前言
上一篇简要介绍了关于RapidMiner的简要介绍以及
预测分析中决策树的小小实践
。这次也是利用同样的数据集实现预测分析,最终看看预测效果如何。
朴素贝叶斯
原理
获取更多与结果Y相关的因素X信息。依本人理解,就是通过对目前已有条件X的理解分析(根据概率),来判断结果Y。
Step
- 计算各结果先验概率P(Y)
- 计算P(Xi|Y),即发生某结果前提下,因素(属性)为某数值的概率。
- 对每个结果都计算P(X|Yj)P(Yj)
- 选择P(X|Yj)P(Yj)值最大的结果为预测结果

我们根据上一篇中数据集Golf中数据理解。
- 计算先验概率P(Yes)和P(No) 。
- 以outlook举例,计算P(overcast|Yes),P(rain|Yes),P(sunny|Yes)。计算P(overcast|No),P(rain|No),P(sunny|No)。同其他属性。
- 以outlook举例,计算P(Yes)P(overcast|Yes)P(rain|Yes)P(sunny|Yes)和P(No)P(overcast|No)P(rain|No)P(sunny|No)。同其他属性。
- 选择步骤3中最大的结果为预测结果。
RapidMiner实现贝叶斯分类器预测
数据:
Sample中data>Golf和Golf-testset
按照下图中在operator窗口搜索相关算子,构建流程。
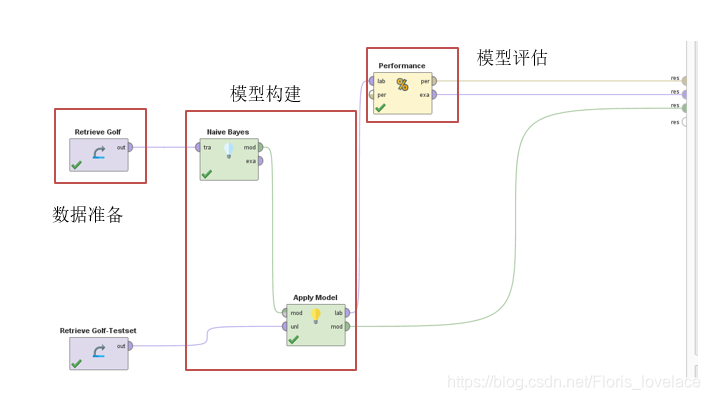
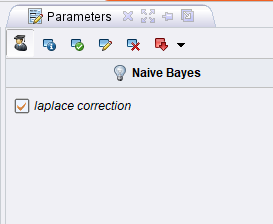
注意
:一定要勾选参数Laplace correction。为防止出现零时相乘结果为零的情况出现。
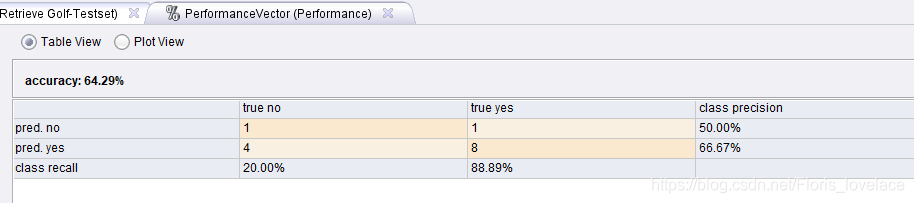
实验结果:
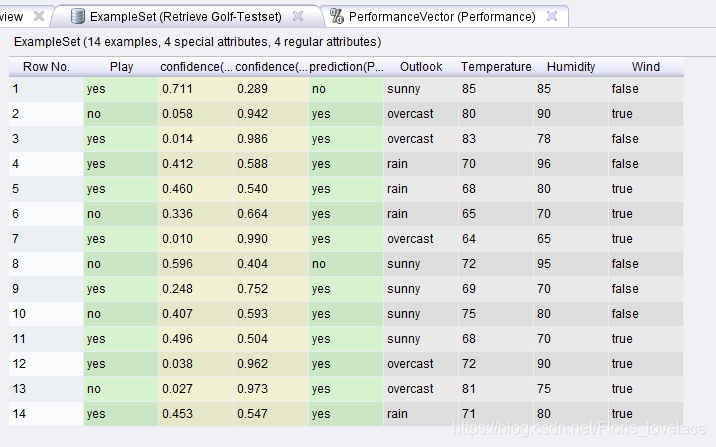
预测效果,也不是很好啊哈哈哈,数据集有限啊。
下篇预告:
RapidMiner介绍与实践(三)K-means算法
下一篇会简要介绍下如何利用K-means算法区分经典鸢尾花数据集iris dataset。
如有任何问题,欢迎共同交流~
版权声明:本文为Floris_lovelace原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。