- 有些网站为了避免被过度访问,会设置验证码反爬机制,如果访问次数过多就要求用户输入验证码,甚至一开始访问就要求输入验证码。验证码的类型很多,本章会讲解其中常见的图像验证码、计算题验证码、滑块验证码、滑块拼图验证码、点选验证码。
- 设置了验证码反爬机制的网站通常不希望被爬虫过度爬取,有的网站还会经常更换验证码类型,因此,本章主要使用专门搭建的本地网页(HTML文件)来讲解如何应对验证码反爬。
注意:本章介绍的方法仅针对单纯的验证码反爬。有些网站除了验证码反爬,还会采用其他反爬手段(如针对Selenium和webdriver拦截),此时本章介绍的方法就会失效。
-
图像验证码是最常见的验证码类型,主要分为英文验证码和中文验证码。英文验证码的内容结合了英文字母和数字(见左下图),中文验证码的内容以简体汉字为主(见右下图)。

- 因为超级鹰的识别效果最好,且实战中应用最为有效,所以这里主要讲解使用的超级鹰识别验证码的方法。百度的文字识别接口则在2.1.3节的“补充知识点”中进行简单介绍。至于PyTesseract库,虽然免费,但是安装较为繁琐,而且识别效果很一般,所以本书不予讲解。
2.1.1 超级鹰平台注册
-
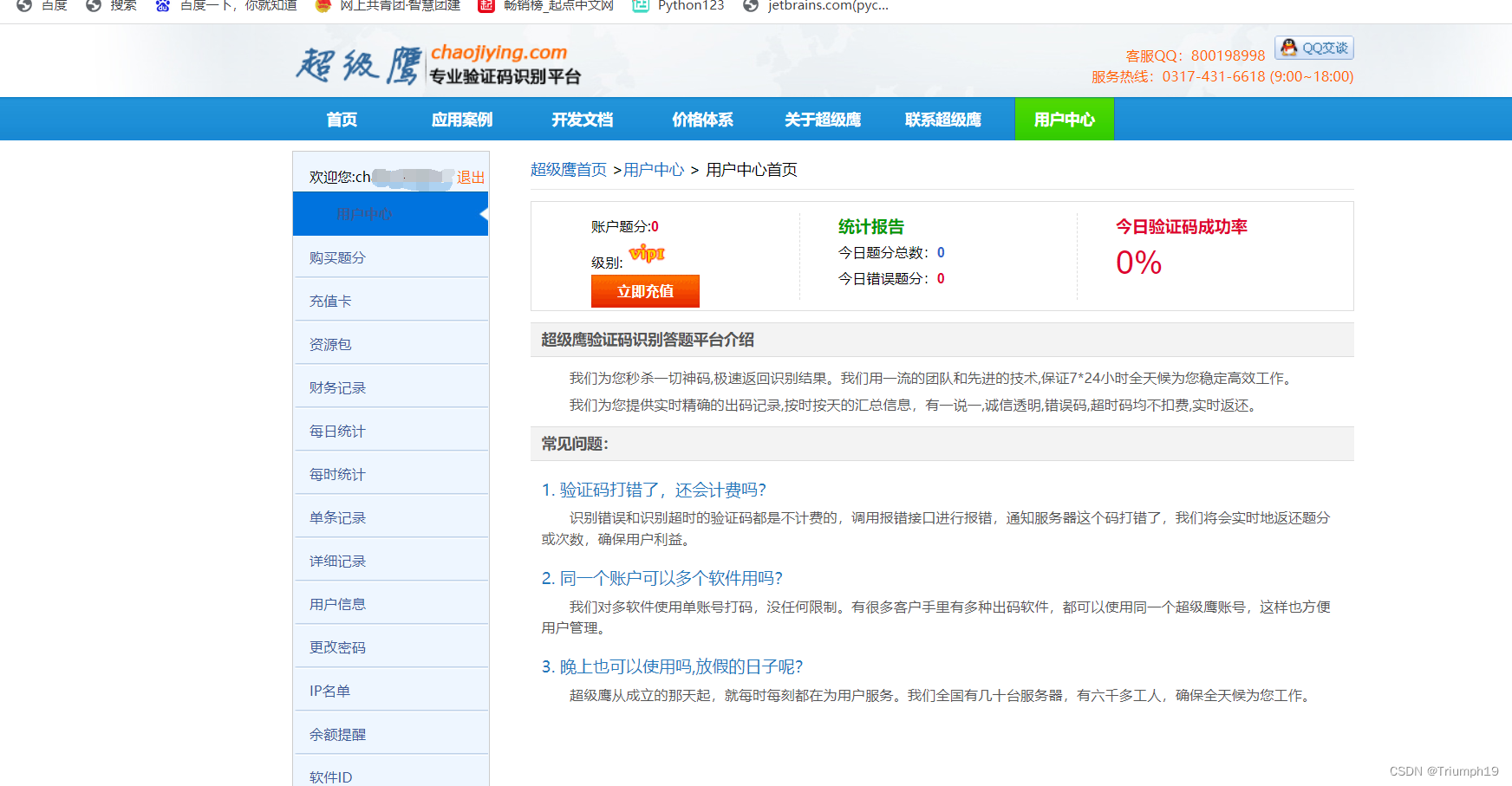
超级鹰的官方网站为http://www.chaojiying.com/,可以在页面右上角进行注册。注册并登录后进入用户中心,按照页面右下角的提示扫码二维码绑定微信,可领域超级鹰送给用户的1000题分(题分就是积分),如下图所示。
-
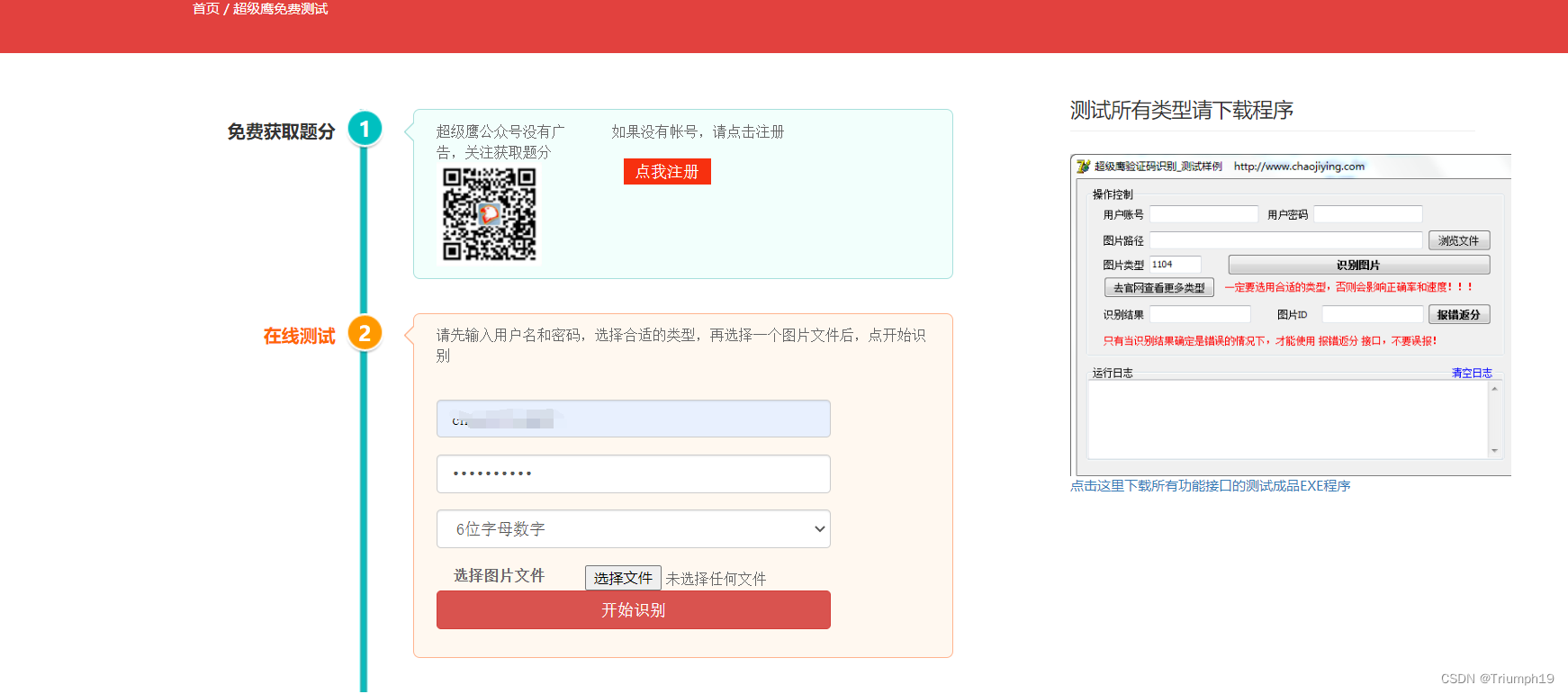
