1. DML语言
数据库存在的意义:
数据存储 、数据管理
DML((Data Manipulation Language))语言:
作为SQL的分类之一,该命令能够使用户查询数据库以及操作已有数据库中的数据的计算机语言。主要用于操作数据库对象中所包含的数据,是一种数据操作语言。
DML分成交互型DML和嵌入型DML两类:
-
交互型DML
:这类DML自成系统,可在终端上直接对数据库进行操作。 -
嵌入型DML
:这类DML是嵌入在主语言中使用。此时主语言是经过扩充能处理DML语句的语言。
依据语言的级别,DML又可分成过程性DML和非过程性DML两种:
-
过程性DML
:用户编程时,不仅需要指出“做什么”(需要什么样的数据),还需要指出“怎么做”(怎么获得数据),层状、网状的DML属于过程性语言。 -
非过程性DML
:用户编程时,只需要指出“做什么”,不需要指出“怎么做”,关系型DML属于非过程性语言。
主要包括:添加数据(INSERT)、删除数据(DELETE)、修改数据(UPDATE)
1.1 插入(insert)
语法:insert into
表名
(
字段名1
,
字段名2
,…) values(‘值1′,’值2’,…),(‘值1′,’值2’,…),…
注意:
插入全部字段时,可省略表名后的字段名
-- 语法:insert into `表名`(`字段名1`,`字段名2`,...) values('值1','值2',...),('值1','值2',...),...
-- 指定字段插入数据
-- insert into `表名`(`字段名1`,`字段名2`,...) values('值1','值2',...)
INSERT INTO `grade`(`gradename`)VALUES('大四')
-- 如果不写表的字段,它就会一一匹配,此时所有字段值都必须写全,主键值不能省略
INSERT INTO `grade`VALUES('研一') -- 报错
INSERT INTO `grade`VALUES(5,'研二') -- 成功
-- 一般写插入语句,我们一定要使数据和字段一一对应!
-- 插入一个字段多个值,主键自增可以忽略
INSERT INTO `grade`(`gradename`)VALUES('大三'),('大二')
INSERT INTO `student`(`name`)VALUES('赵四') -- 一次插入一个字段
INSERT INTO `student`(`name`,`pwd`,`sex`)VALUES('张三','111111','男') -- 一次插入多个字段
-- 插入除主键外的所有字段,此时要写出所有字段名,不可省略字段名
INSERT INTO `student`(`name`,`pwd`,`sex`,`birthday`,`gradeid`,`address`,`email`)
VALUES('王五','222222','男','2020-02-02','3','吉林','111@163.com'),
('小黄','222222','男','2020-02-02','3','吉林','111@163.com'),
('小红','222222','男','2020-02-02','3','吉林','111@163.com')
-- 插入全部字段(包括了主键),此时可省略全部字段名
INSERT INTO `student`VALUES
(4,'王七','333333','男','2000-01-01','8','黑龙江','222@qq.com')
-- 插入全部字段的多条数据,此时可忽略字段名
INSERT INTO `student`VALUES
(5,'1','1','男','2001-01-01','11','1','1@qq.com'),
(6,'2','1','男','2002-01-01','12','1','2@qq.com'),
(7,'3','1','男','2003-01-01','13','1','3@qq.com'),
(8,'4','1','男','2004-01-01','14','1','4@qq.com'),
(9,'5','1','男','2005-01-01','15','1','5@qq.com'),
(10,'6','1','男','2006-01-01','16','1','6@qq.com')
注意事项:
-
字段和字段之间用英文“,”隔开
-
字段是可以省略的,但是后面的值要一一对应,不能少,字段都省略时,主键值就不能忽略
-
可以同时插入多条数据,values后面的值需要使用“,”隔开
-
每写完一条sql指令,最好后面加上一个“;”,这样在执行值更加明确减少报错
1.2 修改(update)
语法:update
表名
set
字段名1
=’值1′,
字段名2
=’值2′,… where 条件
-- 语法:update `表名` set `字段名1`='值1',`字段名2`='值2',... where 条件 -- 修改学员名字 UPDATE `student` SET `name`='小红' WHERE id=1 -- 不指定条件的情况下,会改动表中的所有值 UPDATE `student` SET `name`='小明' -- 修改多个属性,之间用”,“隔开 UPDATE `student` SET `name`='小红',`pwd`='123456' WHERE id=1 -- 通过多个条件定位数据,修改多个属性 UPDATE `student` SET `name`='刘壮实',`pwd`='654321' WHERE `id`=1 AND `sex`='男' -- 值可以是一个具体的值,也可以是一个变量 UPDATE `student` SET `birthday`=CURRENT_TIME,`sex`='女' WHERE `name`='刘壮实' AND `sex`='男'
条件:
where 字段名 运算符 匹配条件,操作会返回boolean值
| 操作符 | 含义 | 举例 | 结果 |
|---|---|---|---|
| = | 等于 | 5=6 | false |
| > | 大于 | 5>6 | false |
| < | 小于 | 5<6 | true |
| >= | 大于等于 | 5>=6 | false |
| <= | 小于等于 | 5<=6 | true |
| <> 或 != | 不等于 | 5<>6 或 5!=6 | true |
| BETWEEN 条件1 AND 条件2 | 在某个范围内 | [1,5] | |
| AND | && | 1>2 && 3<4 | false |
| OR | || | 1>2 || 3<4 | true |
注意事项:
-
字段名是数据库的列,尽量带上“
-
筛选的条件如果没有指定,则会修改所有的列
-
值value可以是一个具体的值,也可以是一个变量
-
多个设置的属性之间使用英文“,”隔开
1.3 删除(delete)
语法:delete from
表名
where 条件
-- 删除数据(避免这样写,会删除表中全部数据),要指定条件进行删除 DELETE FROM `student` -- 删除指定数据 DELETE FROM `student` WHERE id =1
TRUNCATE命令:
完全清空一个数据表,表的结构和索引约束不会变!
格式:
TRUNCATE 表名或 TRUNCATE TABLE 表名
-- 清空student表 TRUNCATE `student`
DELETE和TRANCATE的区别
-
相同点:
都能删除数据,都不会删除表结构 -
不同点:
-
TRANCATE 重新设置自增列,计数器会归零
-
TRANCATE 不会影响事务
-
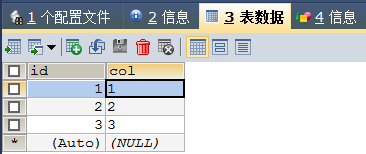
-- 测试delete和TRANCATE区别
CREATE TABLE IF NOT EXISTS`test`(
`id` INT(4) NOT NULL AUTO_INCREMENT,
`col` VARCHAR(20) NOT NULL,
PRIMARY KEY(`id`)
)ENGINE=INNODB DEFAULT CHARSET=utf8
INSERT INTO `test`(`col`)VALUES('1'),('2'),('3') -- id会自增,不用写字段名进行插入
DELETE FROM `test` -- 不会影响自增
TRUNCATE TABLE `test` -- 自增会清零
delete删除结果:
改变表—高级


