孤立森林(isolation Forest)算法,2008年由刘飞、周志华等提出,算法不借助类似距离、密度等指标去描述样本与其他样本的差异,而是直接去刻画所谓的
疏离程度(isolation)
,因此该算法简单、高效,在工业界应用较多。
Isolation Forest算法的逻辑很直观,算法采用二叉树对数据进行分裂,样本选取、特征选取、分裂点选取都采用随机化的方式(我称之为
瞎几把乱分
,诶,但是人家效果出奇的好,你说气人不)。如果某个样本是异常值,可能需要很少次数就可以切分出来,看看下面这个不大恰当的例子。
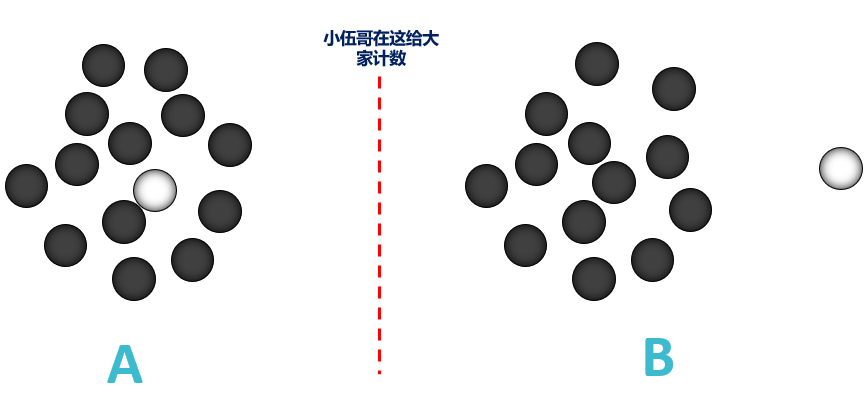
给你根棍子,还把你眼睛蒙上,要把下面的白棋巴拉出来,找个人在边上给你计数,看多少次能分出来,
A
这一堆,需要的次数非常多,可能一早上你都巴拉不出来;而
B
这一堆,可能一次就巴拉出来了,需要的次数非常少,那我们就可以通过计算巴拉的次数来衡量一个点的异常程度了,巴拉的次数越少,越不合群,也就越异常。一个人巴拉可能存在随机性,不大准,那我们找100个人来巴拉,然后将每个人巴拉的次数取的平均,那不就准了,孤立森林,大概也就是这个思想了。
瞎扯了这么多,我们开始正文吧。
一、理解孤立森林
再用一个例子来说明孤立森林的思想:假设现在有一组一维数据(如下图),我们要对这组数据进行切分,
目的是把点A和 B单独切分出来
,先在最大,值和最小值之间随机选择一个值 X,然后按照 <X 和 >=X 可以把数据分成左右两组,在这两组数据中分别重复这个步骤,直到数据不可再分。
点B跟其他数据比较疏离,可能用
很少的次数
就可以把它切分出来,点 A 跟其他数据点聚在一起,可能需要更多的次数才能把它切分出来。
那么
从统计意义
上来说,相对聚集的点需要分割的次数较多,比较孤立的点需要的分割次数少,孤立森林就是利用分割的次数来度量一个点是聚集的(正常)还是孤立的(异常)。

直观上来看,我们可以发现,那些密度很高的簇要被切很多次才会停止切割,即每个点都单独存在于一个子空间内,但那些分布稀疏的点,大都很早就停到一个子空间内了。
先sklearn的孤立森林算法,搞个例子看看大概的算法流程和结果,模拟上面的数据构造一个数据集。异常检测的工具还是很多的,主要有以下几个,我们这次选用的是
Scikit-Learn
1、PyOD:超过30种算法,从经典模型到深度学习模型一应俱全,和sklearn的用法一致
2、Scikit-Learn:包含了4种常见的算法,简单易用
3、TODS:与PyOD类似,包含多种时间序列上的异常检测算法
数据集是月工资的,单位为万,看看哪些是异常的。

