目录
一、生活背景
垃圾邮件的问题一直困扰着人们,传统的垃圾邮件分类的方法主要有”关键词法”和”校验码法”等,然而这两种方法效果并不理想。其中,如果使用的是“关键词”法,垃圾邮件中如果这个关键词被拆开则可能识别不了,比如,“中奖”如果被拆成“中 — 奖”可能会识别不了。后来,直到提出了使用“贝叶斯”的方法才使得垃圾邮件的分类达到一个较好的效果,而且随着邮件数目越来越多,贝叶斯分类的效果会更加好。
我们想采用的分类方法是通过多个词来判断是否为垃圾邮件,但这个概率难以估计,通过贝叶斯公式,可以转化为求垃圾邮件中这些词出现的概率。
二、朴素贝叶斯法概述
朴素贝叶斯法是基于贝叶斯定理与特征条件独立性假设的分类方法。对于给定的训练集,首先基于特征条件独立假设学习输入输出的联合概率分布(朴素贝叶斯法这种通过学习得到模型的机制,显然属于生成模型);然后基于此模型,对给定的输入 x,利用贝叶斯定理求出后验概率最大的输出 y。
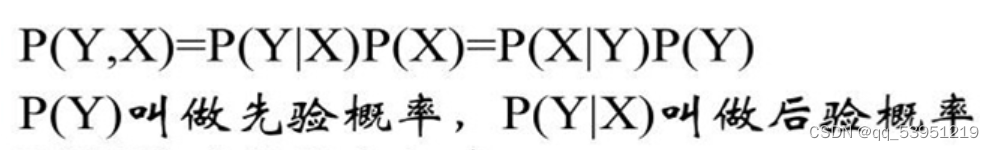
![]()
我们要做的是计算在已知
词向量
w=(w1,w2,…,wn)w=(w1,w2,…,wn)的条件下求包含该词向量邮件是否为垃圾邮件的概率,即求(s为垃圾邮件):
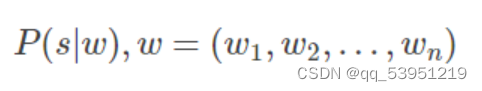
优点:在数据较少的情况下仍然有效,可以处理多类别问题。
缺点:对于输入数据的准备方式较为敏感。
适用数据类型:标称型数据。
三、收集垃圾邮件
代码
def spamTest():
docList = []; classList = []; fullText = []
for i in range(1, 26):
# 读取每个垃圾邮件,并字符串转换成字符串列表
wordList = textParse(open('email/spam/%d.txt' % i, 'r').read())
print(i," ",wordList)
docList.append(wordList)
fullText.append(wordList)
# 标记垃圾邮件,1表示垃圾文件
classList.append(1)
print(i," ",classList)
# 读取每个非垃圾邮件,并字符串转换成字符串列表
wordList = textParse(open('email/ham/%d.txt' % i, 'r').read())
print(i, " ", wordList)
docList.append(wordList)
fullText.append(wordList)
# 标记非垃圾邮件,0表示非垃圾文件
classList.append(0)
# 创建词汇表,不重复
vocabList = createVocabList(docList)
trainingSet = list(range(50)); testSet = []
print("trainingSet",trainingSet)
for i in range(10):
randIndex = int(random.uniform(0, len(trainingSet)))
testSet.append(trainingSet[randIndex])
del(trainingSet[randIndex])
trainMat = []; trainClasses = []
# 遍历训练集
for docIndex in trainingSet:
# 将生成的词集模型添加到训练矩阵中
trainMat.append(setOfWords2Vec(vocabList, docList[docIndex]))
# 将类别添加到训练集类别标签系向量中
trainClasses.append(classList[docIndex])
# 训练朴素贝叶斯模型
p0V, p1V, pSpam = trainNB0(np.array(trainMat), np.array(trainClasses))
errorCount = 0
# 遍历测试集
for docIndex in testSet:
wordVector = setOfWords2Vec(vocabList, docList[docIndex])
if classifyNB(np.array(wordVector), p0V, p1V, pSpam) != classList[docIndex]:
errorCount += 1
print("分类错误的测试集:",docList[docIndex])
print('错误率:%.2f%%' % (float(errorCount) / len(testSet) * 100))
总结
朴素贝叶斯的优点和缺点
优点:
对待预测样本进行预测,过程简单速度快(想想邮件分类的问题,预测就是分词后进行概率乘积,在log域直接做加法更快)。
对于多分类问题也同样很有效,复杂度也不会有大程度上升。
在分布独立这个假设成立的情况下,贝叶斯分类器效果奇好,会略胜于逻辑回归,同时我们需要的样本量也更少一点。
对于类别类的输入特征变量,效果非常好。对于数值型变量特征,我们是默认它符合正态分布的。
缺点:
对于测试集中的一个类别变量特征,如果在训练集里没见过,直接算的话概率就是0了,预测功能就失效了。当然,我们前面的文章提过我们有一种技术叫做『平滑』操作,可以缓解这个问题,最常见的平滑技术是拉普拉斯估测。
那个…咳咳,朴素贝叶斯算出的概率结果,比较大小还凑合,实际物理含义…恩,别太当真。
朴素贝叶斯有分布独立的假设前提,而现实生活中这些predictor很难是完全独立的。