TRANCATE删除效果:
查看方式同上

以下内容了解即可:
DELETE删除问题,重启数据库的现象
INNODB 自增列会从1开始(因为是存在内存当中的,断电即失)
MYISAM 继续从上一个自增量开始(因为是存在文件中的,不会丢失)
2. DQL语言
DQL(Data Query Language)语言
:数据查询语言,基本结构是由SELECT子句、FROM子句、WHERE子句组成的查询块。
格式:
SELECT <字段名表> FROM <表或视图名> WHERE <查询条件>
-
所有的查询操作都用它 select
-
简单的查询、复杂的查询它都能做
-
数据库最核心的语言、最重要的语句
-
使用频率最高的语句
新建数据库、表、添加数据
-- 创建一个school数据库
CREATE DATABASE IF NOT EXISTS `school`;
-- 使用school数据库
USE `school`;
-- 创建年级表grade
DROP TABLE IF EXISTS `grade`;
CREATE TABLE `grade`(
`gradeID` INT(11) NOT NULL AUTO_INCREMENT COMMENT '年级编号',
`gradeName` VARCHAR(50) NOT NULL COMMENT '年级名称',
PRIMARY KEY (`gradeID`)
) ENGINE=INNODB AUTO_INCREMENT = 6 DEFAULT CHARSET = utf8;
-- 插入grade表数据
INSERT INTO `grade`(`gradeID`,`gradeName`)
VALUES (1,'大一'),(2,'大二'),(3,'大三'),(4,'大四'),(5,'预科班');
-- 创建成绩表result
DROP TABLE IF EXISTS `result`;
CREATE TABLE `result`(
`StudentNo` INT(4) NOT NULL COMMENT '学号',
`SubjectNo` INT(4) NOT NULL COMMENT '课程编号',
`ExamDate` DATETIME NOT NULL COMMENT '考试日期',
`StudentResult` INT (4) NOT NULL COMMENT '考试成绩',
KEY `SubjectNo` (`SubjectNo`)
)ENGINE = INNODB DEFAULT CHARSET = utf8;
-- 插入result表数据
INSERT INTO `result` (`studentNo`, `subjectNo`, `ExamDate`, `studentResult`)
VALUES('10000','1','2016-02-15 00:00:00','71'),
('10000','2','2016-02-17 00:00:00','60'),
('10001','3','2016-02-17 00:00:00','46'),
('10002','4','2016-02-17 00:00:00','83'),
('10003','5','2016-02-17 00:00:00','60'),
('10004','6','2016-02-17 00:00:00','60'),
('10005','7','2016-02-17 00:00:00','95'),
('10006','8','2016-02-17 00:00:00','93'),
('10007','9','2016-02-17 00:00:00','23');
-- 创建学生表student
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student`(
`StudentNo` INT(4) NOT NULL COMMENT '学号',
`LoginPwd` VARCHAR(20) DEFAULT NULL,
`StudentName` VARCHAR(20) DEFAULT NULL COMMENT '学生姓名',
`Sex` TINYINT(1) DEFAULT NULL COMMENT '性别,取值0或1',
`GradeID` INT(11) DEFAULT NULL COMMENT '年级编号',
`Phone` VARCHAR(50) NOT NULL COMMENT '联系电话,允许为空,即可选输入',
`Address` VARCHAR(255) NOT NULL COMMENT '地址,允许为空,即可选输入',
`BornDate` DATETIME DEFAULT NULL COMMENT '出生时间',
`Email` VARCHAR (50) NOT NULL COMMENT '邮箱账号,允许为空,即可选输入',
`IdentityCard` VARCHAR(18) DEFAULT NULL COMMENT '身份证号',
PRIMARY KEY (`StudentNo`),
UNIQUE KEY `IdentityCard`(`IdentityCard`),
KEY `Email` (`Email`)
)ENGINE=MYISAM DEFAULT CHARSET=utf8;
-- 插入student表数据
INSERT INTO `student`(`StudentNo`,`LoginPwd`,`StudentName`,`Sex`,`GradeID`,`Phone`,`Address`,`BornDate`,`Email`,`IdentityCard`)
VALUES('10000','123','郭靖','0','1','13645667783','天津市河西区','1990-09-08 00:00:00','0@qq.com',NULL),
('10001','123','李文才','0','1','13645667890','地址不详','1994-04-12 00:00:00','1@qq.com',NULL),
('10002','123','李斯文','0','1','13645556793','河南洛阳','1993-07-23 00:00:00','2@qq.com',NULL),
('10003','123','张萍','1','1','13642345112','地址不详','1995-06-10 00:00:00','3@qq.com',NULL),
('10004','123','韩秋洁','1','1','13812344566','北京市海淀区','1995-07-15 00:00:00','4@qq.com',NULL),
('10005','123','张秋丽','1','1','13567893246','北京市东城区','1994-01-17 00:00:00','5@qq.com',NULL),
('10006','123','肖梅','1','1','13563456721','河北省石家庄市','1991-02-17 00:00:00','6@qq.com',NULL),
('10007','123','秦洋','0','1','13056434411','上海市卢湾区','1992-04-18 00:00:00','7@qq.com',NULL),
('10008','123','何睛睛','1','1','13053445221','广州市天河区','1997-07-23 00:00:00','8@qq.com',NULL),
('20000','123','王宝宝','0','2','15076552323','地址不详','1996-06-05 00:00:00','9@qq.com',NULL),
('20010','123','何小华','1','2','13318877954','地址不详','1995-09-10 00:00:00','10@qq.com',NULL),
('30011','123','陈志强','0','3','13689965430','地址不详','1994-09-27 00:00:00','11@qq.com',NULL),
('30012','123','李露露','1','3','13685678854','地址不详','1992-09-27 00:00:00','12@qq.com',NULL);
-- 创建科目表subject
DROP TABLE IF EXISTS `subject`;
CREATE TABLE `subject`(
`SubjectNo`INT(11) NOT NULL AUTO_INCREMENT COMMENT '课程编号',
`SubjectName` VARCHAR(50) DEFAULT NULL COMMENT '课程名称',
`ClassHour` INT(4) DEFAULT NULL COMMENT '学时',
`GradeID` INT(4) DEFAULT NULL COMMENT '年级编号',
PRIMARY KEY (`SubjectNo`)
)ENGINE = INNODB AUTO_INCREMENT = 18 DEFAULT CHARSET = utf8;
-- 插入subject表数据
INSERT INTO `subject`(`SubjectNo`,`SubjectName`,`ClassHour`,`GradeID`)
VALUES (1,'高等数学-1',110,1),
(2,'高等数学-2',110,2),
(3,'高等数学-3',100,3),
(4,'高等数学-4',130,4),
(5,'C语言-1',110,1),
(6,'C语言-2',110,2),
(7,'C语言-3',100,3),
(8,'C语言-4',130,4),
(9,'Java程序设计-1',110,1),
(10,'Java程序设计-2',110,2),
(11,'Java程序设计-3',100,3),
(12,'Java程序设计-4',130,4),
(13,'数据库结构-1',110,1),
(14,'数据库结构-2',110,2),
(15,'数据库结构-3',100,3),
(16,'数据库结构-4',130,4),
(17,'C#基础',130,1);
创建效果如下:
grade
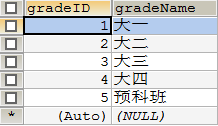
result
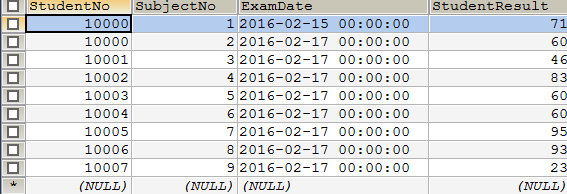
student

