型进行预测,将输出的Tensor转为普通的数据并显示。
window.predict = () => {
// 将canvas转换成Tensor,形状是28*28,黑白图片,并归一化
const input = tf.tidy(() => {
return tf.image.resizeBilinear(
tf.browser.fromPixels(canvas),
[28,28],
true,
)
.slice([0,0,0], [28,28,1])
.toFloat()
.div(255)
.reshape([1, 28,28,1])
});
// 预测
const pred = model.predict(input).argMax(1);
alert( `预测结果为:${pred.dataSync()[0]}`)
}结果:
源码:
https://download.csdn.net/download/x_q_x_/87160080