随后便可用赠送的题分在免费测试页面(https://www.chaojiying.com/demo.html)进行测试。如下图所示。读者可自行搜索一些图像验证码或者利用本书提供的HTML文件进行测试。
2.1.2 超级鹰Python接口的使用
-
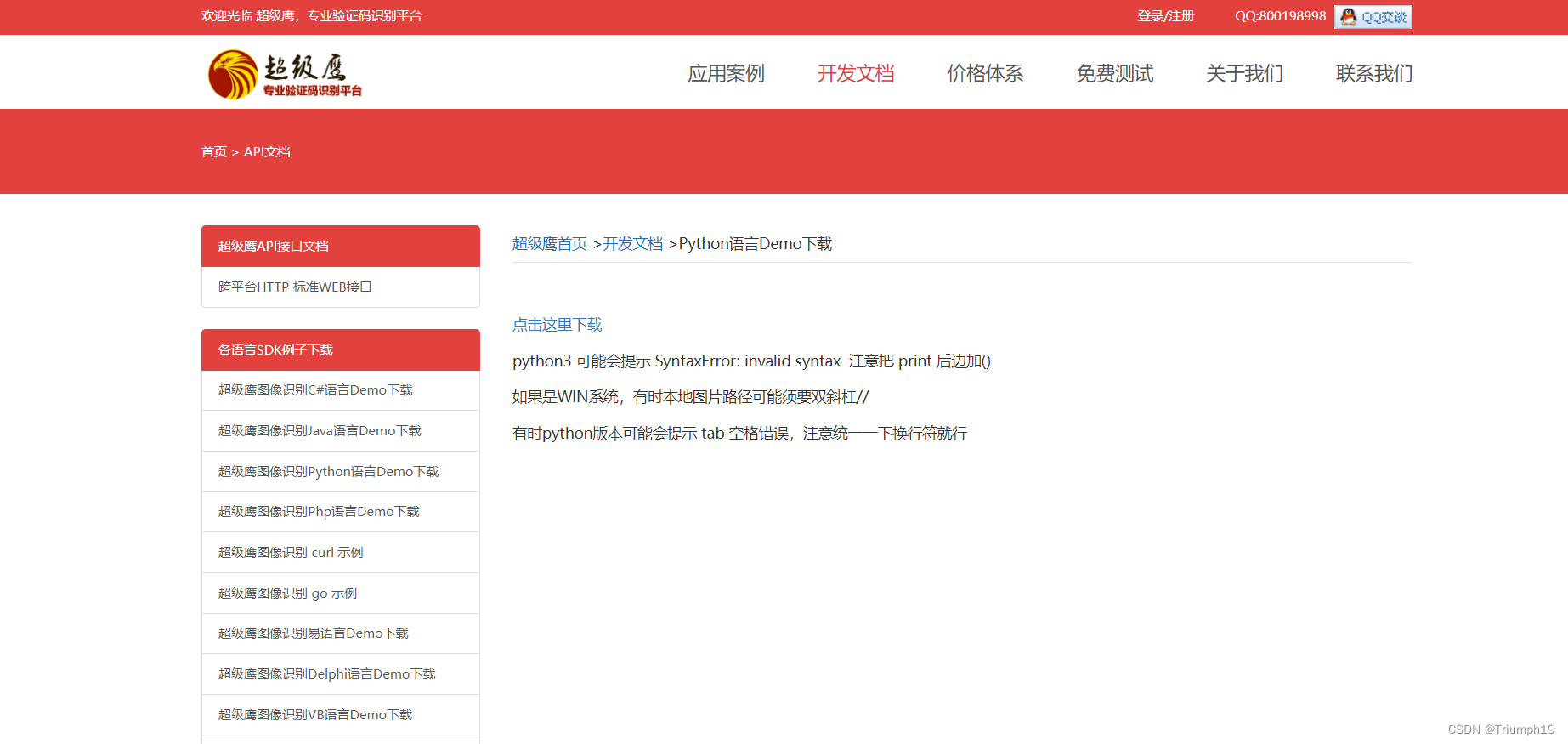
打开超级鹰的Python开发文档页面(https://www.chaojiying.com/api-14.html),单击链接下载官方提供的实例代码,如下图所示。该代码是基于Python 2 编写的,而我们现在使用的通常是Python 3,因此,需要根据页面中的说明修改代码。例如,Python 2 的print()函数没有括号,所以要在Print后加括号,此外还需要把一些不规范的缩进文件改为规范的【Tab】键缩进。不愿意自己修改代码的读者可以直接从本书的配套文件中下载本书作者修改好的代码。
-
下载得到一个压缩包,解压后如下图所示。
- 修改后的代码如下,读者简单浏览即可,不需要理解其含义,代码的使用方法并不难,后续会讲解。
import requests
from hashlib import md5
class Chaojiying_Client(object):
def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def PostPic(self, im, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)
return r.json()
def ReportError(self, im_id):
"""