subject

2.1 查询(select)
-- 查询所有字段:SELECT * FROM 表名 -- 其中,*表示所有,注意:使用*时查询效率很低,最好指定字段名进行查询 -- 查询全部的学生 SELECT * FROM `student`
输出结果:

-- 查询指定字段:SELECT 字段名1,字段名2,... FROM 表名 SELECT `StudentNo`,`StudentName` FROM `student`
输出结果:
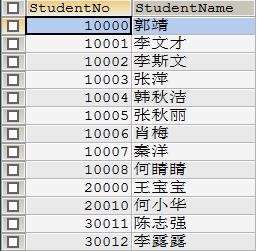
2.2 别名(as)
-- 别名(AS):给结果起一个名字,既可以给字段起别名,也可以给表起别名,还可以给查询结果取别名,别名用中英文均可以,且AS在使用时可省略 -- 给字段起别名 SELECT `StudentNo` AS 学号,`StudentName` AS `学生姓名` FROM `student` -- 给表起别名:在多个表同名的情况下使用 SELECT `StudentNo` AS 学号,`StudentName` AS `学生姓名` FROM `student` AS `s`
输出结果:
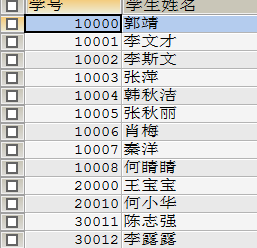
2.3 拼接字符串(count(a,b)函数)
-- 函数 CONCAT(a,b) 拼接字符串:对字符串a和b进行拼接,合成一个新的字符串
-- 将姓名:与StudentName拼接成字符串
SELECT CONCAT('姓名:',`StudentName`) AS `新名字` FROM `student` -- 即:姓名:StudentName
输出结果:
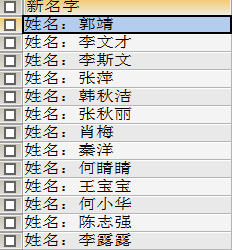
2.4 去重(distinct)
作用
:去除SELECT查询出来的结果中重复的数据,重复的数据只显示一条
-- 查询一下有哪些同学参加了考试 -- 查询学生的全部考试信息,显示result表的所有数据 SELECT * FROM `result` -- 通过学号查询哪些同学参加了考试,`StudentNo`表示学号 SELECT `StudentNo` FROM `result` -- 去除重复的学号信息,重复的数据(此处指学号信息)只显示一条 SELECT DISTINCT `StudentNo` FROM `result`
2.5 数据库的列/表达式
数据库中的表达式
:包括文本值、列、null、函数、计算表达式、系统变量等。
格式
:SELECT 表达式 FROM 表
查看MySQL技术文档
:
-
5.7版本
:
MySQL :: MySQL 5.7 Reference Manual :: 12.1 Built-In Function and Operator Reference
-
8.0版本
:
MySQL :: MySQL 8.0 Reference Manual :: 12.1 Built-In Function and Operator Reference
-- 通过函数查看系统版本 SELECT VERSION(); -- 5.7.19 -- 用数学表达式来计算结果,将结果保存为“计算结果” SELECT 100*3-1 AS '计算结果' -- 299 -- 查询自增的步长(变量) SELECT @@auto_increment_increment -- 1 -- 对数据进行某种整体运算,例:将学员考试成绩+1后输出 SELECT `StudentNo`,`StudentResult`+1 AS '提分后' FROM `result`
2.6 where条件字句
作用
:检索数据中符合条件的值,搜索的条件由一个或多个表达式组成,结果是布尔值。
常用的逻辑运算符:
建议使用英文字母方式,见名知意!!!
| 运算符 | 语法语法 | 描述 |
|---|---|---|
| and 或 && | a and b 或 a&&b | 逻辑与,两个都为真,结果为真 |
| or 或 || | a or b 或 a||b | 逻辑或,其中一个为真,结果为真 |
| not 或 ! | not a 或 !anot a 或 !a | 逻辑非,非真则假,非假则真 |
-- 练习 -- 使用and查询成绩在95~100之间的学员 SELECT `StudentNo`,`StudentResult` FROM `result` WHERE `StudentResult`>=95 AND `StudentResult`<=100 -- 使用&&查询成绩在95~100之间的学员 SELECT `StudentNo`,`StudentResult` FROM `result` WHERE `StudentResult`>=95 && `StudentResult`<=100 -- 使用or查看成绩为60或95的学员 SELECT `StudentNo`,`StudentResult` FROM `result` WHERE `StudentResult`=60 OR `StudentResult`=95 -- 使用||查看成绩为60或95的学员 SELECT `StudentNo`,`StudentResult` FROM `result` WHERE `StudentResult`=60 || `StudentResult`=95 -- 使用not查看学号不是10000的学员 SELECT `StudentNo`,`StudentResult` FROM `result` WHERE NOT `StudentNo`=10000 -- 使用!