一、SQL增删查改基本语句的练习
1.Select
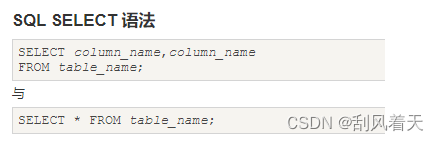
关键字:
(1)distinct:去除列中重复值 例:SELECT DISTINCT country FROM Websites;
(2)where: 筛选指定条件的记录 例:SELECT * FROM Websites WHERE id=1;
(3)Top: 取行 例:
select top 5 * from table //取前5行
select top 5 * from table order by id desc //后5行
(4)As取别名:SELECT 列名 as 新name form 表名 AS 新name;
(5)运算符:= <> <= between in not and与or:and优先级高于or

(6)like(模糊查询 %:多个 _:一个)
(7)order by: 对结果集按一个或多个列排序(默认升序),desc降序。

2.Insert
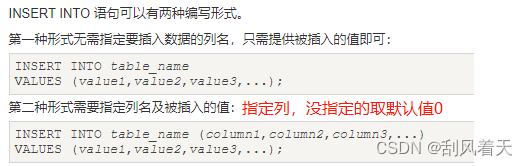
3.Update
例:
UPDATE Websites SET age='22', country='CN' WHERE name='王俊凯';(where指定需要更新的记录,否则全部更新)
4.Delete
DELETE FROM Earth WHERE name='USA' AND country='日本'; (where同上,造成全删除)
5.执行顺序

6.其他关键词
(1)UOION
(合并两个或多个 SELECT 语句的结果)
(UNION 内部的每个 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每个 SELECT 语句中的列的顺序必须相同。)
select country from websites union select country from apps; //UNION 选取不同值, UNION ALL 可选取重复的值。可再加where筛选
(2)select into from
:查询出来结果—>复制一张同结构的空表—>将数据拷贝进去
SELECT Websites.name, access_log.count //只复制一些列
INTO WebsitesBackup2016 //插入到新表
FROM Websites
LEFT JOIN access_log //复制多个表中的数据(先把表连接起来)
ON Websites.id=access_log.site_id
WHERE country='CN'; //筛选条件
select *(查询出来的结果) into newtable(新的表名)from where (后续条件)
(3)
insert into select
:指定一张想要插入数据的表格—>对数据进行加工筛选—>填入一张准备好的表格
insert into (准备好的表) select *(或者取用自己想要的结构)from 表名 where 各种条件
(3)
Drop
:删除索引、表和数据库
Alter
:在已有的表中添加、删除或修改列
(4)
视图
(基于 SQL 语句的结果集的可视化表,可向视图添加函数、WHERE等再次呈现数据。但每当用户查询视图时,数据库会使用视图的 SQL 语句重新查询最新数据,隐藏了底层的表结构,简化了数据访问操作,提供了一个统一访问数据的接口。)
创建:
creat view [数据库/表.] 视图名 [视图中的列名] AS
查询结果集(完整的查询语句)
执行: select * from 视图名 //直接把视图当成一张表
4
.
数据类型(
需要的时候再查)
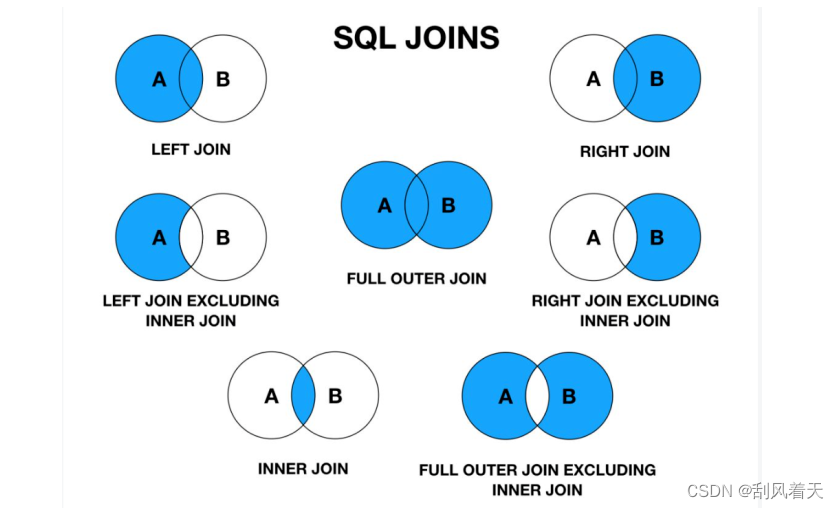
二、SQL 多表关联的学习
1.总体图

