1.安装Docker
docker官网:
http://docs.docker.com/
https://docs.docker.com/engine/install/ubuntu/
1.1 确定系统版本
$ lsb_release -a
1.2 卸载旧版本
$ for pkg in docker.io docker-doc docker-compose podman-docker containerd runc; do sudo apt-get remove $pkg; done
1.3 设置stable镜像仓库
#Update the apt package index and install packages to allow apt to use a repository over HTTPS:
$ sudo apt-get update
$ sudo apt-get install ca-certificates curl gnupg
# Add Docker’s official GPG key:
$ sudo install -m 0755 -d /etc/apt/keyrings
$ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
$ sudo chmod a+r /etc/apt/keyrings/docker.gpg
#Use the following command to set up the repository:
$ echo \
"deb [arch="$(dpkg --print-architecture)" signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu \
"$(. /etc/os-release && echo "$VERSION_CODENAME")" stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
1.4 安装Docker ce
$ sudo apt-get update
$ sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
1.5 测试
$ sudo docker version
$ sudo docker run hello-world
1.6 阿里云镜像加速
登录阿里云开发者平台,点击控制台,选择容器镜像服务,获取加速器地址,粘贴脚本直接执行
$ mkdir -p /etc/docker
$ vim /etc/docker/daemon.json
{
"registry-mirrors": ["https://{自已的阿里云编码}.mirror.aliyuncs.com"]
}
1.7 重启服务器
$ systemctl daemon-reload
$ systemctl restart docker
#测试运行hello-word
$ sudo docker run hello-word
2.安装nvidia-docker
nvidia官网:
https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html
1.Setup the package repository and the GPG key:
$ distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
因为目前还没有nvidia-docker版本支持ubuntu21.04,所以这里的distribution手动设置为20.04,即执行如下命令:
$ distribution=ubuntu20.04 \
...
2.Install the nvidia-container-toolkit package (and dependencies) after updating the package listing:
$ sudo apt-get update
$ sudo apt-get install -y nvidia-container-toolkit
3.Configure the Docker daemon to recognize the NVIDIA Container Runtime:
$ sudo nvidia-ctk runtime configure --runtime=docker
4.Restart the Docker daemon
$ sudo systemctl restart docker
5.测试
$ sudo docker run --rm --runtime=nvidia --gpus all nvidia/cuda:11.0.3-base-ubuntu20.04 nvidia-smi
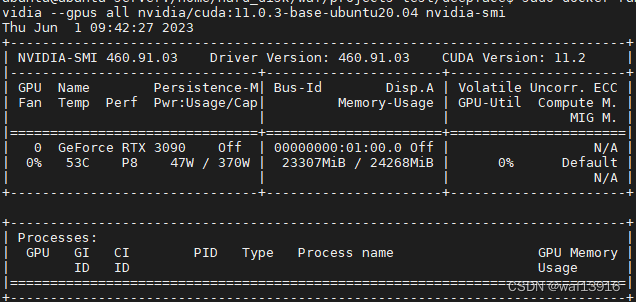
3.cuda11.2+cudnn8.8环境配置
3.1 拉取cuda镜像
根据使用环境,选择对应链接:
cuda
镜像。注意cuda镜像版本需要跟驱动版本一致,否则使用时会报错。
通过命令nvidia-smi查看宿主机CUDA版本为11.2
$ sudo docker pull nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04
3.2 运行容器
# 1.运行容器
$ sudo docker run -d --name mllab --gpus all nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04 /bin/bash
# 2.进入容器
$ sudo docker exec -it mllab bash
# 查看cuda信息
$ nvidia-smi
$ nvcc -V
# 查看cudnn信息,镜像内cudnn版本是8.1
$ sudo find / -name cudnn_version.h
$ cat cudnn_version.h
3.3 apt配置国内源
安装vim
$ apt-get update && apt-get install -y --no-install-recommends vim wget
配置国内源
$ cp /etc/apt/sources.list /etc/apt/sources.list.bak
