内存屏障是一种底层原语,在不同计算机架构下有不同的实现细节。本文主要在x86_64处理器下,通过Linux及其内核代码来分析和使用内存屏障
对大多数应用层开发者来说,“内存屏障”(memory barrier)是一种陌生,甚至有些诡异的技术。实际上,他常被用在操作系统内核中,用于实现同步机制、驱动程序等。
利用它,能实现高效的无锁数据结构,提高多线程程序的性能表现。本文首先探讨了内存屏障的必要性,之后介绍如何使用内存屏障实现一个无锁唤醒缓冲区(队列),用于在多个线程间进行高效的数据交换。
程序实际运行时很可能并不完全按照开发者编写的顺序访问内存。例如:
x = r;
y = 1;
这里,y = 1很可能先于x = r执行。这就是
内存乱序访问
。内存乱序访问行为出现的理由是为了提升
程序运行时的性能
.
编译器
和
CPU
都可能引起
内存乱序访问
:
编译时,编译器优化进行
指令重排
而导致内存乱序访问;
运行时,
多CPU间交互
引入内存乱序访问。
编译器和CPU引入内存乱序访问通常不会带来什么问题,但在一些特殊情况下(主要是
多线程程序中
),
逻辑的正确性
依赖于
内存访问顺序
,这时,内存乱序访问会带来逻辑上的错误,例如:
// thread 1
while(!ok);
do(x);
// thread 2
x = 42;
ok = 1;
ok初始化为0, 线程1等待ok被设置为1后执行do函数。假如,
线程2
对内存的
写操作乱序执行
,也就是
x赋值晚于ok赋值
完成,那么do函数接受的实参很有可能出乎开发者的意料,不为42。
我们可以引入内存屏障来避免上述问题的出现。内存屏障能让
CPU或者编译器
在
内存访问上有序
。一个内存屏障之前的内存访问操作必定先于其之后的完成。内存屏障包括两类:
编译器屏障
和
CPU内存屏障
。
编译器对代码做出优化时,可能改变
实际执行指令的顺序
(例如g++下O2或者O3都会改变实际执行指令的顺序),看一个例子:
int x, y, r;
void f()
{
x = r;
y = 1;
}首先直接编译次源文件:g++ -S test.cpp。我们得到相关的汇编代码如下:
movl r(%rip), %eax
movl %eax, x(%rip)
movl $1, y(%rip)
这里我们可以看到,x = r和y = 1并
没有乱序执行
。
现使用
优化选项
O2(或O3)编译上面的代码(g++ -O2 –S test.cpp),生成汇编代码如下:
movl r(%rip), %eax
movl $1, y(%rip)
movl %eax, x(%rip)我们可以清楚地看到经过编译器优化之后,movl $1, y(%rip)先于movl %eax, x(%rip)执行,这意味着,编译器优化导致了内存乱序访问。避免次行为的办法就是使用编译器屏障(又叫优化屏障)。Linux内核提供了函数barrier(),用于让编译器保证其之前的内存访问先于其之后的内存访问完成。(这个强制保证顺序的需求在哪里?换句话说乱序会带来什么问题内? – 一个线程执行了 y =1 , 但实际上x=r还没有执行完成,此时被另一个线程抢占,另一个线程执行,发现y=1,以为此时x必定=r,执行相应逻辑,造成错误)内核实现barrier()如下:
#define barrier() __asm__ __volatile__("": : :"memory")现在把此编译器barrier加入代码中:
int x, y, r;
void f()
{
x = r;
__asm__ __volatile__("": : :"memory")
y = 1;
}再编译,就会发现内存乱序访问已经不存在了。除了barrier()函数外,本例还可以使用volatile这个关键字来避免编译时内存乱序访问(且仅能避免编译时的乱序访问,为什么呢,可以参考前面部分的说明,编译器对于volatile声明究竟做了什么 – volatile关键字对于编译器而言,是开发者告诉编译器,这个变量内存的修改,可能不再你可视范围内,不要对这个变量相关的代码进行优化)。volatile关键字能让volatile变量之间的内存访问上有序,这里可以修改x和y的定义来解决问题:
volatile int x, y, r;通过volatile关键字,使得x相对y、y相对x在内存访问上是有序的。实际上,Linux内核中,宏ACCESS_ONCE能避免编译器对于连续的ACCESS_ONCE实例进行指令重排,其就是通过volatile实现的:
