搭建Spark On Yarn 集群
一、搭建Spark Standalone集群
-
参看《
搭建SecureDRT
》 -
修改Spark环境配置文件
(1)Spark On YARN模式的搭建比较简单,仅需要在YARN集群的一个节点上安装Spark即可,该节点可作为提交Spark应用程序到YARN集群的客户端。Spark本身的Master节点和Worker节点不需要启动。
(2)使用此模式需要修改Spark配置文件
spark-env.sh
,添加Hadoop相关属性,指定Hadoop与配置文件所在目录

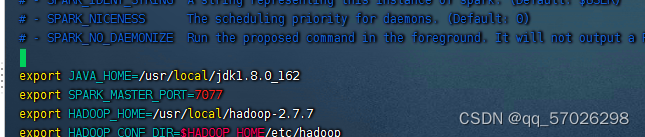
export JAVA_HOME=/usr/local/jdk1.8.0_162
export SPARK_MASTER_HOST=master
export SPARK_MASTER_PORT=7077
export HADOOP_HOME=/usr/local/hadoop-2.7.7
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
3.存盘退出后,执行命令:
source spark-env.sh
,让配置生效

二、提交Spark应用到集群运行
-
启动HDFS和YARN
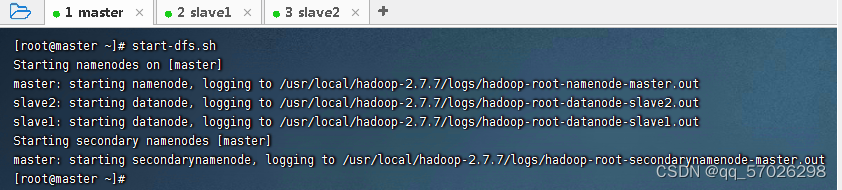
(1)执行命令:
start-dfs.sh
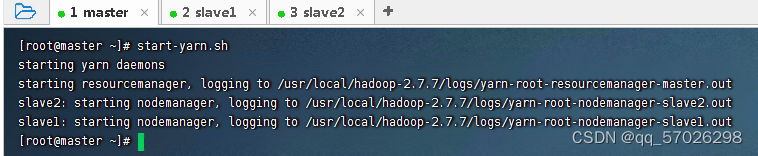
(2)执行命令:
start-yarn.sh
-
运行Spark应用程序
(1)查看Spark应用程序
$SPARK_HOME/examples/jars/spark-examples_2.11-2.1.1.jar

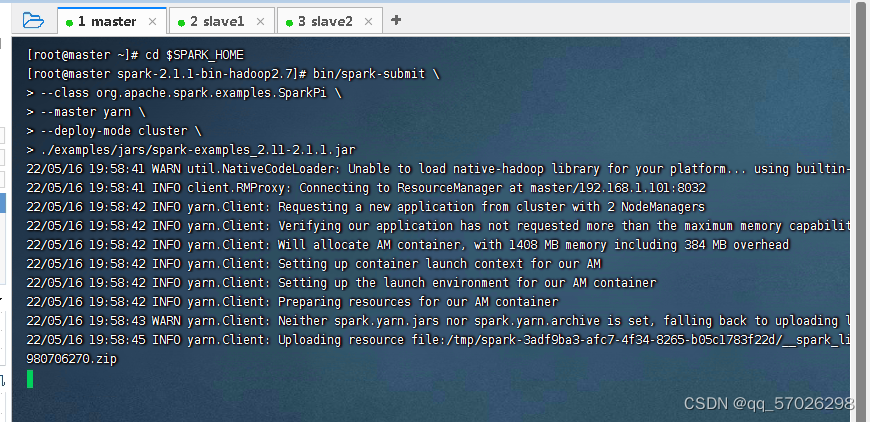
(2)进入Spark安装目录,执行命令:
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_2.11-2.1.1.jar

(3)通过浏览器来访问
yarn
和
webUI

(4)单击
Logs
超链接,再单击**stdout:Total file length is 33 bytes.**超链接,即可查看到Spark应用的运行结果
版权声明:本文为qq_57026298原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。