实验三 梯形法求积分
1. 实验目的和要求
梯形法求积分
2.实验环境
安装了docker的PC
3.实验内容及实验数据记录
梯形法求积分
a. mpi_send, 0 for sum
b. mpi_gather, 回收到0号进程的数组,for sum
c. mpi_reduce, MPI_SUM求和
4.算法描述及实验步骤
第一:写函数double f(double x)和double Trap(double left_endpt,double right_endpt,int trap_count,double base_len)来计算pi

第二:进程 0输入a,b和n,且进程0把a,b,n发送给剩余进程
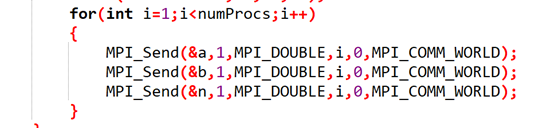
第三:各个进程接收

第四:计算h,每个进程需处理的长度local_n,还有每个进程的起始位置local_a和终点位置local_b
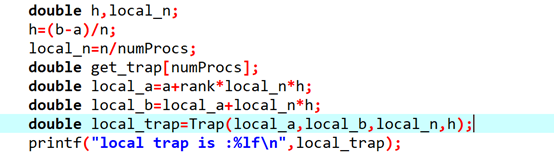
第五:用mpi_reducem ,mpi_gatherp ,mpi_send接收total_trap

第六:由进程0打印且求和

5.调试过程
注意大小写
6. 实验结果

7.代码
#include<stdio.h>
#include<string.h>
#include<mpi.h>
double f(double x)
{
double y;
y=4/(1+x*x);
return y;
}
double Trap(double left_endpt,double right_endpt,int trap_count,double base_len)
{
double estimate,x;
estimate=(f(left_endpt)+f(right_endpt))/2.0;
for(int i=1;i<trap_count;i++)
{
x=left_endpt+i*base_len;
estimate+=f(x);
}
estimate=estimate*base_len;
return estimate;
}
int main(int argc,char **argv)
{
int numProcs,rank;
double a,b,n;
MPI_Status status;
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD,&numProcs);
MPI_Comm_rank(MPI_COMM_WORLD,&rank);
if(rank==0)
{
printf("Please input a,b,n\n");
scanf("%lf%lf%lf",&a,&b,&n);
for(int i=1;i<numProcs;i++)
{
MPI_Send(&a,1,MPI_DOUBLE,i,0,MPI_COMM_WORLD);
MPI_Send(&b,1,MPI_DOUBLE,i,0,MPI_COMM_WORLD);
MPI_Send(&n,1,MPI_DOUBLE,i,0,MPI_COMM_WORLD);
}
}
else
{
MPI_Recv(&a,1,MPI_DOUBLE,0,0,MPI_COMM_WORLD,MPI_STATUS_IGNORE);
MPI_Recv(&b,1,MPI_DOUBLE,0,0,MPI_COMM_WORLD,MPI_STATUS_IGNORE);
MPI_Recv(&n,1,MPI_DOUBLE,0,0,MPI_COMM_WORLD,MPI_STATUS_IGNORE);
}
double h,local_n;
h=(b-a)/n;
local_n=n/numProcs;
double get_trap[numProcs];
double local_a=a+rank*local_n*h;
double local_b=local_a+local_n*h;
double local_trap=Trap(local_a,local_b,local_n,h);
printf("local trap is :%lf\n",local_trap);
double total_trap;
MPI_Reduce(&local_trap,&total_trap,1,MPI_DOUBLE,MPI_SUM,0,MPI_COMM_WORLD);
MPI_Gather(&local_trap,1,MPI_DOUBLE,get_trap,1,MPI_DOUBLE,0,MPI_COMM_WORLD);
MPI_Send(&local_trap,1,MPI_DOUBLE,0,99,MPI_COMM_WORLD);
if(rank==0)
{
printf("Use Reduce:Integral from %.0f to %.0f = %lf\n",a,b,total_trap);
total_trap=0;
for(int i=0;i<numProcs;i++)
total_trap+=get_trap[i];
printf("Use Gather:Integral from %.0f to %.0f = %lf\n",a,b,total_trap);
total_trap=0;
for(int i=0;i<numProcs;i++)
{
MPI_Probe(MPI_ANY_SOURCE,99,MPI_COMM_WORLD,&status);
MPI_Recv(get_trap+status.MPI_SOURCE,1,MPI_DOUBLE,status.MPI_SOURCE,99,MPI_COMM_WORLD,&status);
}
for(int i=0;i<numProcs;i++)
total_trap+=get_trap[i];
printf("Use Send:Integral from %.0f to %.0f = %lf\n",a,b,total_trap);
}
MPI_Finalize();
return 0;
}
版权声明:本文为qq_43705330原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。