im_id:报错题目的图片ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
-
随后需要将修改好的“chaojiying.py”复制到用于识别图像验证码的代码文件所在的文件夹中,如右图所示。其中“a.png”是要用识别的图像验证码,“test.py”是用于识别图像验证码的代码文件。
- “test.py”代码内容如下:
from chaojiying import Chaojiying_Client
def cjy(): #使用超级鹰识别图像验证码的自定义函数
chaojiying = Chaojiying_Client('超级鹰用户名', '超级鹰用户名的密码', '软件ID') # 用户中心>>软件ID
im = open('a.jpg', 'rb').read() # 打开本地图片文件,有时WIN系统须要//
code = chaojiying.PostPic(im,1902)
return code
result = cjy() #调用函数识别验证码,并将识别结果赋给变量result
print(result) #打印输出识别结果
- 第1行代码从“chaojiying.py”文件中引用Chaojiying_Client类,这是从库中引用类的固定写法,之前也接触过,如from selenium import webdriver。
- 第3行定义了一个cjy()函数,以方便后续调用。
-
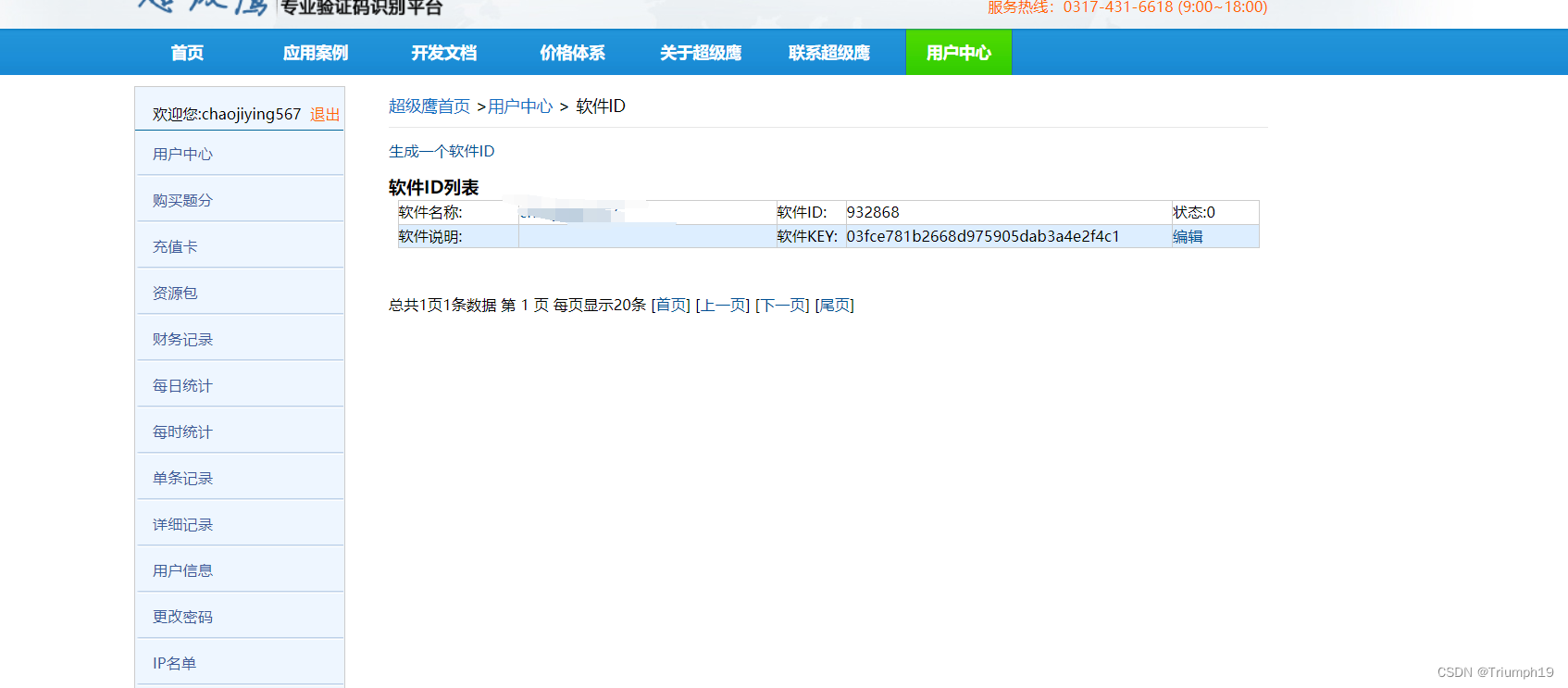
