Pandas 是python进行数据处理的一种工具包,里面默认的数据结构为Dataframe,
具有非常良好的易用性,可以非常方便的进行一些数据统计与分析的工作,以下我将和大家分享Dataframe常用的一些操作,掌握了这些操作,便基本可以使用pandas进行数据处理与分析了。
首先,我们使用pandas来创建一个5行3列的Dataframe,我们可以借助numpy生成一个随机的矩阵,然后直接转换为Dataframe类型数据,也可以使用pandas读取CAV或者excel文件,读取之后便可以得到一个Dataframe类型的数据。
import pandas as pd
import numpy as np
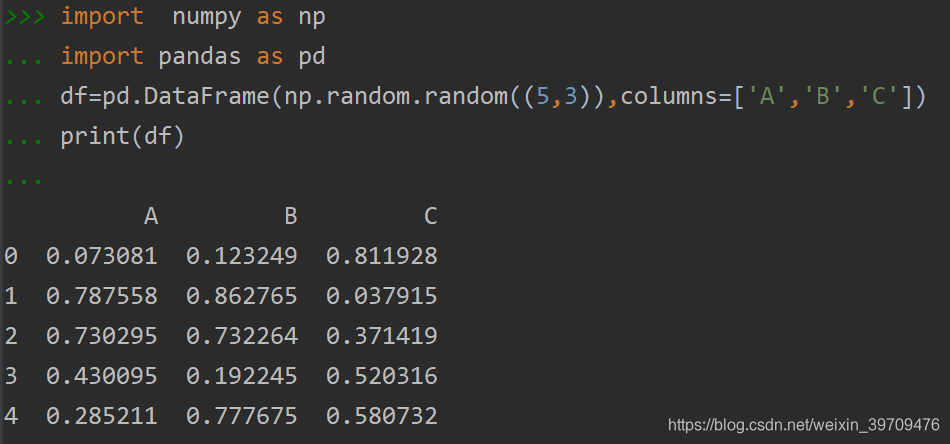
df=pd.DataFrame(np.random.random((5,3)),columns=['A','B','C'])至此我们便得到了一个五行三列的dataframe,列标分别为‘A’,‘B’,‘C’。
将数据打印如下:
在数据处理中,我们经常会用到按条件筛选数据,例如我们想选择第A列大于0.5的所有行,我们可以使用如下代码:
df[df['A']>0.5]我们可以看到以下输出:

如果我们想按照多个条件进行筛选,例如选择A列或者B列大于0.5的数据,可以使用如下代码:
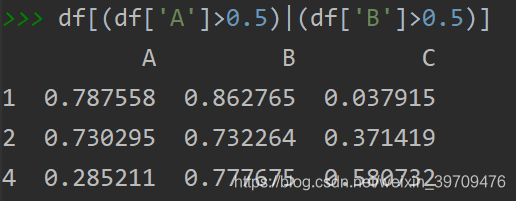
如果想按照“且”的关系进行筛选,只需要将 “|” 符号替换为“&”。
若是想要将某一列设置为索引,可以使用如下代码:
df.set_index('A',inplace=True) #将‘A’列设定为index,inplace=True代表直接在原数据上进行修改
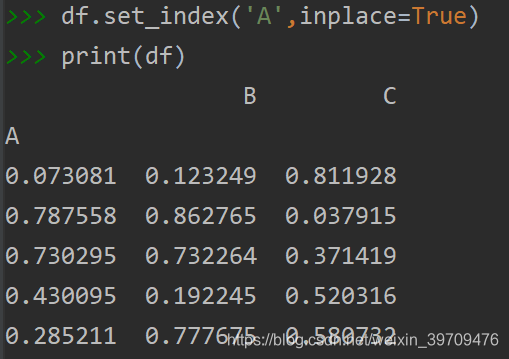
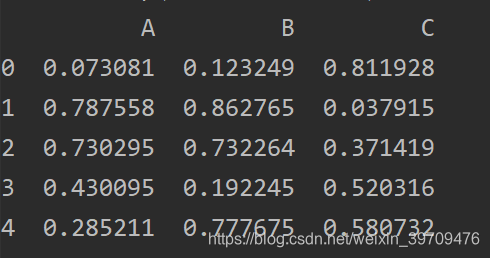
这时我们可以看到第A列已经成为了索引。此时如果我们想恢复原先的索引,我们可以使用如下代码:
df.reset_index(drop=False,inplace=True) #重新设定0-n的索引,保留原来的索引
如果我们想取某几行,可以使用如下的索引方式:
df.iloc[2:5]['A'] # 通过行号索引数据选取二到五行,第A列的数据
df.loc[2:5]['A'] # 通过行标签索引数据
df.ix[2:5]['A'] # loc与iloc的综合,可以混用
df.ix['a':'c',:] #
df.loc[:, df.loc['a']>0] # a行大于0的所有列
如果想精确定位某个位置的值,可采用如下方法:
df.at['a','A'] #按照行索引列索引精确定位
df.iat[1,1] #按照行号列号精确定位
如果想删除某一行或者某一列:
#删除某一行 axis=0
df.drop('a',axis=0, inplace=True)
#删除某一列 axis=1
df.drop('A',axis=1,inplace=True)
如果想将两个dataframe按照某一列进行关联,可采用如下方式:
joined_data=pd.merge(df1,df2,how='left',left_on='df1_column_name',right_on='df2_column_name')
至此,Dataframe的常用方法便介绍完毕了,如果有什么新的使用方法,欢迎大家留言交流。