参考:https://github.com/huggingface/peft
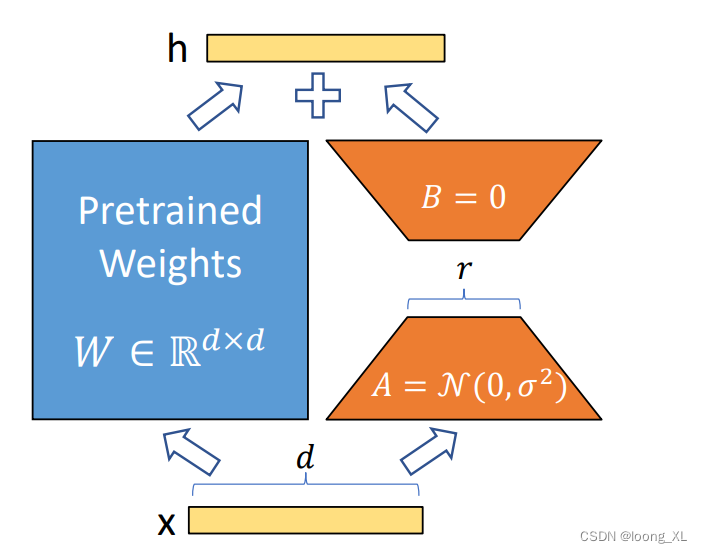
一般用于大模型微调,下面案例是用于文本nlp模型
**可以安装peft库,里面封装了lora
import argparse
import os
import torch
from torch.optim import AdamW
from torch.utils.data import DataLoader
from peft import (
get_peft_config,
get_peft_model,
get_peft_model_state_dict,
set_peft_model_state_dict,
LoraConfig,
PeftType,
PrefixTuningConfig,
PromptEncoderConfig,
)
import evaluate
from datasets import load_dataset
from transformers import AutoModelForSequenceClassification, AutoTokenizer, get_linear_schedule_with_warmup, set_seed
from tqdm import tqdm
batch_size = 32
model_name_or_path = "roberta-large"
task = "mrpc"
peft_type = PeftType.LORA
device = "cuda"
num_epochs = 10
if any(k in model_name_or_path for k in ("gpt", "opt", "bloom")):
padding_side = "left"
else:
padding_side = "right"
##加载tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, padding_side=padding_side)
if getattr(tokenizer, "pad_token_id") is None:
tokenizer.pad_token_id = tokenizer.eos_token_id
##加载微调数据
datasets = load_dataset("glue", task)
metric = evaluate.load("glue", task)
def tokenize_function(examples):
# max_length=None => use the model max length (it's actually the default)
outputs = tokenizer(examples["sentence1"], examples["sentence2"], truncation=True, max_length=None)
return outputs
tokenized_datasets = datasets.map(
tokenize_function,
batched=True,
remove_columns=["idx", "sentence1", "sentence2"],
)
# We also rename the 'label' column to 'labels' which is the expected name for labels by the models of the
# transformers library
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
def collate_fn(examples):
return tokenizer.pad(examples, padding="longest", return_tensors="pt")
# Instantiate dataloaders.
train_dataloader = DataLoader(tokenized_datasets["train"], shuffle=True, collate_fn=collate_fn, batch_size=batch_size)
eval_dataloader = DataLoader(
tokenized_datasets["validation"], shuffle=False, collate_fn=collate_fn, batch_size=batch_size
)
##lore模型配置及融合进原模型
peft_config = LoraConfig(task_type="SEQ_CLS", inference_mode=False, r=8, lora_alpha=16, lora_dropout=0.1)
lr = 3e-4
model = AutoModelForSequenceClassification.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
##加优化器进行训练
optimizer = AdamW(params=model.parameters(), lr=lr)
# Instantiate scheduler
lr_scheduler = get_linear_schedule_with_warmup(
optimizer=optimizer,
num_warmup_steps=0.06 * (len(train_dataloader) * num_epochs),
num_training_steps=(len(train_dataloader) * num_epochs),
)
# model.to(device) ##GPU上运行
for epoch in range(num_epochs):
model.train()
for step, batch in enumerate(tqdm(train_dataloader)):
# batch.to(device) ##GPU上运行
outputs = model(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
model.eval()
for step, batch in enumerate(tqdm(eval_dataloader)):
# batch.to(device) ##GPU上运行
with torch.no_grad():
