问题描述

今天在用YOLOv5训练模型的时候发现报错:
RuntimeError:CUDA error:out of memory
查了一下百度的方法 是在Python文件(你要运行哪个就设置哪个,当然也可也通过环境变量统一设置)中手动设置调用GPU的编号
import os
os.environ["CUDA_VISIBLE_DEVICES"] = '1'
结果就是可以跑起来但是根本不调用GPU,所以速度奇慢无比。
(经后来分析因为我使用的云服务器只有一个卡能用,所以默认为0,设置成1应该也是在用0号)

可以看到gpu_mem为0,通过命令
nvidia-smi
查看后台GPU并没有被占用
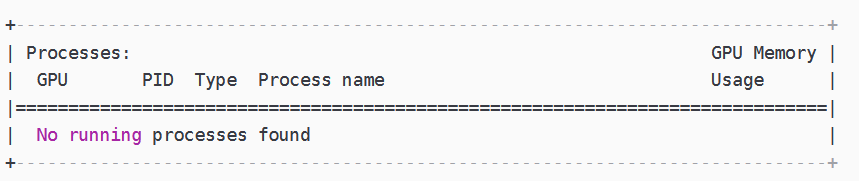
这似乎就奇了怪了,网上一般都是以上的方法,还有修改cfg文件的方式(关键字 修改subdivisions )但是因为查到都是在YOLOv3的文件里修改,在YOLOv5里我没找到,修改batch-size也没有用,这时候就一筹莫展。
解决方案
终极解决方案就是
重新配置了一个实例!
将之前不能使用的主机镜像保存,然后重新配置一个实例,之后将镜像加载进去,之后就可以正常运行了!
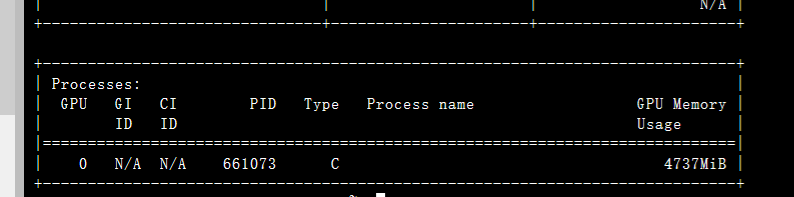
再次训练gpu_mem不再是0

通过命令查看后台也不再是
No running processes found
虽然说这样问题就解决了,但这个问题解决的前提是我使用了租赁的云服务器并且可以
方便重新配置并更换镜像
的前提下,如果是其他情况下可能上边的
os.environ["CUDA_VISIBLE_DEVICES"] = '1'
的方法更适用,但也许还有其他的办法,真正出现这个问题的原因我还没有明白,希望有大佬可也赐教,有更好的解决方案。
最后推荐一下我使用的服务器平台AutoDL,感觉价格挺良心,初次使用有免费的金额可以白嫖,挺适合学生的感觉,感兴趣可以点击链接注册了解一下:
AutoDL注册