回顾一下HashMap的底层数据结构
HashMap底层实现JDK<=1.7数组+链表,JDK>=1.8数组+链表+红黑树;HashMap这一个类型底层涉及到3中数据类型,数组、链表、红黑树,其中查询速度最快的是数组,时间复杂度是O(1),链表数据量少的时候还行,数据量过大性能就一般了,它的时间复杂度是O(N),红黑树在数据量打的时候性能会比链表要好,他的时间复杂度是O(logn),这里在链表和红黑树这里性能对比其实在HashMap的扩容时,已经体现出来了,Hash值产生碰撞后,链表长度>8时会由链表转换为红黑树,而当红黑树的节点<6时,会由红黑树转换为链表,这就是二者的性能临界点。
之前有篇博客写过HashMap的源码导读,这里就不在解释了
,
详情
为什么使用数组?
速度:读、写,最快的是数组, 数组快是快,但是需要知道读、写的索引,时间复杂度是O(1),对于一般的插入、删除操作,涉及到数组元素的移动,平均时间复杂度这变为O(N),HashMap中数组的下标是通过KEY.hashCode()%数组长度得到的,但是这种方法会造成哈希碰撞,那么就有了链表这个玩意!
为什么使用链表?
这里就不过多解释了,简单说就是为了解决数据的KEY产生哈希碰撞后将原有的数组下标对应的值直接替换,那么这个时候为了解决这个问题就在产生哈希碰撞后,下标相同的KEY就会被串成链表结构,插是从头插,不是从尾,从头插时间复杂度为O(1),从尾插为O(N),这个链表是单向列表, 链表的新增,删除操作在查找到操作位置后,只需要处理节点间的引用即可,时间复杂度为O(1),但是查找操作则需要遍历链表中所有节点逐一比对,时间复杂度为O(N),这里的查询的时间复杂度为O(N)且遍历所有元素是原因数组变成链表是因为哈希碰撞的hashCode值都是一样的,那么对应的索引也是一样的,所有还要一个KEY取出来对比,所以也就有了遍历这么一说;这样的话链表过长性能会比较低,那么为了解决性能问题,JDK1.8后就引用了红黑树;
为什么使用红黑树?
这里也不过多解释了,简单说就是为了解决链表过长性能低的问题,红黑树是一种接近于平衡二叉树,但不是绝对平衡,逻辑上是个树形结构,是一个有序的结构,在每个节点上增加一个存储位,表示节点的颜色,可以是Red或者Black,通过对任何一条从根到叶子的路径上各个节点着色方式的限制,红黑树确保没有一条路径会比其他路径长出两倍,而是接近平衡的,支持查找,插入,删除,其平均时间复杂度最坏为O(logn);这里解释一下(红黑树确保没有任何一条路径会比其他路径长出两倍)
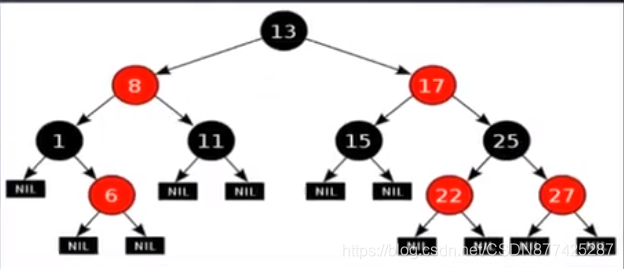
这里比如13–>17–>25–>27这条链路不会比13–>8–>1、13–>8–>11、13–>8–>1–>6、13–>17–>15、13–>17–>25–>22这些链路的路径长出两倍,因为他会自动平衡,也就是当任何一条链路的路径高出其他链路2倍是,这条链路就会自动平衡,但是如果put比较频繁,且会经常打破平衡的话,那么这条链路就会自动平衡,这时的性能就会很低,低于链表;这里平衡有两种方式,左旋、右旋
左旋:

以这个为模拟数据,现在我们来添加一个数据来打破平衡(红黑树确保没有任何一条路径会比其他路径长出两倍),现在最短的链路是50–>60,最长的是50–>40–>45–>47,现在这条最长的刚好是最短的两倍,那么这时要是再来一个49,这里49比50小,比40大,比45大,比47大,那么会挂在50–>40–>45–>47这条链路上,刚挂上去的结构是这样的,

嘿嘿,这个平衡就打破了,那么就会自动平衡,那么这种数据模型位移叫做左旋,左旋后的红黑树结构!

右旋则刚好相反!!!
这是一个
可视化HashMap操作
的工具
红黑 树有6个性质;
- 每个节点要么是红的要么是黑的
- 根节点是黑的
- 每个叶节点(叶节点指树尾端NL指针或NULL节点)都是黑的
- 如果一个节点是红的,那么他的两个子节点都是黑的
- 对于任何而言,其到节点树尾端NL指针的每条路径都包含相同数目的黑节点
- 所有的左节点都<=父节点,所有的右节点都>父节点