# 加载模型所需要的的包
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.ensemble import IsolationForest
# 构造一个数据集,只包含一列数据,假如都是月薪数据,有些可能是错的
df = pd.DataFrame({'salary':[4,1,4,5,3,6,2,5,6,2,5,7,1,8,12,33,4,7,6,7,8,55]})
#构建模型 ,n_estimators=100 ,构建100颗树
model = IsolationForest(n_estimators=100,
max_samples='auto',
contamination=float(0.1),
max_features=1.0)
# 训练模型
model.fit(df[['salary']])
# 预测 decision_function 可以得出 异常评分
df['scores'] = model.decision_function(df[['salary']])
# predict() 函数 可以得到模型是否异常的判断,-1为异常,1为正常
df['anomaly'] = model.predict(df[['salary']])
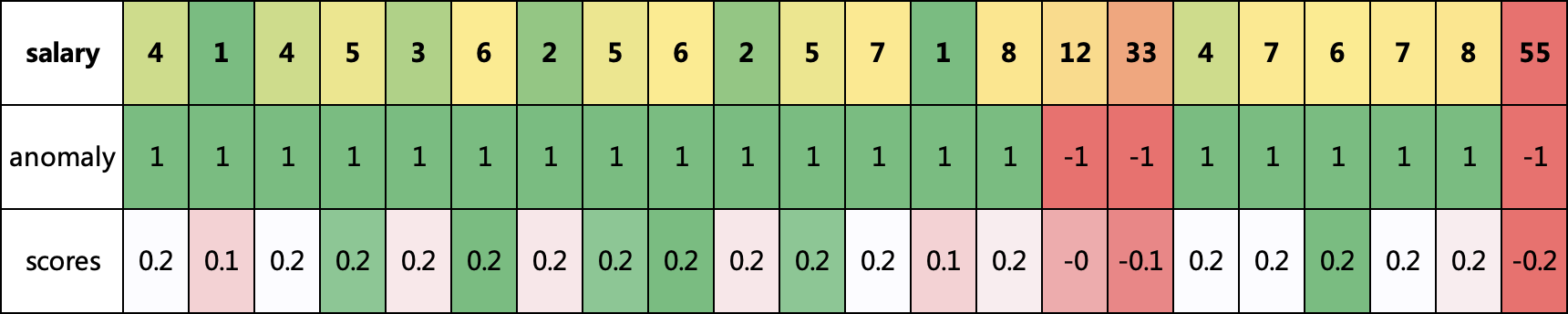
print(df)
salary scores anomaly
0 4 0.212235 1
1 1 0.095133 1
2 4 0.212235 1
3 5 0.225169 1
4 3 0.156926 1
5 6 0.227608 1
6 2 0.153989 1
7 5 0.225169 1
8 6 0.227608 1
9 2 0.153989 1
10 5 0.225169 1
11 7 0.212329 1
12 1 0.095133 1
13 8 0.170615 1
14 12 -0.010570 -1
15 33 -0.116637 -1
16 4 0.212235 1
17 7 0.212329 1
18 6 0.227608 1
19 7 0.212329 1
20 8 0.170615 1
21 55 -0.183576 -1
我们可以看到,发现了三个异常的数据,和我们认知差不多,都是比较高的,并且异常值越大,异常分scores就越大,比如那个月薪55万的,不是变态就是数据错了。
其实到此,你基本上就会用这个算法了,但是,我们还需要更深入的理解的话,继续往下看。
二、孤立森林算法详解