#define ACCESS_ONCE(x) (*(volatile typeof(x) *)&(x))此代码只是将变量x转换为volatile的而已。现在我们就有了第三个修改方案:
int x, y, r;
void f()
{
ACCESS_ONCE(x) = r;
ACCESS_ONCE(y) = 1;
}到此,基本上就阐述完成了编译时内存乱序访问的问题。下面看看CPU会有怎样的行为。
运行时,CPU本身是会乱序执行指令的。早期的处理器为有序处理器(in-order processors),总是按开发者编写的顺序执行指令,如果指令的输入操作对象(input operands)不可用(通常由于需要从内存中获取),那么处理器不会转而执行那些输入操作对象可用的指令,而是等待当前输入操作对象可用。
相比之下,
乱序处理器
(out-of-order processors)会先处理那些有
可用输入操作对象
的指令(而
非顺序执行
)从而避免了等待,提高了效率。现代计算机上,处理器运行的速度比内存快很多,有序处理器花在等待可用数据的时间里已可处理大量指令了。
即便现代处理器会
乱序执行
,但在
单个CPU上
,指令能通过
指令队列顺序获取并执行
,结果利用
队列顺序返回寄存器堆
(详情可参考
http://en.wikipedia.org/wiki/Out-of-order_execution
),这使得程序执行时所有的内存访问操作看起来像是按程序
代码编写的顺序执行
的,因此内存屏障是没有必要使用的(前提是
不考虑编译器优化
的情况下)。
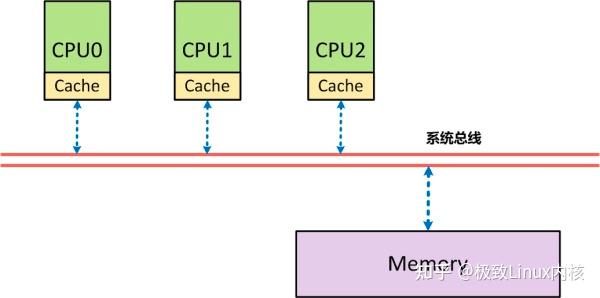
SMP架构需要内存屏障的进一步解释:从体系结构上来看,首先在
SMP架构
下,
每个CPU
与
内存
之间,都配有
自己的高速缓存
(Cache),以减少访问内存时的冲突
采用
高速缓存
的
写操作
有两种模式:
(1).
穿透(Write through)模式
,每次写时,都
直接将数据写回内存
中,效率相对较低;
(2).
回写(Write back)模式
,写的时候先写回告诉缓存,然后由
高速缓存的硬件
再周转
复用缓冲线
(Cache Line)时自动将数据写回内存,或者由软件主动地“冲刷”有关的缓冲线(Cache Line)。
出于性能的考虑,系统往往采用的是
模式2
来完成
数据写入
。正是由于存在
高速缓存
这一层,正是由于采用了Write back模式的数据写入,才导致在
SMP架构
下,对高速缓存的运用可能改变对内存操作的顺序。
以上面的一个简短代码为例:
// thread 0 -- 在CPU0上运行
x = 42;
ok = 1;
// thread 1 – 在CPU1上运行
while(!ok);
print(x);
【文章福利】
小编推荐自己的Linux内核技术交流群:
【977878001】
整理一些个人觉得比较好得学习书籍、视频资料共享在群文件里面,有需要的可以自行添加哦!!!前100进群领取,额外赠送一份
价值699的内核资料包
(含视频教程、电子书、实战项目及代码)
内核资料直通车:
Linux内核源码技术学习路线+视频教程代码资料
学习直通车:
Linux内核源码/内存调优/文件系统/进程管理/设备驱动/网络协议栈
这里CPU1执行时,
x一定是打印出42
吗?让我们来看看以下图为例的说明:
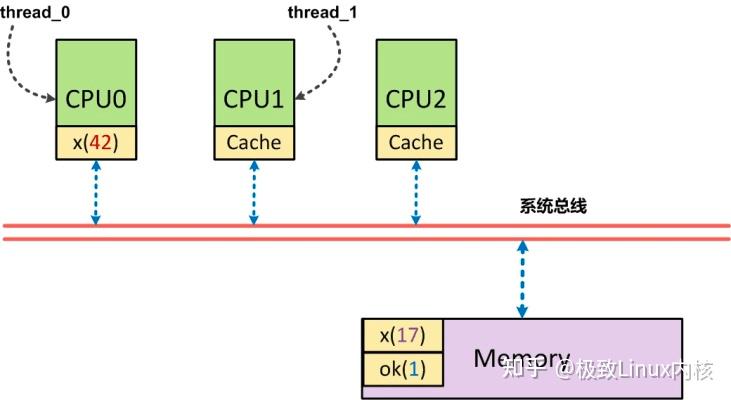
假设, 正好
CPU0的高速缓存
中有
x
, 此时
CPU0
仅仅是将
x=42
写入到了
高速缓存中
,另外一个
ok也在高速缓存
中,但由于
周转复用高速缓冲线
(Cache Line)而导致将
ok=1刷回到了内存
中,此时
CPU1
首先执行
对ok内存的读取操作
,他读到了
ok为1的结果
,进而
跳出循环
,读取
x的内容
,而此时,由于
实际写入的x(42
)还只在
CPU0的高速缓存
中,导致
CPU1读到的数据为x(17
)。
程序
中编排好的
内存访问顺序
(
指令序
: program ordering)是
先写入x
,
再写入y
。而实际上出现在该CPU外部,即
系统总线上的次序
(
处理器序
: processor ordering),却是