第4行代码需要传入超级鹰账号、密码和软件ID。账号和密码就是前面注册超级鹰时填写的账号和密码,软件ID则需要到超级鹰的用户中心去生成。如下图所示,在浏览器中打开超级鹰的用户中心,(1)单击左下方的“软件ID”链接,(2)在右侧单击“生成一个软件ID”链接,(3)然后选中并复制生成的软件ID,粘贴到代码中的响应位置即可。
- 第5行用于打开本地的验证码图片文件,这里的“a.jpg”是一个相对路径(即代码文件所在的文件夹),可以根据实际需要更改成其他路径。

{'err_no': 0, 'err_str': 'OK', 'pic_id': '9176320570859320003', 'pic_str': '7261', 'md5': '98ec31bc733845e88d61bd3b49d52519'}
-
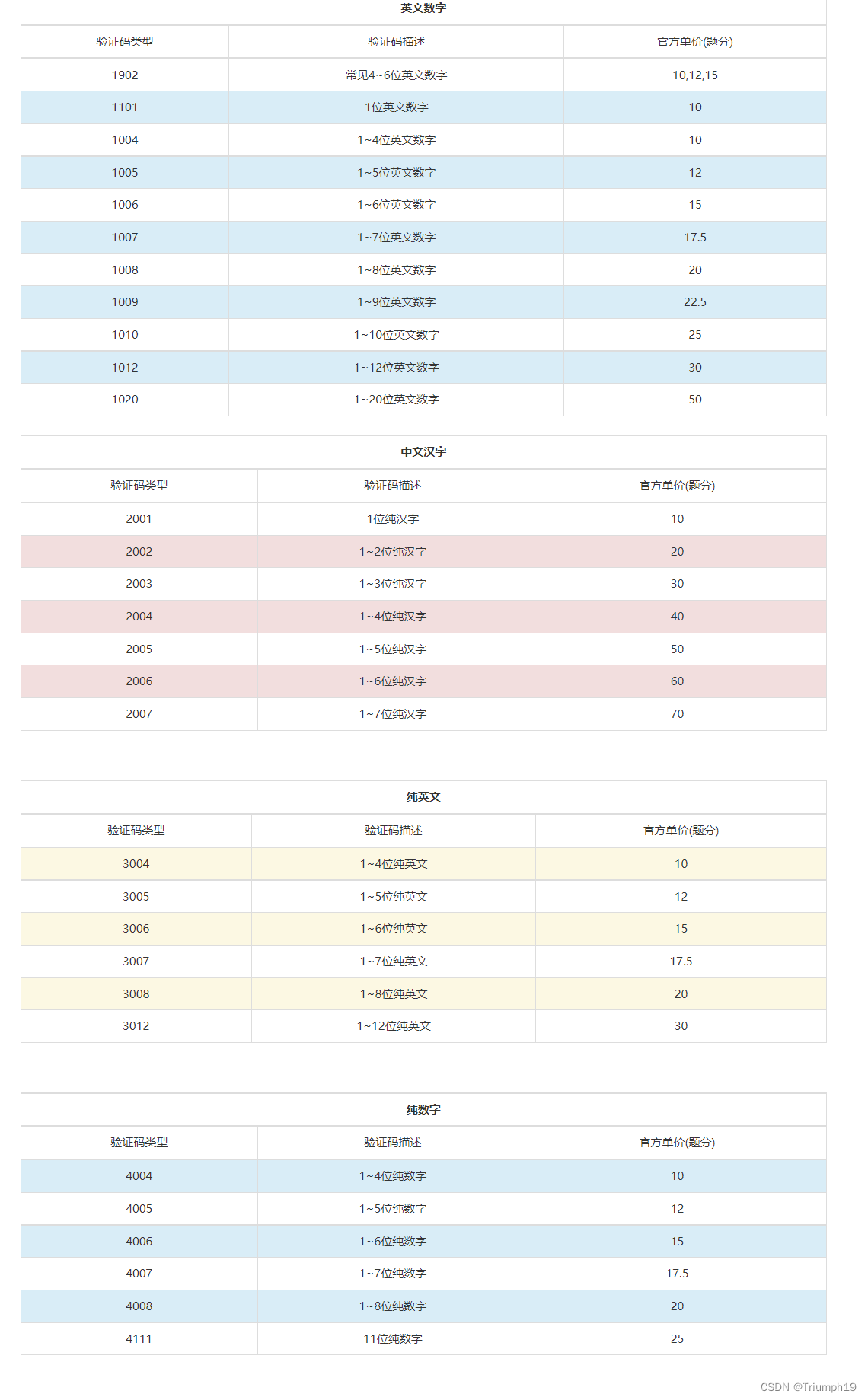
不同的验证码类型需要使用不同的编号参数,具体见https://www.chaojiying.com/price.html,如下图所示。这里要识别的“a.png”是一个4位的英文验证码,查表可知1902、1004等都适用,这里使用官方推荐的1902,速度比1004快。此外,在选择时还需要注意仔细于都收费标准。

2.1.3 案例实战:英文验证码和中那位验证码识别
- 前面用一个单独的图片文件讲解了如何使用超级鹰识别验证码,那么对于网页中的验证码又该如何操作呢?本级将使用作者自己搭建的本地网页作为处理对象,用超级鹰完成英文验证码和中文验证码的识别,实际网站的验证码识别案例可以参考1.3.1 节。
1.英文验证码识别
-
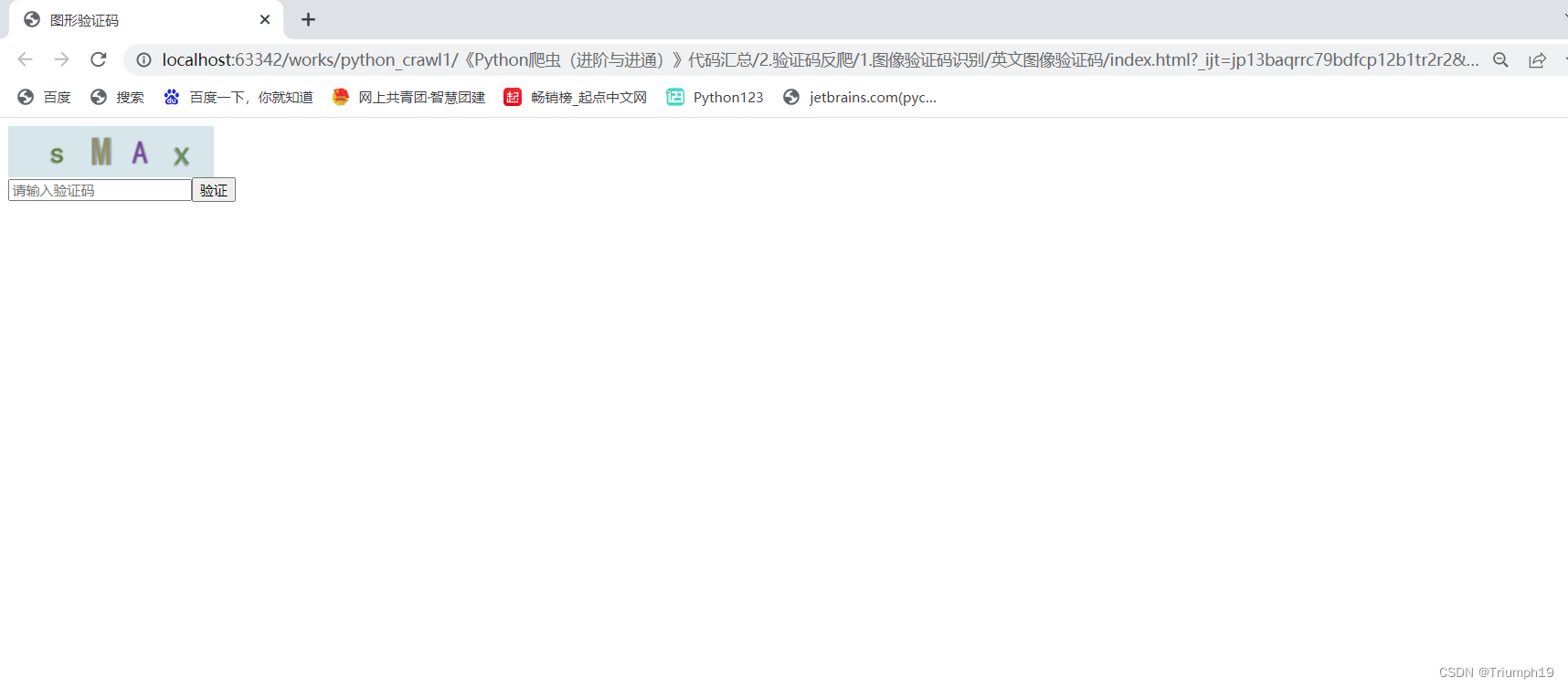