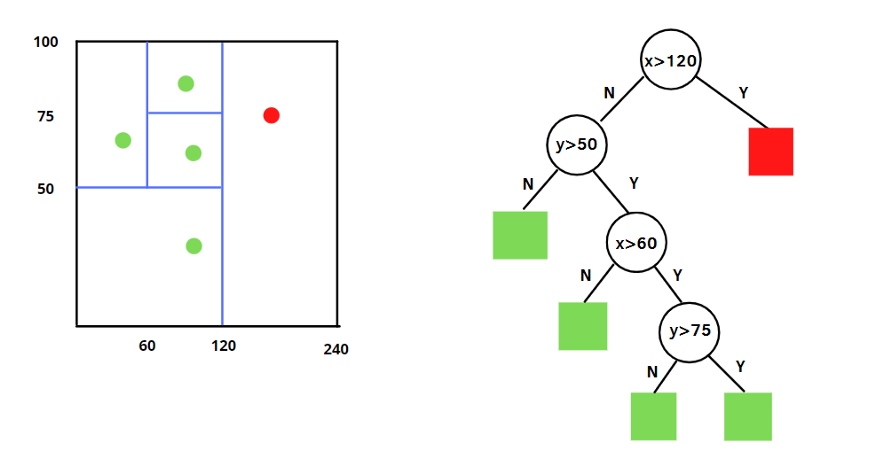
孤立森林与随机森林非常相似,它是基于给定数据集的决策树集成而建立的,然而,也有一些区别,孤立森林将异常识别为树上平均路径较短的观测结果,每个孤立树都应用了一个过程:
随机选择m个特征,通过在所选特征的最大值和最小值之间随机选择一个值来分割数据点。观察值的划分递归地重复,直到所有的观察值被孤立。

我们看看更加明细的训练+预测过程
1、前提假设
异常样本不能占比太高
异常样本和正常样本差异较大
2、算法思想
异常样本更容易快速落入叶子结点或者说,异常样本在决策树上,距离根节点更近
3、算法训练
1)训练逻辑
从原始数据中,有放回或者不放回的抽取部分样本,选取部分特征,构建一颗二叉树(iTree即Isolation Tree),利用集成学习的思想,多次抽取样本和特征,完成多棵iTree的构建。
2)iTree停止条件
树达到指定的高度/深度,或者数据不可再分。
3)算法伪代码如下


4)几个小问题:
- 树的最大深度=ceiling(log(subsimpleSize)),paper里说自动指定,sklearn也是在代码中写死:max_depth = int(np.ceil(np.log2(max(max_samples, 2))))这个值接近树的平均深度,我们只关注那些小于平均深度的异常值,所以无需让树完全生长
- Sub-sampling size,每次抽取的样本数,建议256即可,大于256,性能上不会有大的提升
- Number of tree,建议100,如果特征和样本规模比较大,可以适当增加
4、算法预测
1)PathLength计算逻辑
类似二分类模型,预测时可输出P ( y = 1 ) P(y=1)P(y=1),iforest最终也可以输出一个异常得分。很容易想到用该样本落入叶子结点时,split的次数(即样本落入叶子结点经过的边)作为衡量指标,对于t tt棵树,取平均即可。先看PathLength的计算逻辑:

2)PathLength计算公式如下:
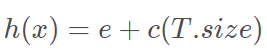
其中e为样本x xx从树的根节点到叶节点的过程中经历的边的个数,即split次数。T.size表示和样本x同在一个叶子结点样本的个数,C(T.size)可以看做一个修正值,表示T.size个样本构建一个二叉树的平均路径长度,c(n)计算公式如下:
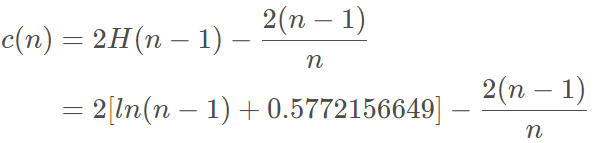
其中,0.5772156649为欧拉常数
3)为何加入这一修正值?