先写入y
,
再写入x
(这个例子中x还未写入)。
在SMP架构中,
每个CPU
都只知道
自己何时会改变内存
的内容,但是都
不知道别的CPU
会在
什么时候改变内存
的内容,也不知道
自己本地的高速缓存
中的内容是否与
内存
中的
内容不一致
。反过来,
每个CPU
都可能因为
改变了内存内容
,而使得
其他CPU的高速缓存
变的
不一致
了。
在SMP架构下,由于
高速缓存
的存在而导致的
内存访问次序
(读或写都有可能书序被改变)的改变很有可能影响到
CPU间的同步与互斥
。因此需要有一种手段,使得在
某些操作之前
,把这种“欠下”的内存操作(本例中的
x=42的内存写入
)全都最终地、物理地完成,就好像把欠下的债都结清,然后再开始新的(通常是比较重要的)活动一样。这种手段就是内存屏障,其
本质原理
就是
对系统总线加锁
。
回过头来,我们再来看看为什么
非SMP架构
(UP架构)下,运行时
内存乱序访问不存在
。在单处理器架构下,
各个进程
在
宏观
上是
并行
的,但是在
微观
上却是
串行
的,因为在同一时间点上,只有一个进程真正在运行(系统中只有一个处理器)。在这种情况下,我们再来看看上面提到的例子:

线程0
和
线程1
的指令都将在
CPU0
上按照指令序执行。
thread0
通过
CPU0
完成
x=42
的
高速缓存写入
后,再将
ok=1
写入内存,此后
串行
的将
thread0换出
,
thread1换入
,即使此时
x=42并未写入内存
,但由于
thread1的执行
仍然是在
CPU0
上执行,他仍然访问的是
CPU0的高速缓存
,因此,即使
x=42还未写回到内存
中,
thread1
势必还是
先从高速缓存
中读到
x=42
,再从
内存中读到ok=1
综上所述,在单CPU上,多线程执行不存在运行时内存乱序访问,我们从内核源码也可得到类似结论(代码不完全摘录)
#define barrier() __asm__ __volatile__("": : :"memory")
#define mb() alternative("lock; addl $0,0(%%esp)", "mfence", X86_FEATURE_XMM2)
#define rmb() alternative("lock; addl $0,0(%%esp)", "lfence", X86_FEATURE_XMM2)
#ifdef CONFIG_SMP
#define smp_mb() mb()
#define smp_rmb() rmb()
#define smp_wmb() wmb()
#define smp_read_barrier_depends() read_barrier_depends()
#define set_mb(var, value) do { (void) xchg(&var, value); } while (0)
#else
#define smp_mb() barrier()
#define smp_rmb() barrier()
#define smp_wmb() barrier()
#define smp_read_barrier_depends() do { } while(0)
#define set_mb(var, value) do { var = value; barrier(); } while (0)
#endif
这里可看到对内存屏障的定义,如果是
SMP架构
,smp_mb定义为mb(),mb()为
CPU内存屏障
(接下来要谈的),而
非SMP架构
时(也就是UP架构),直接使用
编译器屏障
,
运行时内存乱序访问并不存在
。
为什么
多CPU
情况下会存在
内存乱序访问
?我们知道
每个CPU都存在Cache
,当一个特定数据
第一次
被
其他CPU获取
时,此数据显然
不在其他CPU的Cache
中(这就是Cache Miss)。这意味着CPU要从
内存中获取数据
(这个过程需要CPU等待数百个周期),此数据将
被加载到CPU的Cache
中,这样后续就能
直接从Cache上快速访问
。当
某个CPU进行写操作
时,他
必须
确保
其他CPU
已将
此数据从他们的Cache中移除
(以便保证一致性),只有在
移除操作完成后
,此CPU才能安全地
修改数据
。显然,存在
多个Cache
时,必须通过一个
Cache一致性协议!!!