查看学号不是10000的学员 SELECT `StudentNo`,`StudentResult` FROM `result` WHERE `StudentNo`!=10000
2.7 条件查询(between and、like、in、NULL)
| 运算符 | 语法 | 描述 |
|---|---|---|
| IS NULL | a IS NULL | 如果操作符为NULL,结果为真 |
| IS NOT NULL | a IS NOT NULL | 如果操作符不为NULL,结果为真 |
| BETWEEN… AND … | a BETWEEN b AND c | 如果a在b和c之间,结果为真 |
|
LIKE |
a LIKE b | SQL匹配,如果a匹配b,结果为真 |
|
IN |
a IN(a1,a2,a3,…) | 如果a为a1,a2…其中的某一个,结果为真 |
BETWEEN … AND …
:指定查询范围
-- 使用between... and...查看成绩在90~100之间的学员 SELECT `StudentNo`,`StudentResult` FROM `result` WHERE `StudentResult` BETWEEN 90 AND 100
LIKE:
模糊查询
-- LIKE:%代表0~任意多个字符, _代表1个字符 -- %在前表示前模糊,在中间表示中间模糊,在后面表示后模糊 -- 查询姓李的同学:第一个字符为刘,后面的字符任意 SELECT `StudentNo`,`StudentName` FROM `student` WHERE `StudentName` LIKE '李%' -- 查询姓李的同学:名字为两个字的 SELECT `StudentNo`,`StudentName` FROM `student` WHERE `StudentName` LIKE '李_' -- 查询姓李的同学:名字为三个字的 SELECT `StudentNo`,`StudentName` FROM `student` WHERE `StudentName` LIKE '李__' -- 查询名字中带有李字的同学,只要含有李字就行 SELECT `StudentNo`,`StudentName` FROM `student` WHERE `StudentName` LIKE '%李%'
IN:
精确查询
-- IN:条件为具体的一个或多个值,并非模糊匹配,而是具体匹配
-- 查询10000、10001、10002号学员
SELECT `StudentNo`,`StudentName` FROM `student`
WHERE `StudentNo` IN(10000,10001,10002)
-- 查询在地址不详的学员
SELECT `StudentNo`,`StudentName` FROM `student`
WHERE `Address` IN('地址不详');
-- 查询在地址不详和北京市东城区的学员
SELECT `StudentNo`,`StudentName` FROM `student`
WHERE `Address` IN('地址不详','北京市东城区');
NULL、NOT NULL:
-- 查询地址为空的学生 SELECT `StudentNo`,`StudentName` FROM `student` WHERE `Address`='' OR `Address` IS NULL -- 查询出生日期不为空的同学 SELECT `StudentNo`,`StudentName` FROM `student` WHERE `BornDate` IS NOT NULL
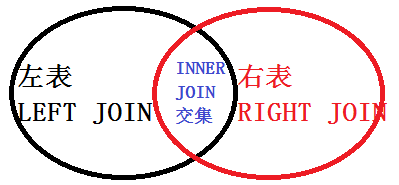
2.8 联表查询(inner join、left join、right join)
我们在做查询的时候,会遇到可能一张表满足不了我们要求的情况,可能要求获取的数据来自于两张、三张甚至更多张表,对此,我们就应该使用联表查询。
-
3种JOIN对比:
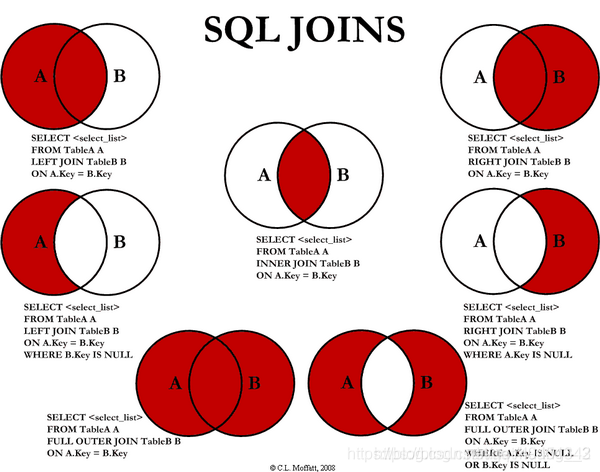
-
实际JOIN理论细分可分为7种:
-- 练习:查询参加了考试的同学,输出学生信息:学号、姓名、科目编号、分数 -- 查询所有学生信息 SELECT * FROM `student` -- 查询所有成绩信息 SELECT * FROM `result`
左表student:

右表result:

/* 根据上面两条语句查询出来的效果,我们还需要一个一个对照着学生的学号去找,这种方式过于麻烦,因此我们需要用一种方式将这些数据拼接起来,方便我们查看。 思路: 1.分析需求:分析查询的字段来自哪些表?student、result 2.连接方式:确定使用哪种连接查询?7种 确定交叉点:这两个表中哪个数据是相同的 */ -- join on 连接查询(判断的条件) -- where 等值查询 -- 分析两张表结构,我们可以判断的条件为:student表中的`StudentNo`与result表中的`StudentNo`字段名相同
1.内连接(INNER JOIN):
也称为自然连接
-- 注意: 内连接是从结果中删除其他被连接表中没有匹配行的所有行,所以内连接可能会丢失信息。 -- 重点:内连接,只查匹配行。 -- 语法:INNER可省略,单独写JOIN时,默认INNER JOIN SELECT s.`StudentNo`,`StudentName`,`SubjectNo`,`StudentResult` FROM `student` AS `s` INNER JOIN `result` AS `r` ON s.`StudentNo`=r.`StudentNo` -- 注意此处是ON或者WHERE均可以
输出结果:
保留两个表中都有匹配的行(共有的部分)

外连接:
与内连接相比,即使没有匹配行,也会返回一个表的全集。
-- 外连接分为三种:左外连接,右外连接,全外连接,对应SQL:LEFT/RIGHT/FULL OUTER JOIN。 -- 通常我们省略outer这个关键字,写成:LEFT/RIGHT/FULL JOIN。 -- 重点:至少有一方保留全集,没有匹配行用NULL代替。 -- 1.LEFT OUTER JOIN,简称LEFT JOIN,左外连接(左连接) -- 结果集保留左表的所有行,但只包含第二个表与第一表匹配的行,第二个表相应的空行被放入NULL值。 -- 通过结果,可以看到左连接包含了第一张表的所有信息,在第二张表中如果没有匹配项,则用NULL代替 -- 2.RIGHT OUTER JOIN,简称RIGHT JOIN,右外连接(右连接) -- 右外连接保留了第二个表的所有行,但只包含第一个表与第二个表匹配的行,第一个表相应空行被入NULL值。 -- 通过结果,可以看到右连接包含了第二张表的所有信息,在第一张表中如果没有匹配项,则用NULL代替 -- 3.FULL OUTER JOIN,简称FULL JOIN,,全外连接(全连接) -- 全外连接,简称:全连接,会把两个表所有的行都显示在结果表中 -- 包含了两张表的所有记录,没有记录丢失,没有匹配的行用NULL代替。
2.使用右连接(RIGHT JOIN):
侧重于result表
SELECT * FROM `student` SELECT * FROM `result` SELECT s.`StudentNo`,`StudentName`,`SubjectNo`,`StudentResult` FROM `student` AS `s` RIGHT JOIN `result` AS `r` ON s.`StudentNo`=r.`StudentNo` -- 注意此处使用ON,而不是使用where
参考链接
:
输出结果
:输出右表的所有信息,左表中没有匹配的行信息用NULL填充

3.使用左连接(LEFT JOIN):
侧重于student
SELECT * FROM `student` SELECT * FROM `result` SELECT s.`StudentNo`,`StudentName`,`SubjectNo`,`StudentResult` FROM `student` AS `s` LEFT JOIN `result` AS `r` ON s.`StudentNo`=r.`StudentNo` -- 注意此处使用ON
输出结果
:输出左表的所有信息,右表中没有匹配的行信息用NULL填充