由于树的深度设置为ceiling(log(subsimpleSize)) ,所以可能大部分样本的PathLength都比较接近,而如果叶子结点的样本数越多,该样本是异常值的概率也较低(基于fewAndDifferent的假设)。另外c(n)是单调递增的,总之,加了修正,使得异常和正常样本的PathLength差异更大,可以简单的理解,如果样本快速落入叶子结点,并且该叶子结点的样本数较少,那么其为异常样本的可能性较大。
5、计算异常分
样本落入叶子结点经过的边数(split次数),除了和样本本身有关,也和limit length和抽样的样本子集有关系。这里,作者采用归一化的方式,把split length的值域映射到0-1之间。具体公式如下:
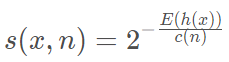
其 中:
h(x):
为样本在iTree上的PathLength
E(h(x)):
为样本在t棵iTree的PathLength的均值
c(n):
为n个样本构建一个BST二叉树的平均路径长度,为什么要算这个,因为iTree和BST的结构的等价性, 标准化借鉴BST(Binary Search Tree)去估计路径的平均长度c(n)。
上述公式,指数部分值域为(−∞,0),因此s值域为(0,1)。当PathLength越小,s越接近1,此时样本为异常值的概率越大。
我们知道了E(h(x))是
根节点
到
外部节点
x的
路径长度h(x)
的平均值,而c(n)是给定n的h(x)的平均值,用于规范化h(x)。有三种可能的情况:
当E(h(x))= c(n), s(x,n)=1/2
当E(h(x))-> 0, s(x,n)= 1
当E(h(x))-> n-1,s(x,n)= 0
当观测的得分接近1时,路径长度非常小,那么数据点很容易被孤立,我们有一个异常。
当观测值小于0.5时,路径长度就会变大,然后我们就得到了一个正常的数据点。
如果所有的观察结果都有0.5左右的异常值,那么整个样本就没有任何异常。
然后,孤立森林可以通过计算每棵树的异常得分,并在孤立树之间进行平均,从而在比正常观测更少的步骤中隔离异常。事实上,得分较高的异常值路径长度较低。
注:
scikit-learn的隔离森林引入了异常分数的修改,异常值由负的分数表示,而正的分数意味着是正常的。
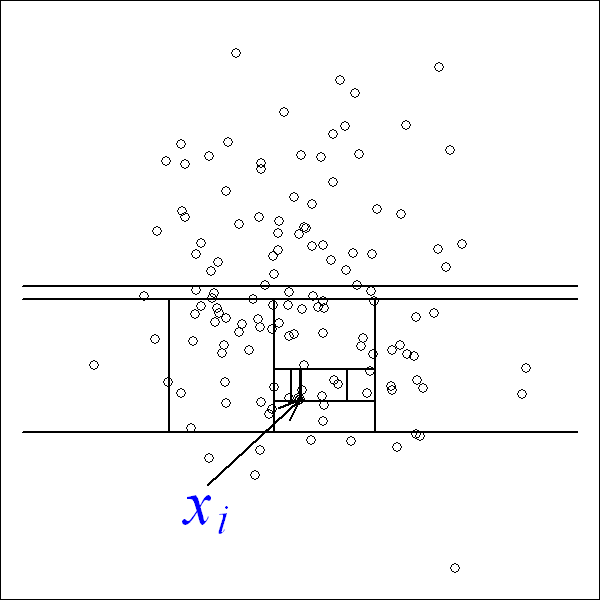
上图就是对子样本进行切割训练的过程,左图的 xi 处于密度较高的区域,因此切割了十几次才被分到了单独的子空间,而右图的 x0 落在边缘分布较稀疏的区域,只经历了四次切分就被 “孤立” 了。
四、孤立森林参数
我们使用sklearn中的孤立森林,进行参数调节讲解,一般任务默认参数即可,算法API地址:
sklearn.ensemble.IsolationForest — scikit-learn 1.0.2 documentation
1、基本用法
sklearn.ensemble.IsolationForest(
*,
n_estimators=100,
max_samples='auto',
contamination='auto',
max_features=1.0,
bootstrap=False,
n_jobs=None,
random_state=None,
verbose=0,
warm_start=False)
2、参数详解
n_estimators :
int, optional (default=100)
iTree的个数,指定该森林中生成的随机树数量,默认为100个
max_samples :
int or float, optional (default=”auto”)
构建子树的样本数,整数为个数,小数为占全集的比例,用来训练随机数的样本数量,即子采样的大小
如果设置的是一个int常数,那么就会从总样本X拉取max_samples个样本来生成一棵树iTree
如果设置的是一个float浮点数,那么就会从总样本X拉取max_samples * X.shape[0]个样本,X.shape[0]表示总样本个数
如果设置的是”auto”,则max_samples=min(256, n_samples),n_samples即总样本的数量
如果max_samples值比提供的总样本数量还大的话,所有的样本都会用来构造数,意思就是没有采样了,构造的n_estimators棵iTree使用的样本都是一样的,即所有的样本
contamination :
float in (0., 0.5), optional (default=0.1)
取值范围为(0., 0.5),表示异常数据占给定的数据集的比例,数据集中污染的数量,其实就是训练数据中异常数据的数量,比如数据集异常数据的比例。定义该参数值的作用是在决策函数中定义阈值。如果设置为’auto’,则决策函数的阈值就和论文中定义的一样
max_features :
int or float, optional (default=1.0)
构建每个子树的特征数,整数位个数,小数为占全特征的比例,指定从总样本X中抽取来训练每棵树iTree的属性的数量,默认只使用一个属性
如果设置为int整数,则抽取max_features个属性
如果是float浮点数,则抽取max_features * X.shape[1]个属性
bootstrap :
boolean, optional (default=False)
采样是有放回还是无放回,如果为True,则各个树可放回地对训练数据进行采样。如果为False,则执行不放回的采样。
n_jobs :
int or None, optional (default=None)