首先要把“chaojiying.py”文件复制到编写的文件夹中。该文件中的“index.html”文件就是事先搭建好的本地网页,在浏览器中打开该文件,效果如下图所示。可以看到网页中有一个英文验证码图片、一个验证码输入框和一个“验证”按钮,地址栏中显示的则是这个本地网页的文件路径。
-
接着来编写代码。识别网页中图像验证码的常规操作步骤如下:
(1)用selenium库打开网页
(2)用selenium库的screeshot()函数截取验证码图片;
(3)用cjy()函数识别图像内容;
(4)用Selenium库模拟输入验证码,再模拟单击“验证”按钮。 - 根据上述步骤,先导入Selenium库并打开网页,代码如下:
from selenium import webdriver
browser = webdriver.Chrome()
url = r'D:\works\python_crawl1\《Python爬虫(进阶与进通)》代码汇总\2.验证码反爬\1.图像验证码识别\英文图像验证码\index.html'
browser.get(url) #用模拟浏览器打开网页
-
需要注意的是,第3行代码中的网址必须是网页文件的绝对路径,虽然Python可以识别相对路径,但是浏览器只能识别绝对路径下的网页文件。
- 然后用XPath表达式定位验证码,再用screenshot()函数保存为图片文件。用复制的XPath表达式编写出如下代码:
browser.find_element_by_xpath('//*[@id="verifyCanvas"]').screenshot('a.png') #a.png是自己命令的图片名称