$ vim /etc/apt/sources.list
$ sudo apt-get update
替换为阿里云
deb http://mirrors.aliyun.com/ubuntu/ focal main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ focal main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ focal-security main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ focal-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ focal-updates main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ focal-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ focal-proposed main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ focal-proposed main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ focal-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ focal-backports main restricted universe multiverse
3.4 更换cudnn
由于deepface要求cudnn版本8.6以上,所以需要替换掉8.1
1.下载cudnn-linux-x86_64-8.8.0.121_cuda11-archive.tar.xz
官网:
https://developer.nvidia.com/rdp/cudnn-archive
- 将压缩文件拷贝到容器内
$ sudo docker cp cudnn-linux-x86_64-8.8.0.121_cuda11-archive.tar.xz 容器ID:容器内路径
3.在容器内解压
$ tar -xvf cudnn-linux-x86_64-8.8.0.121_cuda11-archive.tar.xz
4.cuda配置cudnn
$ mv cudnn-linux-x86_64-8.8.0.121_cuda11-archive/include/* /usr/local/cuda-11.2/include
$ mv cudnn-linux-x86_64-8.8.0.121_cuda11-archive/lib/* /usr/local/cuda-11.2/lib64
$ sudo chmod a+r /usr/local/cuda-11.2/include/cudnn*.h /usr/local/cuda-11.2/lib64/libcudnn*
# 查看cuDNN版本
$ cat /usr/local/cuda-11.2/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
3.5 安装python3.8
$ apt-get install -y --no-install-recommends \
python3 \
python3-pip \
python3-dev \
python3-wheel &&\
cd /usr/local/bin &&\
ln -s /usr/bin/python3 python &&\
ln -s /usr/bin/pip3 pip;
# 更新pip源
# pip升级到最新的版本
$ python -m pip install --upgrade pip
# 修改pip源为清华源
$ pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 或者修改为阿里云的源
# 查看当前 pip 的配置
$ pip config list
# 接着修改配置文件
$ pip config set global.index-url http://mirrors.aliyun.com/pypi/simple/
$ pip config set install.trusted-host mirrors.aliyun.com
3.6 cuda容器生成新镜像
docker commit [-m=“描述信息”] [-a=“作者”] 容器ID 新镜像名:[标签名]
$ docker commit 容器ID waf/image_mllab
4.创建deepface镜像
4.1修改Dockerfile
- 修改基础镜像为新生成的cuda镜像。
- 在Dockerfile文件中添加以下命令来设置时区,这样在构建镜像时就会自动设置时区,解决 Docker build 构建镜像时卡住问题。
RUN ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && echo "Asia/Shanghai" > /etc/timezone
-
配置模型文件路径
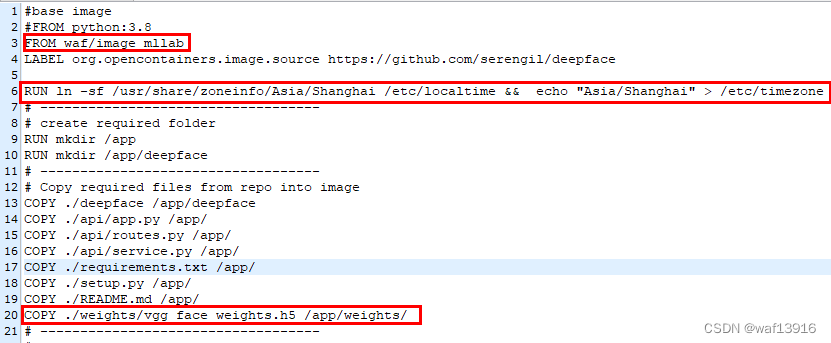
4.2使用GPU环境构建镜像
1.在docker 配置文件/etc/docker/daemon.json 中指定默认的runtime:
{
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
},
"default-runtime": "nvidia" ## 这一步需要添加
}
将默认runtime设定为nvidia后,docker build阶段会默认开启gpu,dockerfile中可以运行需要GPU环境的代码了。构建好的镜像启动容器时,也不需要再指定–gpu。
感觉这个方法不太灵活,毕竟大部分情况下并不需要nvidia的runtime,镜像也不一定要默认使用GPU。如果docker build能像docker run 指定 –gpu参数 那样灵活设置就好了,不知道是不是有这种方法。
2.构建deepface镜像
#进入Dockerfile所在目录执行命令,注意命令最后有个点
$ docker build -t my_deepface .