来避免数据不一致的问题,而
这个通信的过程!!!
就可能导致
乱序访问的出现
,也就是
运行时内存乱序访问
。受篇幅所限,这里不再深入讨论整个细节,有兴趣的读者可以研究《Memory Barriers: a Hardware View for Software Hackers》这边文章,它详细地分析了整个过程。
现在通过一个例子来直观地说明
多CPU下内存乱序访问
的问题:
volatile int x, y, r1, r2;
//thread 1
void run1()
{
x = 1;
r1 = y;
}
//thread 2
void run2
{
y = 1;
r2 = x;
}
变量x、y、r1、r2均被初始化为0,
run1
和
run2
运行在
不同的线程
中。如果run1和run2在
同一个cpu
下执行完成,那么就如我们所料,
r1和r2
的值
不会同时为0
.
而假如run1和run2在
不同的CPU
下执行完成后,由于存在
内存乱序访问
的可能,这时
r1和r2可能同时为0
。
我们可以使用
CPU内存屏障
来避免
运行时内存乱序访问
(x86_64):
void run1()
{
x = 1;
//CPU内存屏障,保证x=1在r1=y之前执行
__asm__ __volatile__("mfence":::"memory");
r1 = y;
}
//thread 2
void run2
{
y = 1;
//CPU内存屏障,保证y = 1在r2 = x之前执行
__asm__ __volatile__("mfence":::"memory");
r2 = x;
}这里mfence的含义是什么?
x86/64系统架构提供了
三种内存屏障指令
:(1) sfence; (2) lfence; (3) mfence。(参考介绍:
http://peeterjoot.wordpress.com/2009/12/04/intel-memory-ordering-fence-instructions-and-atomic-operations/
以及Intel文档:
http://www.intel.com/content/dam/www/public/us/en/documents/manuals/64-ia-32-architectures-software-developer-vol-3a-part-1-manual.pdf
和
http://www.intel.com/content/www/us/en/processors/architectures-software-developer-manuals.html
)
sfence: 写
Performs a serializing operation on all store-to-memory instructions that were issued prior the SFENCE instruction. This serializing operation guarantees that every store instruction that precedes in program order the SFENCE instruction is globally visible before any store instruction that follows the SFENCE instruction is globally visible. The SFENCE instruction is ordered with respect store instructions, other SFENCE instructions, any MFENCE instructions, and any serializing instructions (such as the CPUID instruction). It is not ordered with respect to load instructions or the LFENCE instruction.
也就是说sfence确保:sfence
指令前后
的
写入
(store/release)指令,按照在
sfence前后的指令序进行执行
。
写内存屏障
提供这样的保证: 所有出现在屏障
之前的STORE操作
都将先于所有出现在屏障
之后的STORE操作
被系统中的
其他组件所感知
.
注意, 写屏障一般需要与读屏障或数据依赖屏障配对使用; 参阅”SMP内存屏障配对”章节. (译注: 因为写屏障只保证自己提交的顺序, 而无法干预其他代码读内存的顺序. 所以配对使用很重要. 其他类型的屏障亦是同理.)
lfence: 读
Performs a serializing operation on all load-from-memory instructions that were issued prior the LFENCE instruction. This serializing operation guarantees that every load instruction that precedes in program order the LFENCE instruction is globally visible before any load instruction that follows the LFENCE instruction is globally visible. The LFENCE instruction is ordered with respect to load instructions, other LFENCE instructions, any MFENCE instructions, and any serializing instructions (such as the CPUID instruction). It is not ordered with respect to store instructions or the SFENCE instruction.