注意:用screeshot()函数保存图片文件时使用的路径需与cjy()函数中打开图片文件时的使用的路径保持一致。如果在这里修改了文件路径,则要相应修改cjy()函数中的文件路径。
- 接着定义cjy()函数,相关代码在2.1.2节已经讲过,具体如下:
from chaojiying import Chaojiying_Client
def cjy(): #使用超级鹰识别图像验证码的自定义函数
chaojiying = Chaojiying_Client('超级鹰用户名', '超级鹰用户名的密码', '软件ID') # 用户中心>>软件ID
im = open('a.png', 'rb').read() # 打开本地图片文件,有时WIN系统须要//
code = chaojiying.PostPic(im,1902)['pic_str']
return code
- 有了cjy()函数后,通过如下代码即可获得识别结果:
result = cjy() #调用函数识别验证码,并将识别结果赋给变量result
- 一旦获得识别结果,就可通过Selenium库模拟键盘和鼠标操作,输入验证码并单击“验证”按钮,完成验证,代码如下:
browser.find_element_by_xpath('//*[@id="code_input"]').send_keys(result) #模拟输入验证码
browser.find_element_by_xpath('//*[@id="my_button"]').click() #模拟单击"验证"按钮
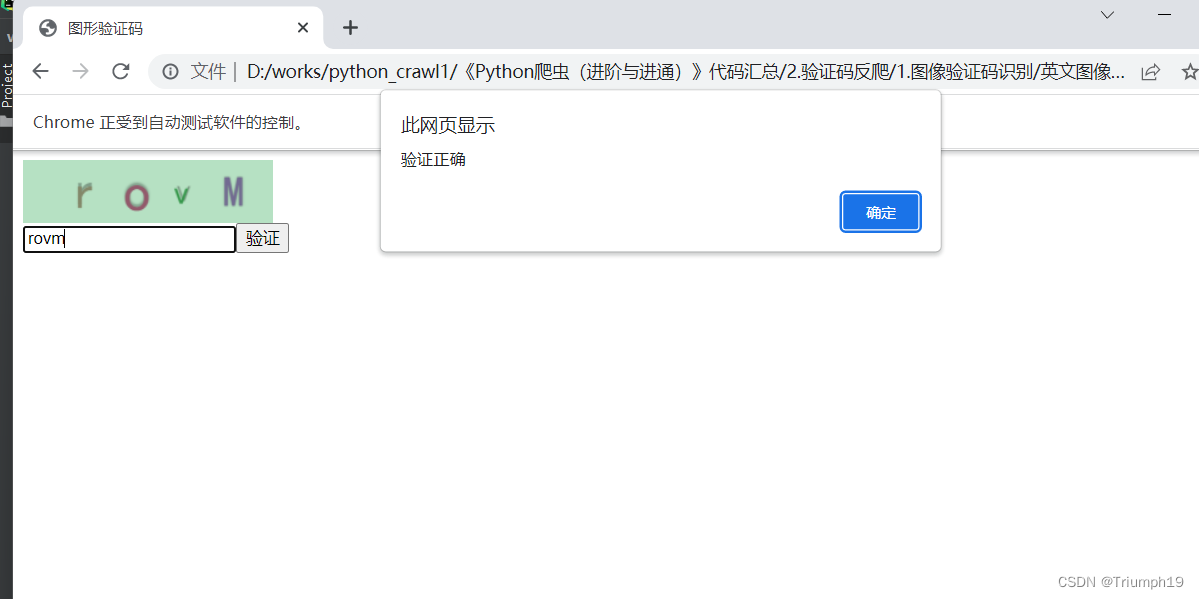
- 完整代码如下:
from selenium import webdriver
