数据清洗
是一项复杂且繁琐的工作,同时也是整个数据分析过程中最为重要的环节。数据清洗的目的在于提高数据质量,将脏数据(脏数据在这里指的是对数据分析没有实际意义、格式非法、不在指定范围内的数据)清洗干净,使原数据具有完整性、唯一性、权威性、合法性、一致性等特点。常见的数据清洗操作包括重复值的处理、缺失值的处理、异常值的处理等操作,同时,为了保证数据的有效性,少不了数据校验操作。
这一个介绍中,我们着重介绍数据去重。
数据去重又称重复数据的删除,通常指的是找出数据文件集合中重复的数据并将其删除,只保存唯一的数据单元,从而消除冗余数据。通常情况下,数据去重方法分为两种,分别是完全去重和不完全去重。
完全去重
完全去重指的是消除完全重复的数据,这里提到的完全重复数据指的是数据表记录字段值完全一样的数据。例如,现在有两个表格分别记录的不同年份的用户信息,现要求合并统计所有用户信息,发现合并后的表格存在完全重复的数据,为了便于后期更加方便地使用这些用户数据,通常情况下会对数据进行去重操作。
通过Kettle工具,消除CSV文件merge.csv中完全重复的数据。
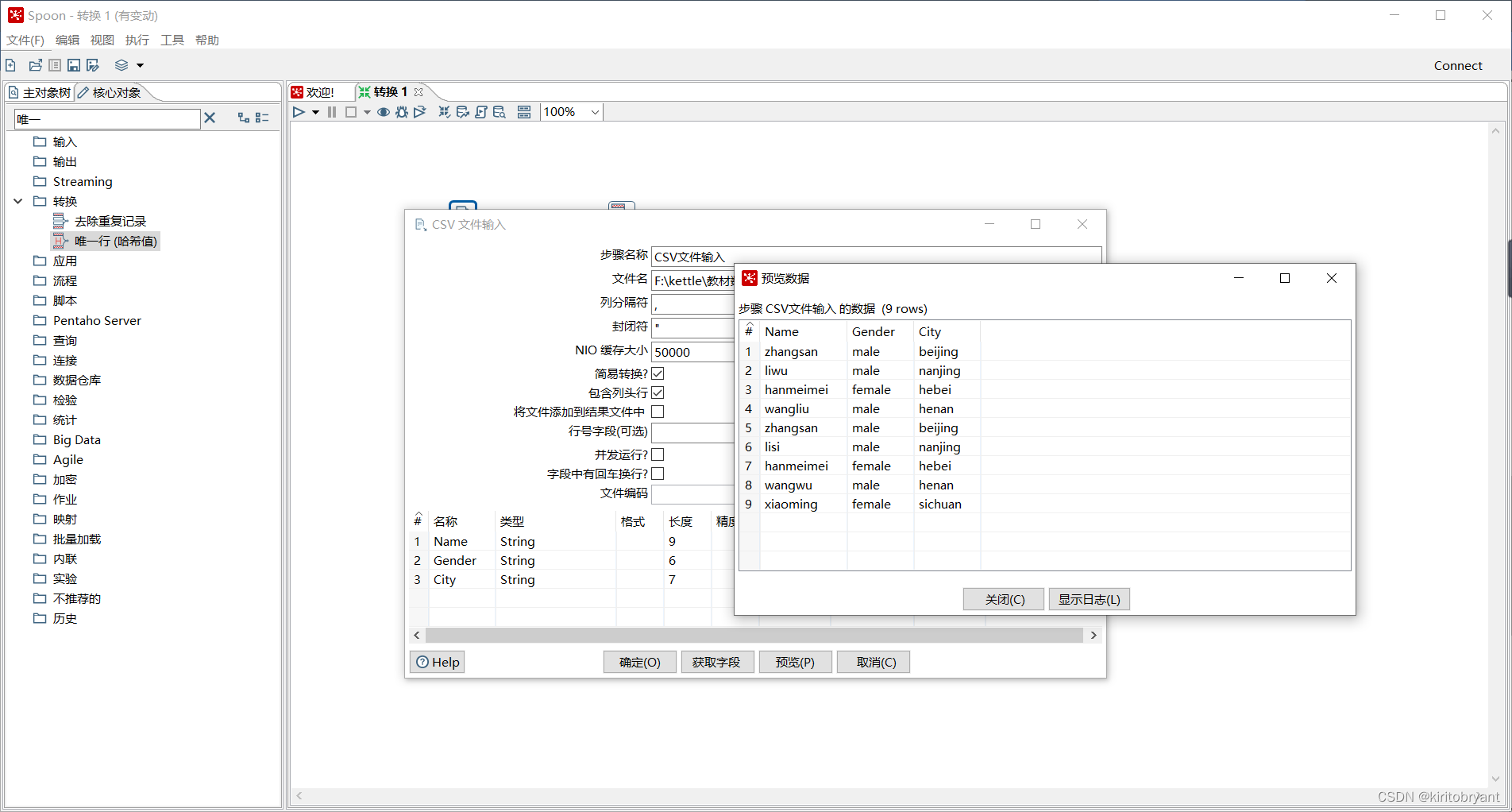
合并后的用户名单存放在CSV文件merge.csv中,内容如图所示。

通过使用Kettle工具,创建一个转换repeat_transform,并添加“CSV文件输入”控件、“唯一行(哈希值)”控件以及Hop跳连接线,具体如图所示。

双击“CSV文件输入”控件,进入“CSV文件输入”配置界面,具体如图所示。

双击“唯一行(哈希值)”控件,进入“唯一行(哈希值)”配置界面。
在“用来比较的字段”处,添加要去重的字段,这里可以单击【获取】按钮,获取要去重的字段。

选中“唯一行(哈希值)”控件,单击执行结果窗口的“Preview data”选项卡,查看是否消除CSV文件merge.csv中完全重复的数据

至此,我们就完成了kettle的完全去重。