outputs = model(**batch)
predictions = outputs.logits.argmax(dim=-1)
predictions, references = predictions, batch["labels"]
metric.add_batch(
predictions=predictions,
references=references,
)
eval_metric = metric.compute()
print(f"epoch {epoch}:", eval_metric)
##保存lore模型
tokenizer.save_pretrained('roberta-large-lore')
model.save_pretrained('roberta-large-lore')
训练过程
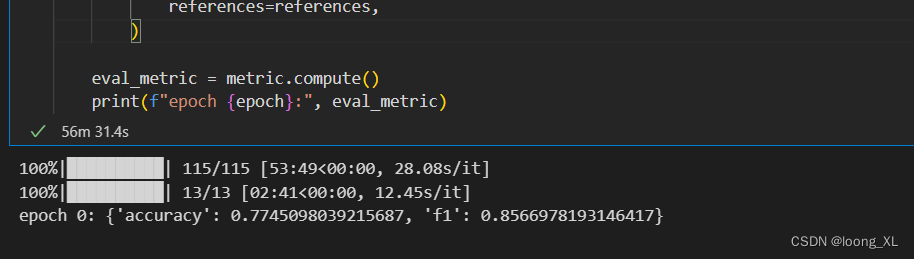
保存的模型
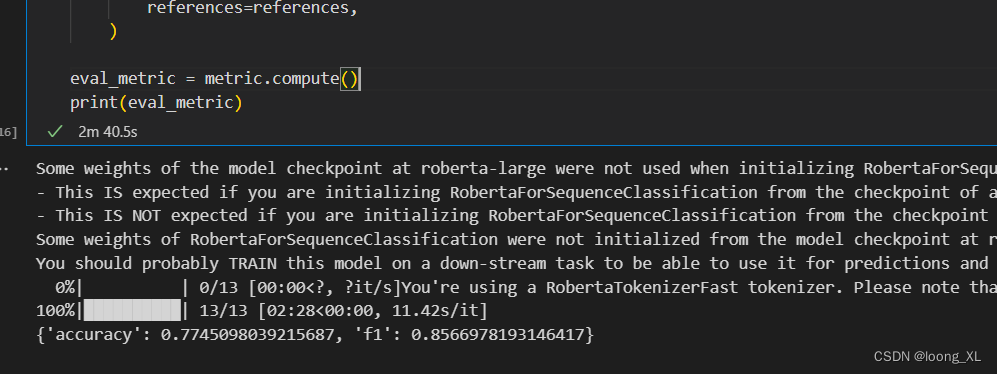
加载lore推理
import torch
from peft import PeftModel, PeftConfig
from transformers import AutoModelForCausalLM, AutoTokenizer
peft_model_id = "roberta-large-lore" ##上面保存lore模型的文件夹
config = PeftConfig.from_pretrained(peft_model_id)
inference_model = AutoModelForSequenceClassification.from_pretrained(config.base_model_name_or_path)
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
# Load the Lora model
inference_model = PeftModel.from_pretrained(inference_model, peft_model_id)
# inference_model.to(device) ##GPU上运行
inference_model.eval()
for step, batch in enumerate(tqdm(eval_dataloader)):
# batch.to(device) ##GPU上运行
with torch.no_grad():
outputs = inference_model(**batch)
predictions = outputs.logits.argmax(dim=-1)
predictions, references = predictions, batch["labels"]
metric.add_batch(
predictions=predictions,
references=references,
)
eval_metric = metric.compute()
print(eval_metric)
加载案例2:
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
from peft import PeftModel
tokenizer = AutoTokenizer.from_pretrained("baichuan-inc/baichuan-7B", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/baichuan-7B", device_map="auto", trust_remote_code=True)
model = PeftModel.from_pretrained(model, "hiyouga/baichuan-7b-sft")
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
query = "晚上睡不着怎么办"
inputs = tokenizer(["<human>:{}\n<bot>:".format(query)], return_tensors="pt")
inputs = inputs.to("cuda")
generate_ids = model.generate(**inputs, max_new_tokens=256, streamer=streamer)
参考:https://zhuanlan.zhihu.com/p/638058537
from peft import PeftModel
from transformers import GenerationConfig, LlamaForCausalLM, LlamaTokenizer
import torch
# create tokenizer
base_model = "timdettmers/guanaco-33b-merged"
tokenizer = LlamaTokenizer.from_pretrained(base_model)
# base model
model = LlamaForCausalLM.from_pretrained(
base_model,
torch_dtype=torch.float16,
device_map="auto",
)
# LORA PEFT adapters
adapter_model = "lyogavin/Anima33B"
model = PeftModel.from_pretrained(
model,
adapter_model,
#torch_dtype=torch.float16,
)
model.eval()
# prompt
prompt = "中国的首都是哪里?"
inputs = tokenizer(prompt, return_tensors="pt")
# Generate
generate_ids = model.generate(**inputs, max_new_tokens=30)
print(tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0])
# output: '中国的首都是哪里?\n中国的首都是北京。\n北京位于中国北部,是中国历史悠'
版权声明:本文为weixin_42357472原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。