在运行fit()和predict()函数时并行运行的作业数量。除了在joblib.parallel_backend上下文的情况下,None表示为1。设置为-1则表示使用所有可用的处理器
random_state :
int, RandomState instance or None, optional (default=None)
每次训练的随机性
如果设置为int常数,则该random_state参数值是用于随机数生成器的种子
如果设置为RandomState实例,则该random_state就是一个随机数生成器
如果设置为None,该随机数生成器就是使用在np.random中的RandomState实例
verbose :
int, optional (default=0)
训练中打印日志的详细程度,数值越大越详细
warm_start :
bool, optional (default=False)
当设置为True时,重用上一次调用的结果去fit,添加更多的树到上一次的森林1集合中;否则就fit一整个新的森林
3、属性
base_estimator_
:
The child estimator template used to create the collection of fitted sub-estimators.
estimators_
:
list of ExtraTreeRegressor instances
The collection of fitted sub-estimators.
estimators_
:features_
list of ndarray
The subset of drawn features for each base estimator.
estimators_samples_
:list of ndarray
The subset of drawn samples for each base estimator.
max_samples_
:
The actual number of samples
n_features_
:
DEPRECATED: Attribute n_features_ was deprecated in version 1.0 and will be removed in 1.2.
n_features_in_
:
Number of features seen during
fit
.
feature_names_in_
:
Names of features seen during
fit
. Defined only when X has feature names that are all strings
4、方法
fit
(X[, y, sample_weight]):训练模型
decision_function
(X):返回平均异常分数
predict
(X):预测模型返回1或者-1
fit_predict
(X[, y]):训练-预测模型一起完成
get_params
([deep]):Get parameters for this estimator.
score_samples
(X):Opposite of the anomaly score defined in the original paper.
set_params
(**params):Set the parameters of this estimator.
五、应用案例
1、模型训练
有了对原理的了解,算法参数的介绍,我们就可以进行应用了,为了方便大家跑通,没有引入外部数据,直接使用简单的内置的iris 数据集作为案例。
import plotly.express as px
from sklearn.datasets import load_iris
from sklearn.ensemble import IsolationForest
data = load_iris(as_frame=True)
X,y = data.data,data.target
df = data.frame
df.head()
sepal length (cm) sepal width (cm) ... petal width (cm) target
0 5.1 3.5 ... 0.2 0
1 4.9 3.0 ... 0.2 0
2 4.7 3.2 ... 0.2 0
3 4.6 3.1 ... 0.2 0
4 5.0 3.6 ... 0.2 0
[5 rows x 5 columns]
# 模型训练
iforest = IsolationForest(n_estimators=100, max_samples='auto',
contamination=0.05, max_features=4,
bootstrap=False, n_jobs=-1, random_state=1)
# fit_predict 函数 训练和预测一起 可以得到模型是否异常的判断,-1为异常,1为正常
df['label'] = iforest.fit_predict(X)
# 预测 decision_function 可以得出 异常评分
df['scores'] = iforest.decision_function(X)
df
sepal length (cm) sepal width (cm) ... anomaly_label scores
0 5.1 3.5 ... 1 0.177972
1 4.9 3.0 ... 1 0.148945
2 4.7 3.2 ... 1 0.129540
3 4.6 3.1 ... 1 0.119440
4 5.0 3.6 ... 1 0.169537
.. ... ... ... ... ...