2
.
常用连接
(总之,
灵活运用
子查询、嵌套、连接)
使用 join 时,
on
和
where
条件的区别如下:
(1)、
on
条件是在生成临时表时使用的条件,它不管
on
中的条件是否为真,都会返回左边表中的记录。(但是如果没有连接条件则返回笛卡尔乘积(行*行))
(2)、
where
条件是在临时表生成好后,再对临时表进行过滤的条件。这时已经没有 left join 的含义(必须返回左边表的记录)了,条件不为真的就全部过滤掉。
内连接:两个表的交集
左外连接:左边表加两表交集
右外连接:右边表加两表交集
通过连接把不同的表连接到一起,变成一张大表,使查询操作变得简单
一、外连接
(1)左连接 left join 或 left outer join
select * from student left join score on student.Num=score.Stu_id;
(2)右连接 right join 或 right outer join
select * from student right join score on student.Num=score.Stu_id;
(3)完全外连接 full join 或 full outer join
select * from student full join score on student.Num=score.Stu_id;
(4)交叉连接:cross join-------两个表的乘积(笛卡乘积)
select * from a,b 或select * from student cross join score;
二、内连接(join 或 inner join)
内连接查询分为两类:
(1)隐式内连接 select * from A,B where 条件
(2)显式内连接 select * from A inner join B on 条件 (inner可以省略)AS(别名)
CROSS APPLY
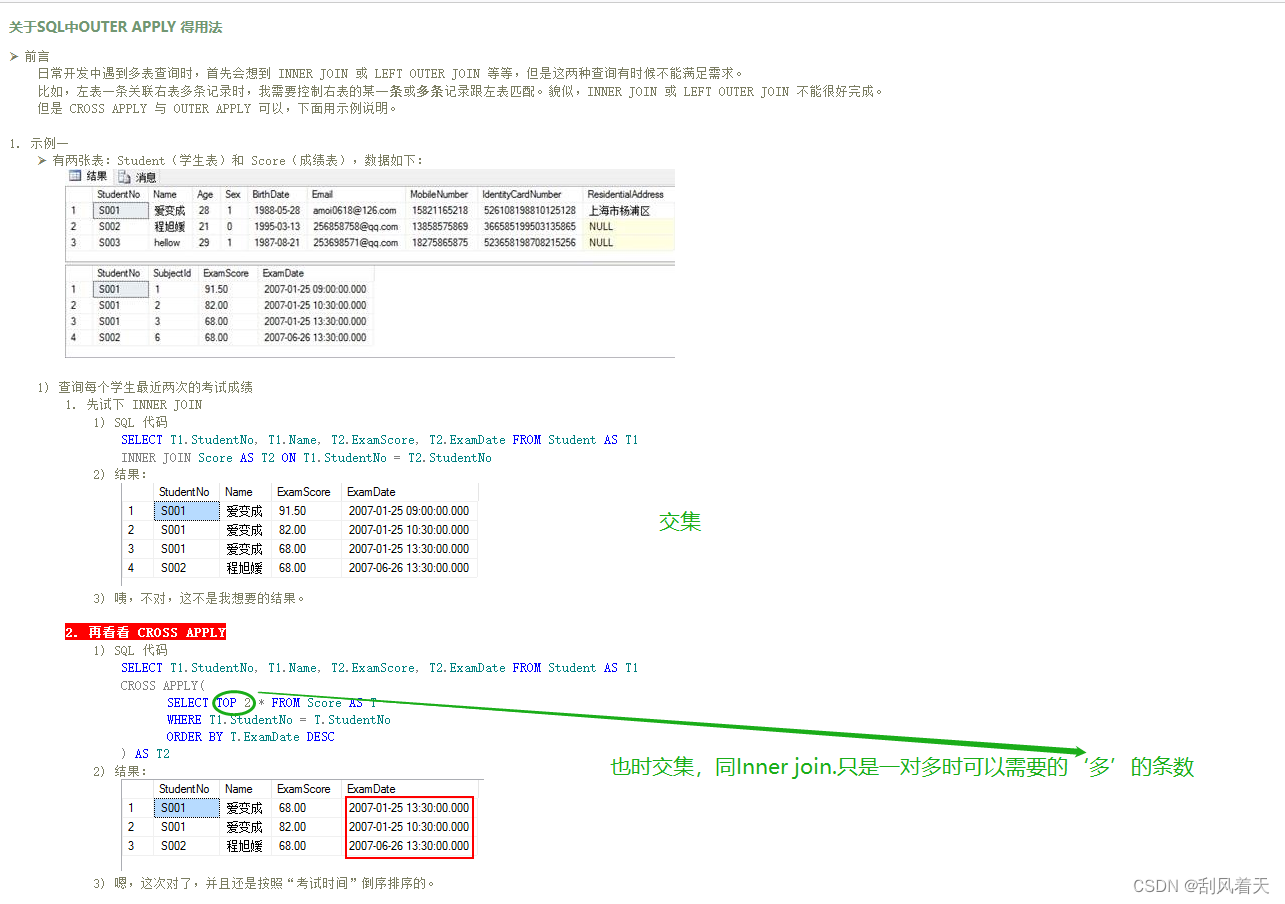
OUTER APPLY

