首先,我们在介绍DDL之前,先让我们来了解一下hive的那些database,table,partition,bucket在hdfs上面是怎么样展示的。这四个里面前三个在hdfs上面都是文件夹,而具体的数据就是存储在文件里面的,所以当我们添加数据进去的时候实际上就是往这个表所代表的文件夹里面添加文件。
另外,我们也知道,在hive刚搭建好的时候里面就有一个默认的数据库了default,它在hdfs上面的默认地址是/user/hive/warehouse这个路径的,是直接由参数hive.metstore.warehouse.dir这个参数来控制的。如果你想查看的话,可以在hive里面输入命令:set hive.metastore.warehouse.dir。如果同时想修改的话,就直接在后面跟上=和你要给的值,就直接赋值就好了。
但是,你所创建的数据库在hdfs上面的路径也是在/user/hive/warehouse这个个路径下的,比如:你创建了一个tmp_db的数据库,那么它的默认路径就是${hive.metastore.warehouse.dir}/tmp_db.db。也就是说,在hive里面和default同级的数据库在hdfs里面不是平行目录的。
DDL(Database Definition Language):
其实DDL就是对数据库,表等数据单元的创建/删除/更改呗。这里是hive关于DDL的官网,大家可以去阅读一下:
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL
创建数据库:create database if not exists db_name [comment …] [location …] [with dbproperties(…)]; 这里面用[]括起来的是可选项,你可以不加comment(这是备注),location(重新选择在hdfs上面的存储路径),dbproperties()(这个就是记录一些key-value对,用于记录创建人,时间等自定义信息的)

创建完数据库后,我们想看下数据库具体desc database db_name这个命令

但是不是很详细,那么我们就加点参数进去吧。desc database extended db_name;

好了,创建完数据库以后,我们就要开始在数据库里面创建表了,但在创建表之前,我们先来认识一下hive里面的数据结构。和MySQL类似的就是一些数值类型(主要是tinyint,int,bigint,double,float等),字符型(string和MySQL有点不同),还有就是一些数组什么的。其实在大数据当中我们都是习惯将时间什么的存储成string类型的还有boolean是存储成tinyint类型的。详细的数据类型:
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Types
创建表:
Hive是构建在Hadoop之上的hive创建表自然也是存储在HDFS之上的,一般存储在hdfs的是文本文件,格式多是这样:
zhangsan,20,g,beijing,这样的数据我们在表格当中是以name age gender location这样的字段来记录的,所以我们在hive里面建表需要定义好对文件内容的分隔符。
create table table_name( col_name data_type, …) row format delimited fields terminated by xxx;这里的xxx指的是一种分隔符
我们也可以通过命令desc formatted table_name来查看一下一个表的具体信息

从图中我们可以看到表的字段列表,所属数据库,在hdfs上面的路径,表格类型等。当这个时候这张表还是空的,我们需要导入数据,我在hdfs上面已经上传了一个emp.txt的文件,路径在/user/datauser/test_data这个路径上,我们先使用DML的语句来完成这个导入数据(具体的DML语法后面的博文会细讲)