总结:
-
JOIN ON 连接查询— ON在连接查询中均适用
-
WHERE 等值查询 — 在INNER JOIN可以使用
-
INNER JOIN、LEFT JOIN、RIGHT JOIN结果对比:
| 操作 | 描述 |
|---|---|
| INNER JOIN | 如果表中至少有一个匹配,就返回;如果两张表都有,就确定是哪张表即可 |
| LEFT JOIN | 会从左表中返回所有的值,即使右表中没有匹配 |
| RIGHT JOIN | 会从右表中返回所有的值,即使左表中没有匹配 |
-- 查询缺考的同学:由“缺考”可知,该查询侧重于找出成绩为NULL(没有参加考试,考试成绩记为NULL)的同学,故使用LEFT JOIN SELECT s.`StudentNo`,`StudentName`,`SubjectNo`,`StudentResult` FROM `student` `s` LEFT JOIN `result` `r` ON s.`StudentNo`=r.`StudentNo` WHERE `StudentResult` IS NULL -- 思考题:查询参加考试的同学信息:学号、学生姓名、科目名称、分数 /* 思路: 1.分析需求,分析查询的字段来自哪些表?student、result、subject 2.确定使用哪种连接查询?7种 确定交叉点:这两个表中哪个数据是相同的 判断的条件:`student`表中的`StudentNo`与`result`表中的`StudentNo`相同 `result`表中的`SubjectNo`与`subject`表中的`SubjectNo`相同 先有考试,后有科目分数 */ -- 先连接查询student表、result表,用StudentNo进行连接 SELECT s.`StudentNo`,s.`StudentName`,sub.`SubjectName`,r.`StudentResult` FROM `student` s RIGHT JOIN `result` r -- 侧重于参加考试同学的成绩分数,故使用RIGHT JOIN ON s.`StudentNo`=r.`StudentNo` -- 再连接查询result表、subject表,用SubjectNo进行连接 INNER JOIN `subject` sub ON r.`SubjectNo`=sub.`SubjectNo` -- 或 -- 先连接查询student表、result表,用StudentNo进行连接 SELECT s.`StudentNo`,`StudentName`,`SubjectName`,`StudentResult` FROM `student` s RIGHT JOIN `result` r -- 侧重于参加考试同学的成绩分数,故使用RIGHT JOIN ON s.`StudentNo`=r.`StudentNo` -- 再连接查询result表、subject表,用SubjectNo进行连接 LEFT JOIN `subject` sub ON r.`SubjectNo`=sub.`SubjectNo`
输出结果
:
(1)RIGHT JOIN + INNER JOIN:求交集

(2)RIGHT JOIN + LEFT JOIN:侧重于subject表

总结:
-
我要查询哪些数据? select…
-
从哪几个表查? from 表 join方法 连接的表 on 交叉条件
-
假设存在一种多张表查询,慢慢来,先查询两张表,然后再慢慢增加。
重在分析好表与表查询之间的关系
2.9 自连接查询
定义
:自己的表和自己的表连接,核心:一张表拆为两张一样的表即可。
在school数据库中添加catalog表
-- 创建category表:categoryid为子类id,pid为父类id
DROP TABLE IF EXISTS `category`;
CREATE TABLE IF NOT EXISTS `category`(
`categoryid` INT(3) NOT NULL COMMENT '子类id',
`pid` INT(3) NOT NULL COMMENT '父类id,如果没有父类id,则为1',
`categoryname` VARCHAR(10) NOT NULL COMMENT '种类名字',
PRIMARY KEY (`categoryid`)
) ENGINE=INNODB DEFAULT CHARSET=utf8 COLLATE=utf8_general_ci;
-- 插入category数据
INSERT INTO `category` (`categoryid`,`pid`,`categoryname`)
VALUES (2,1,'信息技术'),
(3,1,'软件开发'),
(5,1,'美术设计'),
(4,3,'数据库'),
(8,2,'办公信息'),
(6,3,'web开发'),
(7,5,'ps技术');•
输出结果
:
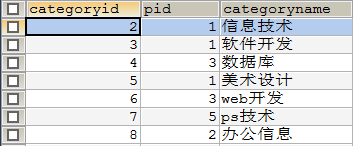
我们分析这张表,可以看出,在这张表内实现了分级,例如:信息技术子类id=2,父类id=1,而数据库子类id=4,父类id=1。我们可以根据上述规则将这张表拆分为两个表:
-
父类
:父类id都是1的
| categoryid | categoryname | pid |
|---|---|---|
| 2 | 信息技术 | 1 |
| 3 | 软件开发 | 1 |
| 5 | 美术设计 | 1 |
-
子类
:父类id不是1的,即上面剩下的数据
| categoryid | categoryname | pid |
|---|---|---|
| 4 | 数据库 | 3 |
| 6 | web开发 | 3 |
| 7 | ps技术 | 5 |
| 8 | 办公信息 | 2 |
操作
:查询父类对应的子类关系
| 父类 | 子类 |
|---|---|
| 信息技术 | 办公信息 |
| 软件开发 | 数据库 |
| 软件开发 | web开发 |
| 美术设计 | ps技术 |
-- 对于都在一个表中的字段,我们就使用自连接查询 -- 查询父子信息:把一张表拆为两个一模一样的表 -- 拆名字 SELECT a.`categoryname` AS 父栏目 ,b.`categoryname` AS 子栏目 -- 拆表 FROM `category` AS a,`category` AS b -- 通过id进行连接 WHERE a.`categoryid`=b.`pid` -- 此处不能调换位置,要一一对应
输出结果
:
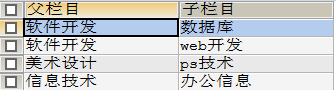
通过自连接查询实现
SELECT a.`categoryname` '科目类别',b.`categoryname` '课程' FROM `category` a INNER JOIN `category` b -- 此处只能用INNER JOIN ON a.`categoryid`=b.`pid` -- 此处不能调换位置,要一一对应
输出结果
:

-- 补充练习: -- 1.查询学员所属的年级,输出学员的信息:学号、学生姓名、年级名称 SELECT `StudentNo`,`StudentName`,`gradeName` FROM `student` s INNER JOIN `grade` g ON s.`GradeID`=g.`gradeID` -- 与上面结果相同,只是顺序有交换 SELECT `StudentNo`,`StudentName`,`gradeName` FROM `student` s LEFT JOIN `grade` g ON s.`GradeID`=g.`gradeID`
输出结果:

-- 2.查询科目所属年级,输出科目名称、年级名称 SELECT `SubjectName`,`gradeName` FROM `subject` s INNER JOIN `grade` g ON s.`GradeID`=g.`gradeID` -- 与上面结果相同,只是顺序有交换 SELECT `SubjectName`,`gradeName` FROM `subject` s LEFT JOIN `grade` g ON s.`GradeID`=g.`gradeID`
输出结果:

-- 3.查询参加数据库结构-1考试的同学信息:学号、学生姓名、科目名称、分数 SELECT s.`StudentNo`,`StudentName`,`SubjectName`,`StudentResult` FROM `student` s INNER JOIN `result` r ON s.`StudentNo`=r.`StudentNo` RIGHT JOIN `subject` sub -- 侧重于所有科目 ON r.`SubjectNo`=sub.`SubjectNo` WHERE `SubjectName`='数据库结构-1' -- 单独选出数据库结构-1考试一科
输出结果:

2.10 排序(order by)
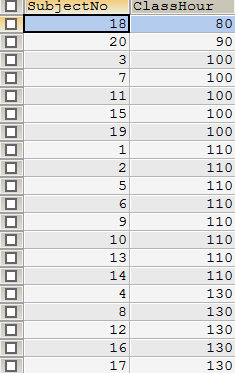
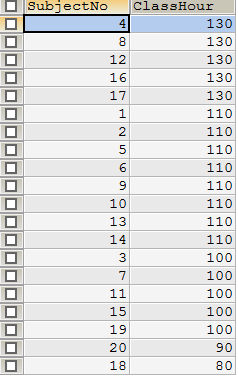
SELECT `SubjectNo`,`ClassHour` FROM `subject` -- 从subject表中选择哪些字段进行显示 -- 排序:ORDER BY,其中,ASC表示升序,DESC表示降序 ORDER BY `ClassHour` ASC -- 根据ClassHour进行升序显示 -- ORDER BY `ClassHour` DESC -- 根据ClassHour进行降序显示
输出结果:
(1)升序结果
(2)降序结果
2.11 分页(limit)
-- 为什么要分页?缓解数据库压力,给人更好的体验,瀑布流需要不断加载 SELECT `SubjectNo`,`ClassHour` FROM `subject` ORDER BY `ClassHour` ASC -- 语法:limit 起始值 页面的大小 -- 每页只显示5条数据 limit 0,5 -- 对应1-5条数据,下标从零开始,0-4表示第1页 -- limit 5,5 -- 对应6-10条数据,下标从5开始,5-9表示第2页 -- limit 10,5 -- 对应11-15条数据,下标从10开始,10-14表示第3页 -- LIMIT (n-1)*5,5 -- (n-1)*5+1-(n-1)*5+5条数据 表示第n页 -- 以此类推...... -- 详细语法:LIMIT (n-1)*pageSize,pageSize -- 其中,pageSize表示页面大小,(n-1)*pageSize表示起始值,n表示当前页,总页数=数据总数/页面大小
输出结果:
(1)第1页
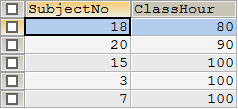
(2)第2页