也就是说lfence确保:lfence
指令前后
的
读取
(load/acquire)指令,按照在mfence前后的指令序进行执行。读屏障包含数据依赖屏障的功能, 并且保证所有出现在屏障之前的LOAD操作都将先于所有出现在屏障之后的LOAD操作被系统中的其他组件所感知.
[!] 注意, 读屏障一般要跟写屏障配对使用; 参阅”SMP内存屏障的配对使用”章节.
mfence: 读写
Performs a serializing operation on all load-from-memory and store-to-memory instructions that were issued prior the MFENCE instruction. This serializing operation guarantees that every load and store instruction that precedes in program order the MFENCE instruction is globally visible before any load or store instruction that follows the MFENCE instruction is globally visible. The MFENCE instruction is ordered with respect to all load and store instructions, other MFENCE instructions, any SFENCE and LFENCE instructions, and any serializing instructions (such as the CPUID instruction).
也就是说mfence指令:确保所有mfence指令之前的
写入
(store/release)指令,都在
该mfence指令之后的写入
(store/release)指令
之前
(指令序,Program Order)执行;同时,他还确保所有mfence指令之后的
读取
(load/acquire)指令,都在该mfence指令之前的读取(load/acquire)指令之后执行。即:既确保
写者
能够按照
指令序完成数据写入
,也确保
读者
能够按照
指令序
完成
数据读取
。通用内存屏障保证所有出现在屏障之前的LOAD和STORE操作都将先于所有出现在屏障之后的LOAD和STORE操作被系统中的其他组件所感知.
sfence
我认为其动作,可以看做是
一定将数据写回内存!!!
,
而不是写到高速缓存!!!中
。
lfence
的动作,可以看做是
一定将数据从高速缓存中抹掉!!!
,从
内存中读出来!!!
,而
不是直接从高速缓存
中读出来。
mfence则正好结合了两项操作。
sfence
只确保
写者
在将
数据(A->B)写入内存的顺序
,并
不确保其他人读(A,B)数据
时,一定是按照
先读A
更新后的数据,
再读B
更新后的数据这样的顺序,很有可能读者读到的顺序是
A旧数据
,
B更新后的数据
,
A更新后的数据
(只是这个更新后的数据出现在读者的后面,他并
没有“实际”去读
);同理,
lfence
也就只能确保
读者在读入顺序
时,按照
先读A最新的在内存中的数据
,再读
B最新的在内存中的数据的顺序
,但如果没有写者sfence的配合,显然,即使顺序一致,内容还是有可能乱序。
为什么仅通过保证了
写者的写入顺序
(sfence), 还是有
可能有问题
?还是之前的例子
// CPU 0
void run1()
{
x = 1;
//CPU内存屏障,保证x=1在r1=y之前执行
__asm__ __volatile__("sfence":::"memory");
r1 = y;
}
//CPU 1
void run2
{
y = 1;
//CPU内存屏障,保证y = 1在r2 = x之前执行
__asm__ __volatile__("sfence":::"memory");
r2 = x;
}如果仅仅是对“写入”操作进行顺序化,实际上,还是有可能使的上面的代码出现r1,r2同时为0(初始值)的场景:
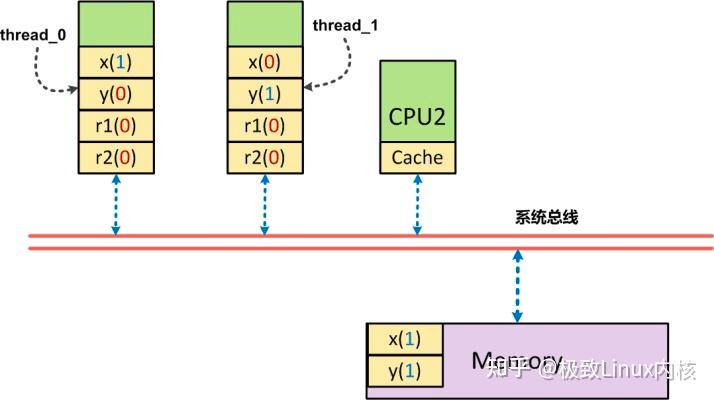
当
CPU0
上的
thread0
执行时,
x被先行写回到内存
中,但如果此时
y在CPU0的高速缓存
中,这时
y从缓存中读出
,并
被赋予r1写回内存!!!