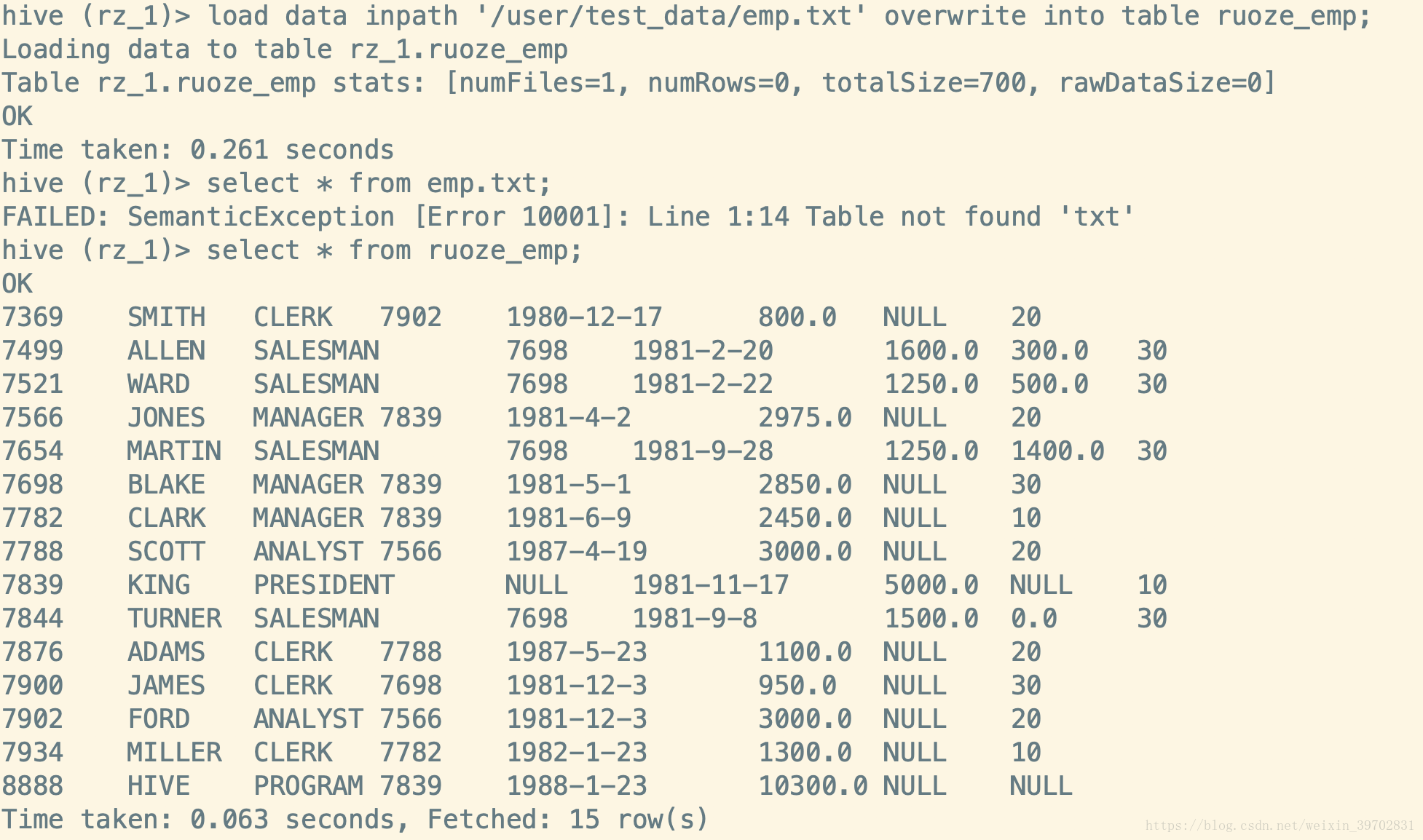
这个时候,我们去看下这个表所对应的hdfs上面的地址是不是多了一个文件,以及原来存放这个数据文件的地址有什么变化