145 6.7 3.0 ... 1 0.131967
146 6.3 2.5 ... 1 0.122848
147 6.5 3.0 ... 1 0.160523
148 6.2 3.4 ... 1 0.073536
149 5.9 3.0 ... 1 0.169074
[150 rows x 7 columns]
# 我们看看哪些预测为异常的
df[df.label==-1]
sepal length (cm) sepal width (cm) ... anomaly_label scores
13 4.3 3.0 ... -1 -0.039104
15 5.7 4.4 ... -1 -0.003895
41 4.5 2.3 ... -1 -0.038639
60 5.0 2.0 ... -1 -0.008813
109 7.2 3.6 ... -1 -0.037663
117 7.7 3.8 ... -1 -0.046873
118 7.7 2.6 ... -1 -0.055233
131 7.9 3.8 ... -1 -0.064742
[8 rows x 7 columns]
2、模型可视化
我们可视化看看预测的结果,看看异常类型和非异常类型的直方图分布,这里最好用notebook画,其他地方画不一定能显示出来。
df['anomaly'] = df['label'].apply(lambda x: 'outlier' if x==-1 else 'inlier') fig = px.histogram(df,x='scores',color='anomaly') fig.show()
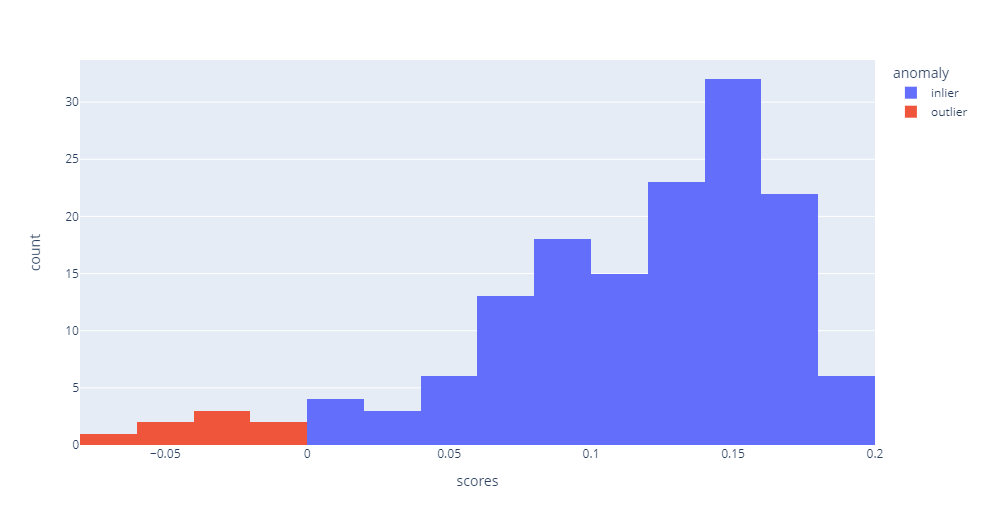
在看看3D图,红色的是比较异常的,可以看看到,还是比较准确的,但是由于这个数据本身差异性就不大,所以没那么明显,实际业务中的异常数据,一般都具有更大的差异化。
fig = px.scatter_3d(df,x='petal width (cm)',
y='sepal length (cm)',
z='sepal width (cm)',
color='anomaly')
fig.show()

六、结论
1、每棵树随机采样独立生成,所以孤立森林具有很好的处理大数据的能力和速度,可以进行并行化处理,因此可部署在大规模分布式系统上来加速运算。
2、通常树的数量越多,算法越稳定,树的深度不易过深,但不是越多越好,通过下图可以发现,当t>=100后,划分上文提到的xi和x0的平均路径长度都已经收敛了,故因此论文中推荐t设置为100。
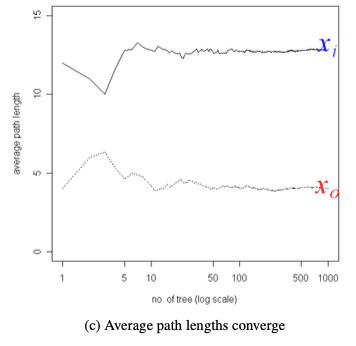
3、不同于 KMeans、DBSCAN 等算法,孤立森林不需要计算有关距离、密度的指标,可大幅度提升速度,减小系统开销;
4、为什么需要对树的高度做限制?之所以对树的高度做限制,是因为我们只关心路径长度较短的点,它们更可能是异常点,而并不关心那些路径很长的正常点