关于SQL中OUTER APPLY 得用法 – 该吃药了 – 博客园
三、SQL 基本功能函数
1
.
聚集函数(SQL Aggregate 函数计算从列中取得的值,返回一个单一的值)
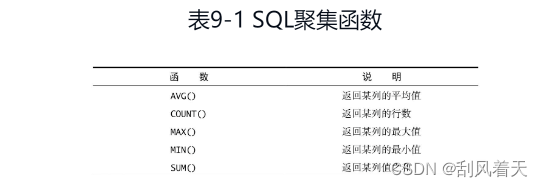
(1)Count()
select count(*) from access_log; -- 查询所有记录的条数
select count(alexa) from websites;-- 查询 alexa列中不为空的记录的条数
select count(distinct country) from websites;-- 查询country列中不重复的记录条数(2)取第一行、最后一行
SELECT TOP 1 column_name FROM table_name ORDER BY column_name DESC;
2
.
分组聚合
(1)注意使用顺序
SELECT id,Sum(boyfirend)
FROM table
WHERE age < 25
GROUP BY id /根据id来重新分组(相同的为一组,然后再计算组中的SUM)
HAVING Sum(boyfirend) >10 ; //聚合函数不能作为条件放在where(过滤行)之后,但可放having(过滤分组)后
3
.
Scalar
函数(基于输入值,返回一个单一的值)
(1) SELECT UPPER(列名) AS site_title FROM Websites; //把选择的列,将其中的值转换为大写,小写LOWER()
(2) SELECT MID(列名id,起始位置(下标从1开始),结束位置) AS 新列名 FROM table; //把选择的列,提取出需要的值
(3) SELECT LEN(列名) FROM table; //把选择的列,返回文本字段中值的长度
(4) SELECT ROUND(列,要保留的小数位数) FROM TABLE; //把指定列的值,四舍五入为指定的小数位数
(5) SELECT DATE_FORMAT(Now(),'%Y-%m-%d') AS date FROM Table; //NoW返回当前系统的日期和时间,DATE_FORMAT对数据格式化。4.其他·函数 (1)EXISTS 运算符用于判断查询子句是否有记录,如果有一条或多条记录存在返回 True,否则返回 False
四、SQL 存储过程的学习
1
.存储过程
意义
(1)增强了代码的复用率和共享性
(2)存储过程存储在服务器上,并在服务器上运行,减少了网络中数据的流量
(3)只在创建时进行编译,以后每次执行存储过程都不需再重新编,加快了过程的运行速度
(4)加强了系统的安全性,提高了处理复杂任务的能力。
2
.常用系统存储过程
(1)sp_helpdb:用于查看数据库名称及大小
(2)sp_helptext:用于显示规则、默认值、未加密的存储过程、用户定义函数、触发器或视图的文本。
(3)sp_helplogins:查看所有数据库用户登录信息。
(4)sp_helpsrvrolemember:用于查看所有数据库用户所属的角色信息。
附:临时存储过程,以“#”局部临时或“##”局部临时为前缀
3
.用户自定义存储过程
(1)存在一些错误,具体深入学习需要到实际代码中


4.SQL 触发器的学习
(1).概念:是响应数据操作语言(DML)事件或数据定义语言(DDL)事件而执行的特殊类型的存储过程,是在用户对某一表中的数据进行UPDATE、INSERT和DELETE操作时被触发执行的一段程序。
(2).类别:
(1)DML触发器:是在执行INSERT、UPDATE或DELETE语句时被激活的触发器
(2)DDL触发器:是在执行CREATE、ALTER和DROP语句时被激活的触发器,是由数据定义语言引起的
(3).作用:保证数据库复杂的参照完整性和数据的一致性(数据库内存中两个特殊表:插入表inserted、删除表deleted(触发器执行过程中所有记录都会写入到两个对应的表中,并且用户只有只读权限,触发器完成工作后,这两个表将从内存中删除))
(4).注意事项:
<1>CREATE TRIGGER语句必须是批处理中的第一个语句,且只能用于一个表或视图。
<2>创建触发器的权限默认分配给表的所有者,且不能将该权限转给其他用户。
<3>触发器可以引用当前数据库以外的对象,但只能在当前数据库中创建触发器。
<4>不能在临时表或系统表上创建触发器,但是触发器可以引用临时表。不应引用系统表,而应使用信息架构视图。
<5>在含有用DELETE或UPDATE操作定义的外键表中,不能定义INSTEAD OF和INSTEAD OF UPDATE触发器。
(5).创建
(1)DML模板
REATE TRIGGER (触发器名字) ON (表/视图) FOR/AFTER/INSTEAD OF (insert/update/delete) AS
BEGIN
declare @t int
insert......
if(....)
END(2)DDL模板
USE (数据库)
CREATE TRIGGER (触发器名字) ON (数据库...) FOR/AFTER/INSTEAD OF (CREATE/ALTER/DROP) AS
BEGIN
print '不允许修改、删除操作'
rollback transaction
END
5.SQL 视图的学习
1.视图(基于 SQL 语句的结果集的可视化表,可向视图添加函数、WHERE等再次呈现数据。但每当用户查询视图时,数据库会使用视图的 SQL 语句重新查询最新数据,隐藏了底层的表结构,简化了数据访问操作,提供了一个统一访问数据的接口。)
(1)创建:
creat view [数据库/表.] 视图名 [视图中的列名] AS
查询结果集(完整的查询语句)
(2)执行: select * from 视图名 //直接把视图当成一张表