练习题:
查询 “ C语言-3 ” 课程成绩排名前十的同学,并且分数要大于80的学生信息,输出:学号、姓名、课程名称、分数。
SELECT s.`StudentNo`,`StudentName`,`SubjectName`,`StudentResult` FROM `student` s INNER JOIN `result` r ON s.`StudentNo`=r.`StudentNo` INNER JOIN `subject` sub ON r.`SubjectNo`=sub.`SubjectNo` WHERE `SubjectName`= 'C语言-3' AND `StudentResult`>=80 ORDER BY `StudentResult` DESC LIMIT 0,10
2.12 子查询与嵌套查询
之前我们在写sql,查询条件中的值都是固定的,如果将条件中的值换成计算出来的话,就是子查询了。
本质:
在where条件下嵌套一个查询语句
-- 1.查询“数据库结构-1”的所有考试结果,输出:学号、科目编号、成绩,降序排列
-- 查表可知,成绩表中包含了学号
-- 方式1:使用连接查询
SELECT `StudentNo`,r.`SubjectNo`,`StudentResult`
FROM `result` r
INNER JOIN `subject` sub -- 或 LEFT JOIN `subject` sub
ON r.`SubjectNo`=sub.`SubjectNo`
WHERE `SubjectName`='数据库结构-1'
ORDER BY `StudentResult` DESC;
-- 方式2:使用子查询(由里及外)
-- 查询所有“数据库结构-1”的学生学号
SELECT `StudentNo`,`SubjectName`,`StudentResult`
FROM `result`
WHERE `SubjectNo`= ANY(
SELECT `SubjectNo` FROM `subject`
WHERE `SubjectName` = '数据库结构-1'
)
ORDER BY `StudentResult` DESC
-- Subquery returns more than 1 row:表示子查询返回了多行数据
-- 解决方法:在()前加ANY
-- 补充:
-- any和all都是用于子查询的,any表示有任何一个满足就返回true,all表示全部都满足才返回true
-- 在进行非等值查询时建议使用max和min,那样看起来更加直观。
-- 2.查询不小于80分的学生的学号和姓名
SELECT DISTINCT s.`StudentNo`,`StudentName`
FROM `student` s
INNER JOIN `result` r -- 或 RIGHT JOIN `result` r
ON s.`StudentNo`=r.`StudentNo`
WHERE `StudentResult`>=80
-- 3.在2的基础上,增加一个科目:高等数学-4
-- 查询“高等数学-4”的编号
SELECT DISTINCT s.`StudentNo`,`StudentName`
FROM `student` s
RIGHT JOIN `result` r
ON s.`StudentNo`=r.`StudentNo`
WHERE `StudentResult` >= 80 AND `SubjectNo`=ANY(
SELECT `SubjectNo` FROM `subject`
WHERE `SubjectName`='高等数学-4'
);
-- 改造(由里及外)
-- 1.查询科目为高等数学-4的课程编号
SELECT `SubjectNo` FROM `subject` WHERE `SubjectName` = '高等数学-4';
-- 2.查询课程编号中对应成绩大于80分的学号
SELECT `StudentNo` FROM `result` WHERE `StudentResult`>=80 AND `SubjectNo`= (
SELECT `SubjectNo` FROM `subject` WHERE `SubjectName` = '高等数学-4'
);
-- 3.根据学号求取学生姓名
SELECT `StudentNo`,`StudentName` FROM `student` WHERE `StudentNo` IN (
SELECT `StudentNo` FROM `result` WHERE `StudentResult`>=80 AND `SubjectNo`= (
SELECT `SubjectNo` FROM `subject` WHERE `SubjectName` = '高等数学-4'
)
);
-- 或
SELECT `StudentNo`,`StudentName` FROM `student` WHERE `StudentNo` = ANY(
SELECT `StudentNo` FROM `result` WHERE `StudentResult`>=80 AND `SubjectNo`= (
SELECT `SubjectNo` FROM `subject` WHERE `SubjectName` = '高等数学-4'
)
);
-- 用连接查询实现
SELECT s.`StudentNo`,`StudentName`
FROM `student` s
INNER JOIN `result` r
ON s.`StudentNo`=r.`StudentNo`
INNER JOIN `subject` sub
ON r.`SubjectNo`=sub.`SubjectNo`
WHERE `SubjectName`='高等数学-2' AND `StudentResult`>=80;
-- 练习:使用子查询查询“C语言-1”前5名同学的成绩信息:学号、姓名、分数
SELECT DISTINCT s.`StudentNo`,`StudentName`,`StudentResult`
FROM `student` s
INNER JOIN `result` r
ON s.`StudentNo`=r.`StudentNo`
WHERE `SubjectNo` = ANY(
SELECT `SubjectNo` FROM `subject` WHERE `SubjectName`='C语言-1'
)
ORDER BY `StudentResult` DESC
LIMIT 0,5;
2.13 分组和过滤
-- 查询不同课程的平均分、最高分、最低分,平均分大于80的记录 -- 核心:根据不同课程进行分组 SELECT `SubjectName`,AVG(`StudentResult`) AS '平均分',MAX(`StudentResult`) AS '最高分',MIN(`StudentResult`) AS '最低分' FROM `result` r INNER JOIN `subject` sub ON r.`SubjectNo`=sub.`SubjectNo` GROUP BY r.`SubjectNo` -- 通过什么字段来查询 HAVING 平均分>80;
注意点:
-
where 是一个约束声明,使用Where约束来自
数据库
的数据,
where是在结果返回之前起作用的,where中不能使用聚合函数。
-
having是一个过滤声明,是
在查询返回结果集以后对查询结果进行的过滤操作,在Having中可以使用聚合函数。
-
优先级:
-
在查询过程中聚合语句(sum,min,max,avg,count)要比having子句优先执行;
-
where子句在查询过程中执行优先级高于聚合语句。
-
2.14 select小结
SELECT语法
SELECT [ALL | DISTINCT]
{* | table.* | [table.field1[AS aliasl][,table.field2[AS alias2]][,...]]}
FROM table_name [AS table_alias]
[LEFT | RIGHT | INNER JOIN table_name2] -- 联合查询
[WHERE ...] -- 指定结果需满足的条件
[GROUP BY ...] -- 指定结果按照哪几个字段来分组
[HAVING] -- 过滤分组的记录必须满足的次要条件
[ORDER BY ...] -- 指定查询记录按一个或多个条件排序
[LIMIT {[OFFSET,]ROW_COUNT | row_countoffset OFFSET}];
-- 指定查询的记录从哪条至哪条
-- 注意:[]括号代表可选的,{}括号代表必选的
-- all是默认的,查询所所有,distinct是消除重复的;
-- xxx join:代表要连接的表,on表示等值判断;
-- where:条件子句,后面跟查询的值或者子查询语句(注意不能跟聚合函数共同使用);
-- group by:通过某个字段来分组;
-- having: 过滤分组后的信息,作用和where差不多,只是放置的位置不同,且having能跟聚合函数一起使用;
-- order by:通过某个字段来排序,[升序(asc)/ 降序(desc)];
-- limit:分页,从索引为某个值开始,查多少条数据 ;
-- 顺序很重要
select 去重 要查询的字段 from 表(注意:表和字段可以起别名)
xxx join 要连接的表 on 等值判断
where 具体的值,子查询语句
group by 通过哪个字段进行分组
having 过滤分组后的信息,条件和where是一样的,只是位置不同而已
order by 通过哪个字段进行排序,升序asc、降序desc
limit stratindex,pagesize 起始位置,页面大小 进行分页
-- 业务层面的查询:跨表、跨数据库......