从图中可以看到,在ruoze_emp这个表所对应的hdfs路径(/user/hive/warehouse/rz_1.db)上多了一个emp.txt这个文件,而在原来这个文件所在的hdfs目录里emp.txt这个文件不见了。所以,我们可以得出的结论是当使用load data这中方法从hdfs上面导入文件数据的话相当于剪切,就是将原来的数据文件mv到表格所对应的文件夹下面。
除了这样的方法来创建表格意外,我们在生产上有时候需要仿照一个已经存在的表的表结构来创建一个新表,这个时候的语法是:create table t2 like t1;其中,t1表是已存在了。
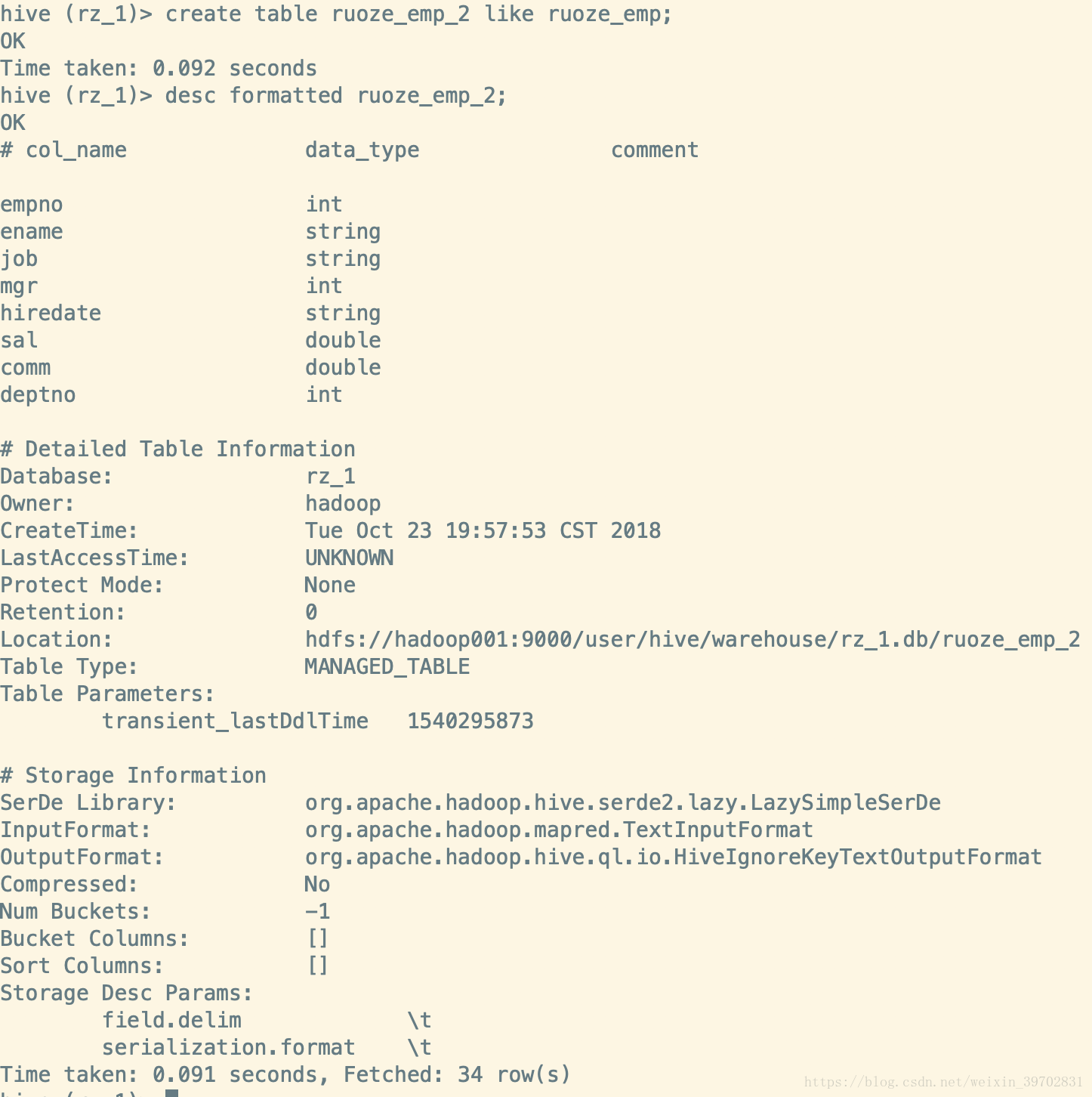
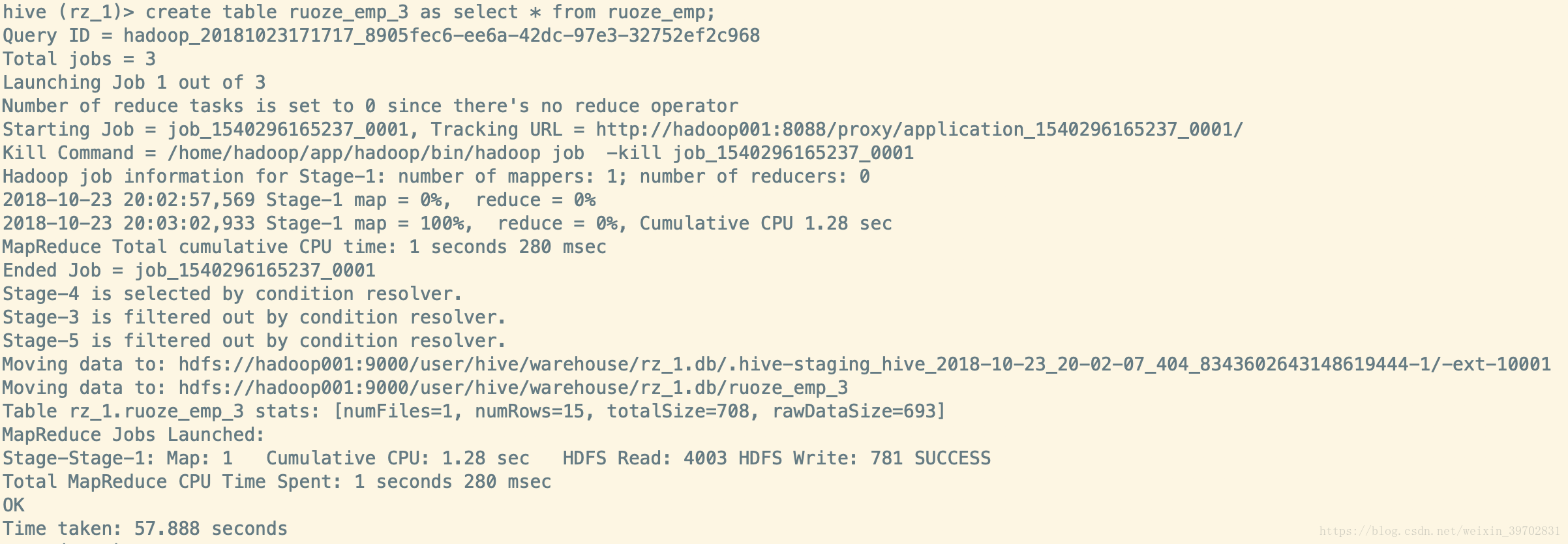
ruoze_emp_2这个表的字段列表是和ruoze_emp这个表的字段列表是一摸一样的。还有一种方法是在按照前表的结构创建的同时,还把前表的数据copy过去的语句,create table t3 as select * from t1;这个过程是要跑mapreduce作业的,所以你的yarn是要启起来的。

现在,我们尝试一下创建一个dept表,然后我们直接使用hdfs shell命令将这个表的数据put到其hdfs路径之上,看看能不能读取。

看到了吗,这也是可以导入数据的,如果是这样可以导入数据的话,那么你也可以直接在hdfs上面导出数据,即使使用hdfs shell的命令就可以拉取数据到本地了。
内部表和外部表的区别
刚才我们所创建的表都是内部表,什么是内部表呢?就是这个表的整个生命周期都是又hive来管理的,如果你删除这个表的话,那么hdfs上面的数据也将被删除,表对应的hdfs上面的路径也被删除了,MySQL上面的元数据也没了。而外部表就是只删除MySQL上面的元数据,hdfs上面的路径和数据都还在,所以我们一般在创建外部表的时候也同时会指定一个hdfs数据存储的路径给他,不再使用默认情况。语法:create external table tab_name … …后面一样

所以,一般产生上我们都是使用外部表来存储数据,万一哪天手一抖误删了内部表就连数据也一起删了。