,此时
r1为0
。
同理,
CPU1
上的
thread1
执行时,
y被先行写回到内存
中,如果此时
x在CPU1的高速缓存
中存在,则此时
r2被赋予了x的(过时)值0
,同样存在了r1, r2同时为0。
这个现象实际上就是所谓的
r1=y
的
读顺序!!!与
x=1
的
写顺序!!!存在
逻辑上的乱序所致
(或者是
r2 = x
与
y=1
存在乱序) –
读操作
与
写操作
之间存在
乱序
。而mfence就是将这类乱序也屏蔽掉
如果是通过mfence,是怎样解决该问题的呢?
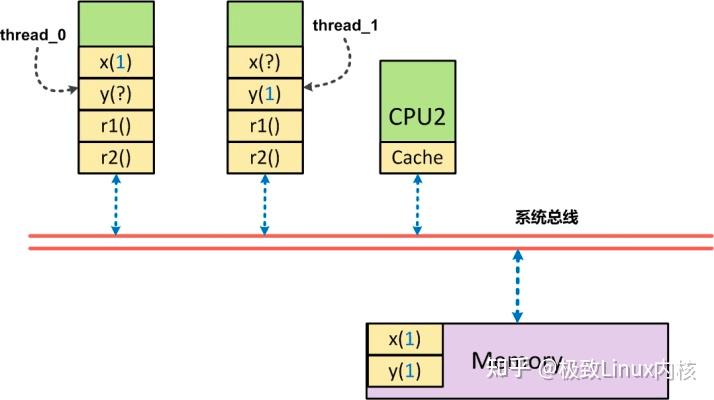
当thread1在CPU0上对x=1进行写入时,**x=1被刷新到内存** 中,由于是**mfence** ,他要求**r1的读取操作** 从**内存读取** 数据,而**不是从缓存中读取** 数据,因此,此时如果**y更新为1** ,则**r1 = 1** ; 如果**y没有更新为1** ,则**r1 = 0** , 同时此时由于x更新为1, r2必须从内存中读取数据,则此时r2 = 1。
总而言之是r1, r2, 一个=0, 一个=1。
在实际的应用程序开发中,开发者可能完全不知道内存屏障就写出了正确的多线程程序,这主要是因为各种同步机制中已隐含了内存屏障(但和实际的内存屏障有细微差别),使得不直接使用内存屏障也不会存在任何问题。但如果你希望编写诸如
无锁数据结构
,那么内存屏障意义重大。
在Linux内核中,除了前面说到的
编译器屏障
—barrier()和ACESS_ONCE(),还有CPU内存屏障:
通用屏障,保证读写操作有序,包括mb()和smp_mb();
写操作屏障,仅保证写操作有序,包括wmb()和smp_wmb();
读操作屏障,仅保证读操作有序,包括rmb()和smp_rmb();
注意,所有的CPU内存屏障(除了数据依赖屏障外)都隐含了编译器屏障(也就是使用CPU内存屏障后就无需再额外添加编译器屏障了)。这里的smp开通的内存屏障会根据配置在
单处理器
上直接使用
编译器屏障
,而在
SMP
上才使用
CPU内存屏障
(即mb()、wmb()、rmb())。
还需要注意一点是,
CPU内存屏障
中某些类型的屏障需要成对使用,否则会出错,详细来说就是:一个写操作屏障需要和读操作(或者数据依赖)屏障一起使用(当然,通用屏障也是可以的),反之亦然。
通常,我们是希望在
写屏障之前出现的STORE操作
总是匹配
读屏障
或者
数据依赖屏障
之后出现的
LOAD操作
。以之前的代码示例为例:
// thread 1
x = 42;
smb_wmb();
ok = 1;
// thread 2
while(!ok);
smb_rmb();
do(x);