实验说明
实验的目标是使用简化版的带内遥测(INT)扩展基本L3转发,我们称之为多跳路有检查(MRI)。
MRI可以追踪数据包转发路径和队列长度。为了支持这个功能,我们需要编写P4程序,将一个ID和队列长度添加到每个数据包的头堆栈。Switch ID的顺序相当于路径,每一个ID后面跟随着端口队列长度。
和之前的实验一样,我们已经定义好了控制平面,所以实验只需要关注P4数据平面的逻辑。
虚拟的安装使用参考:
P4 Tutorial 安装
步骤一:运行(不完整)初始代码
mri.p4只是初步实现了L3转发功能,我们的任务是扩展代码,使其能够自定义支持MRI的报文头。
-
首先编译不完整的mri.p4,并在mininet中启动Switch。

这一步包括:
- 编译mri.p4,
- 启动mininet实例的3个Switches,5个hosts,拓扑图如下:
-
控制平面根据sx-runtime.json文件对每个Switch的tables编程。

-
我们从h1到h2发送低速流,通过iperf从h11到h22发送高速流。在topology.json中我们设定了s1和s2之间的带宽为512kbps,这将成为转发上的瓶颈。
-
在mininet下打开h1,h11,h2,h22的终端:

-
h2作为server收包:
-
h22作为iperf UDP服务端:
-
h1发送数据包到h2,每秒一个包,发送30秒:
-
h11 作为iperf UDP客户端发包15秒:

-
在h2,MRI header没有路径信息 (count=0)。

-
exit 退出xterm。
我们能在h2收到消息,但是没有关于路径信息的消息。后面我们扩展mri.p4,实现MRI逻辑记录路径信息。
步骤二:实现MRI
mri.p4是一个框架,我们需要把代码中TODO部分替换。
MRI需要两个自定义header,第一:mri_t,包括count,它表示Switch ID的数目;第二:switch_t,包括Switch ID和每个途径Switch的队列长度。
实现MRI的做大挑战是处理两个headers的递归逻辑。我们将使用 parser_metadata字段,追踪需要解析的switch_t header。在parse_mri状态,这个字段设置为 hdr.mri.count。在parse_swtrace 状态,这个字段应该递减。 parse_swtrace 状态将循环直到remaining 0。
MRI自定义的header将携带在IP Option报头内。IP Option包含一个字段option,该字段指示选项类型,我们用特殊类型31表示MRI头存在。
除了parser逻辑,我们在出口添加一个table,swtrace存储Switch ID和队列长度以及增加计数的action,并追加到switch_t header。
完成mri.p4, 包括以下部分:
- 定义header类型 Ethernet (ethernet_t), IPv4 (ipv4_t), IP Options (ipv4_option_t), MRI (mri_t), Switch (switch_t)。
- 解析Ethernet, IPv4, IP Options, MRI, and Switch,parser将填充ethernet_t, ipv4_t, ipv4_option_t, mri_t, and switch_t。
- 使用mark_to_drop()丢弃数据包。
- action ipv4_forward包括:为下一跳设置出口端口,用下一跳的地址更新以太网目标地址,用交换机的地址更新以太网源地址,减少TTL。
- ingress control包括:定义一个table,读取IPv4目的地址,调用drop或ipv4_forward,应用table。
- 在egress,action add_swtrace添加Switch ID和队列长度。
- egress control应用swtrace table存储Switch ID和队列长度,调用add_swtrace。
- 逆解析器:选择字段插入到传出数据包中的顺序。
- package:与parser,control,checksum verification,recomputation,deparser一起提供包的实例化。
步骤三:执行解决方案
我们可以先复制出solution目录里的mri.p4,这是提前准备好的准确答案。
按照步骤一的操作,这次我们可以看到h1到h2的数据包Switch序列和丢列长度。
可以和步骤一时h2的截图做下对比。
至此实现了实时监控数据流途径节点以及节点的拥塞情况。
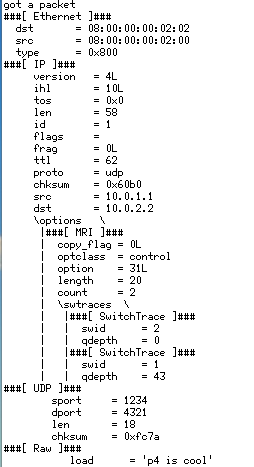
因为s1到s2的带宽瓶颈,所以s1出向会占用队列缓存。
如果有兴趣,还可以登录到s1上去调整队列缓存的最大值,再做发包测试一下。
Switch 操作命令:
登录s1:
simple_switch_CLI –thrift-port 9090
设置端口3队列缓存40pkts:
set_queue_depth 40 3