browser = webdriver.Chrome()
from chaojiying import Chaojiying_Client
def cjy(): #使用超级鹰识别图像验证码的自定义函数
chaojiying = Chaojiying_Client('超级鹰用户名', '超级鹰用户名的密码', '软件ID') # 用户中心>>软件ID
im = open('a.png', 'rb').read() # 打开本地图片文件,有时WIN系统须要//
code = chaojiying.PostPic(im,1902)['pic_str']
return code
#1.访问网址
url = r'D:\works\python_crawl1\《Python爬虫(进阶与进通)》代码汇总\2.验证码反爬\1.图像验证码识别\英文图像验证码\index.html'
browser.get(url) #用模拟浏览器打开网页
#2. 截取验证码图片
browser.find_element_by_xpath('//*[@id="verifyCanvas"]').screenshot('a.png') #a.png是自己命令的图片名称
#3.通过超级鹰识别
result = cjy() #调用函数识别验证码,并将识别结果赋给变量result
print(result) #打印输出识别结果
# 4.输入验证码并完成验证
browser.find_element_by_xpath('//*[@id="code_input"]').send_keys(result) #模拟输入验证码
browser.find_element_by_xpath('//*[@id="my_button"]').click() #模拟单击"验证"按钮
技巧:每个读者保存的代码的位置可能都不一样,上述代码中绝对路径需要根据实际情况修改。因为这里是将网页文件和代码文件放在同一文件夹下,所以也可以在代码中自动获取文件所在文件的路径,再拼接网页文件的文件名,得到网页文件的绝对路径,这样就不用手动修改网页文件的绝对路径了。代码如下:
2.中文验证码识别
- 中文验证码识别方法和英文验证码的识别方法基本一致,唯一需要修改的就是自定义函数cjy()的代码中PosPic()函数的第2个参数,将原先用于识别英文验证码的1902接口改成2004(详见https://www.chaojiying.com/price.html)。修改后的cjy()函数代码如下:
def cjy(): #使用超级鹰识别图像验证码的自定义函数
chaojiying = Chaojiying_Client('超级鹰用户名', '超级鹰用户名的密码', '软件ID') # 用户中心>>软件ID
im = open('a.png', 'rb').read() # 打开本地图片文件,有时WIN系统须要//
code = chaojiying.PostPic(im,2004)['pic_str']
return code
- 总体来说,超级鹰可以识别大部分图像验证码。对于一些网页中使用的将网页文本转换成图片的反爬方式,也可以用超级鹰来识别图片,从而爬取文本。
补充知识点:基于百度接口的Python图像文字识别(OCR)
版权声明:本文为Triumph19原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。