4.3运行容器
$ sudo docker run -it --name container_deepface -p 192.168.3.56:80:5000 --gpus all my_deepface
测试deepface接口
postman发请求测试
注意:可以通过
docker port 容器ID
查看容器的端口映射
$ sudo docker port 5bde28306e71
5000/tcp -> 192.168.3.56:80
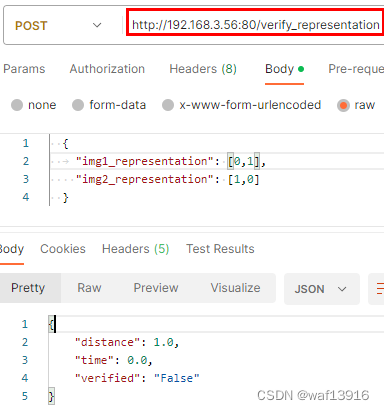
4.4镜像导出成tar包
# docker save -o image.tar 命令用于将 Docker镜像保存到指定文件
$ sudo docker save -o my_deepface.tar my_deepface
4.5导入tar包
# docker load -i imageName.tar 用于从文件载入镜像
$ sudo docker load -i my_deepface.tar
# 运行容器
# 注意在DockerFile中写入的CMD后面的命令不执行主要是因为启动的时候指定了shell,命令末尾不要指定/bin/bash
sudo docker run -it --name container_my_deepface -p 192.168.3.56:80:5000 --gpus all f71edb39a3b1(镜像ID)
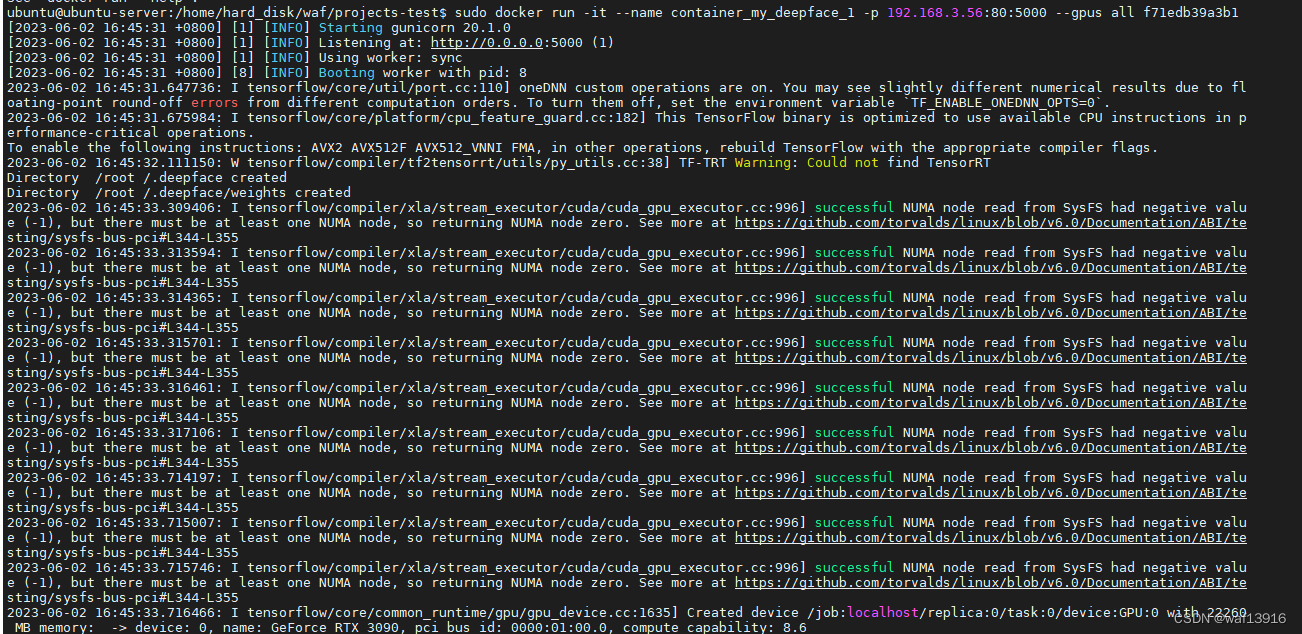
注意:
使用docker load -i 命令之后,镜像的名字和标签都是none,这个问题的根本在于这个镜像压缩包在打包的时候操作不当所导致。
例如,使用镜像ID打包的话导致解压的出来的镜像没有名字。因此,推荐使用镜像的名字进行打包,例如:
docker save -o redis.tar redis:5.0.2
常用命令
#导出镜像到本地
#把镜像名为test,版本为4.0的docker镜像,保存到/data/export目录下,保存名字和格式为test.tar
docker save -o /data/export/test.tar test:4.0
#导入之前导出的镜像
#其中 -i 表示从文件输入。会成功导入镜像及相关元数据,包括tag信息
docker load -i xxx.tar
#重命名
docker tag [镜像id] [新镜像名称]:[新镜像标签]
4.6查看容器日志
(1)docker logs –tail=1000 容器名称 (查看容器前多少行的日志)(推荐)
(2)docker 容器启动后,可以进入以下位置查看日志(/var/lib/docker/containers/容器ID/容器ID-json.log)(进入容器内部查看日志)
4.7error排查
醒目部署后,运行其他AI项目时报错:
cudnn.hpp:74: error: (-217:Gpu API call) CUDNN_STATUS_NOT_INITIALIZED in function 'UniqueHandle'
是因为tensorflow-gpu运行程序默认是把GPU的内存全部占满的,可以设置参数来修改显存使用情况。
解决代码:
import tensorflow as tf
import os
os.environ['CUDA_VISIBLE_DEVICES']="0" # 指定哪块GPU训练
config=tf.compat.v1.ConfigProto()
#设置使用显存比例,设置最大占有GPU不超过显存的80%(可选)
config.gpu_options.per_process_gpu_memory_fraction=0.8
config.gpu_options.allow_growth = True # 设置动态分配GPU内存
sess=tf.compat.v1.Session(config=config)