1、问题描述
互联网搜素已经成了我们生活和工作的一部分,在输入一些关键词之后,搜索引擎会返回许多结果,每个结果都包含一段概括网页内容的摘要。例如,在百度上搜索框中输入“图的最小生成树 – heart_love”,将会显示如下内容:
在搜索结果中,标题和URL之间的内容就是我们所说的摘要。这些摘要是怎么样生成的呢?我们对问题做如下简化。
给定一段描述w和一组关键字q,我们从这段描述中找出包含所有关键字的最短字符序列。需要注意两点:①最短字符序列必须包含所有的关键字②最短字符序列中关键字的顺序可以是随意的。
2、分析与解法
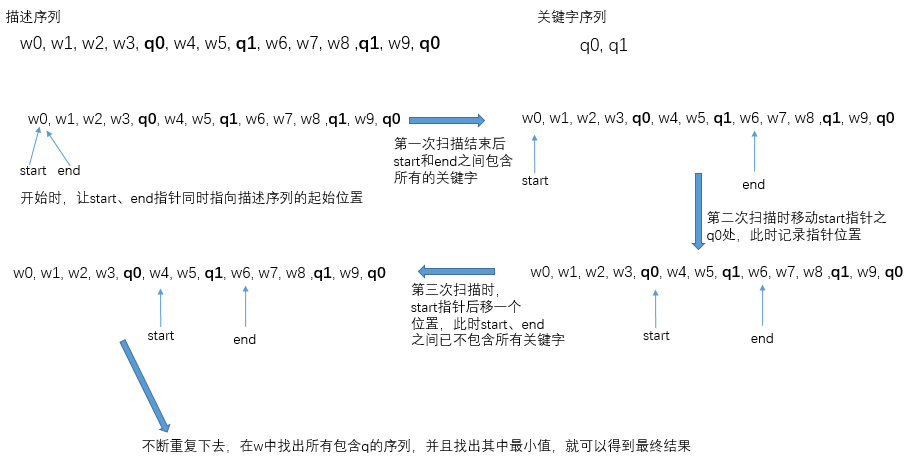
假设给定的描述序列为w0,w1,w2,w3,
q0
,w4,w5,
q1
,w6,w7,w8,
q1
,w9,
q0
,关键字序列为:q0,q1。我们可以观测到包含所有关键字的序列有
q0
,w4,w5,
q1和
q1
,w9,
q0,其中最短的字符序列为
q1
,w9,
q0。我们的解法用图的方式呈现如下:
3、代码
#include <iostream>
#include <string>
#include <hash_map>
using namespace std;
string extract_summary(string description[], int description_len, string key_word[], int key_word_len);
int main()
{
string keyword[] = { "微软", "计算机", "亚洲" ,"交流"};
string description[] = {
"微软", "亚洲", "研究院", "成立", "于", "1998", "年", ",", "我们", "的", "使命",
"是", "使", "未来", "的", "计算机", "能够", "看", "、", "听", "、", "学", ",",
"能", "用", "自然语言", "与", "人类", "进行", "交流", "。", "在", "此", "基础", "上",
",", "微软", "亚洲", "研究院", "还", "将", "促进", "计算机", "在", "亚太", "地区",
"的", "普及", ",", "改善", "亚太", "用户", "的", "计算", "体验", "。", "”"};
int len1 = sizeof(description) / sizeof(string);
int len2 = sizeof(keyword) / sizeof(string);
string ret = extract_summary(description, len1, keyword, len2);
cout << ret << endl;
}
string extract_summary(string description[], int description_len, string key_word[], int key_word_len)
{
int min_index_first = -1;//记录记录最短摘要的起始位置
int min_index_last = -1;//记录记录最短摘要的结束位置
int min_len = description_len;//记录记录最短摘要中包含字符的个数
hash_map<string, int> recorde;//记录关键字在摘要中出现的次数
int count = 0;//记录摘要中出现了几个关键字
//初始化recorde
for (int i = 0; i < key_word_len;i++)
recorde[key_word[i]] = 0;
int start = 0, end = 0;
//进行匹配
while (true)
{
while (count < key_word_len && end < description_len)//摘要中未包含全部的关键字
{
if (recorde.find(description[end]) != recorde.end())
{
if (recorde[description[end]] == 0)
count++;
recorde[description[end]]++;
}
end++;
}
while (count == key_word_len)//摘要中包含全部关键字
{
if ( (end - start) < min_len)
{
min_index_first = start;
min_index_last = end - 1;
min_len = end - start;
}
if (recorde.find(description[start]) != recorde.end())//description[start])是关键字
{
int tmp = --recorde[description[start]];
if (tmp == 0)
count--;
}
start++;
}
if (end >= description_len)
break;
}
string tmp;
for (; min_index_first <= min_index_last; min_index_first++)
tmp+=description[min_index_first];
return tmp;
} 运行结果:
