mycat完成水平拆分
简介
相对于垂直拆分,水平拆分不是将表做分类,而是按照某个字段的某种规则来分散到多个库之中,每个表中包含一部分数据。简单来说,我们可以将数据的水平切分理解为是按照数据行的切分,就是将表中的某些行切分 到一个数据库,而另外的某些行又切分到其他的数据库中,如图:
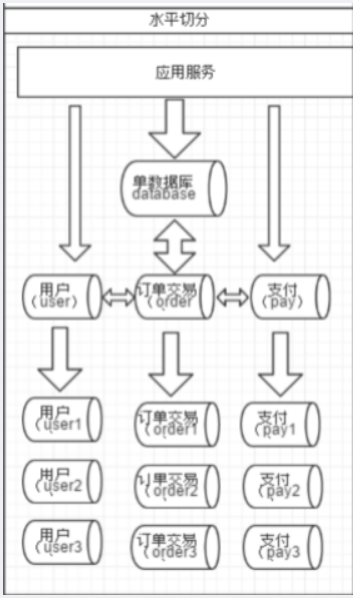
选择要拆分的表
MySQL 单表存储数据条数是有瓶颈的,单表达到 100 万条数据就达到了瓶颈,会影响查询效率,需要进行水平拆分(分表)进行优化。例如:例子中的 orders、orders_detail 都已经达到 600 万行数据,需要进行分表优化。
分表字段,以 orders 表为例,可以根据不同自字段进行分表
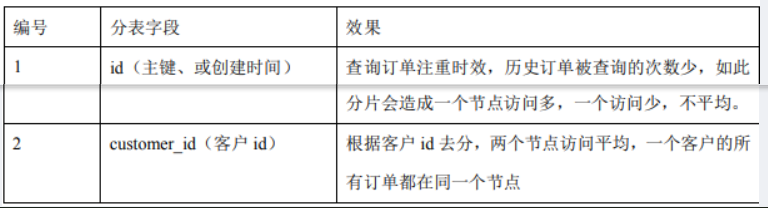
修改
schema.xml
文件,为 orders 表设置数据节点为 dn1、dn2,并指定分片规则为mod_rule(自定义的名字):
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn1">
<table name="tbl_consumer" dataNode="dn2"></table>
<!-- rule:水平分表得规则名称该名称可以随便定义。-->
<table name="tbl_orders" dataNode="dn1,dn2" rule="mod_rule"></table>
</schema>
<dataNode name="dn1" dataHost="host1" database="orders" />
<dataNode name="dn2" dataHost="host2" database="consumer" />
<dataHost name="host1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.179.131:3306" user="root"
password="123456">
</writeHost>
</dataHost>
<dataHost name="host2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM2" url="192.168.179.132:3306" user="root"
password="123456">
</writeHost>
</dataHost>
</mycat:schema>
主要注意的地方:
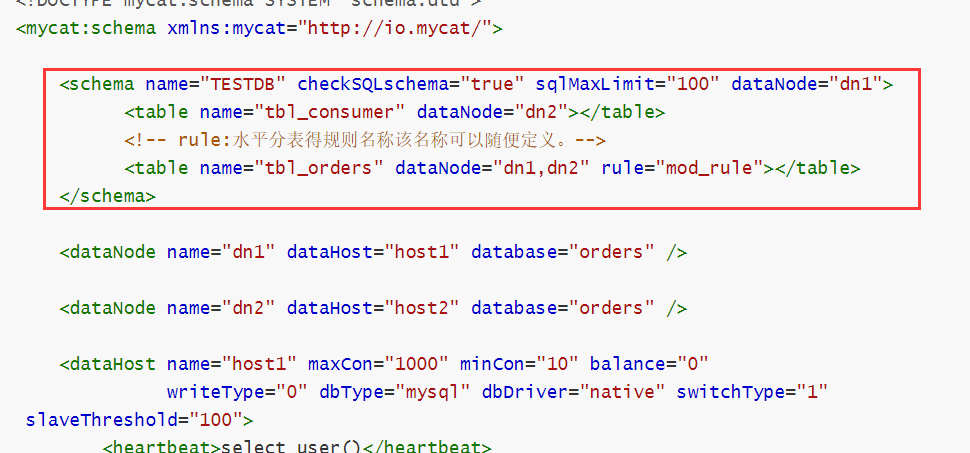
rule.xml中配置我们的规则
<tableRule name="mod_rule">
<rule>
<columns>customer_id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- 数据库的个数 -->
<property name="count">2</property>
</function>

确保两个机器中都有相应的数据库时(本案例为:tbl_orders)

INSERT INTO tbl_orders values(1,101,100,100100);
报错:
partition table, insert must provide ColumnList
分片表添加数据时 需要
提供列的列表
,如果不指定无法确定哪个值为分表的字段
我们可以通过mycat往该表中添加相关数据
INSERT INTO tbl_orders(id,order_type,customer_id,amount) VALUES (1,101,100,100100);
INSERT INTO tbl_orders(id,order_type,customer_id,amount) VALUES(2,101,100,100300);
INSERT INTO tbl_orders(id,order_type,customer_id,amount) VALUES(3,101,101,120000);
INSERT INTO tbl_orders(id,order_type,customer_id,amount) VALUES(4,101,101,103000);
INSERT INTO tbl_orders(id,order_type,customer_id,amount) VALUES(5,102,101,100400);
INSERT INTO tbl_orders(id,order_type,customer_id,amount) VALUES(6,102,100,100020);
发现:

144是192.168.179.131, 145是192.168.179.132 图没改
Mycat 的分片 “join”
join: 联表查询
Orders 订单表已经进行分表操作了,和它关联的 orders_detail 订 单详情表如何进行 join 查询,我们要对 orders_detail 也要进行分片操作。Join 的原理如下图:
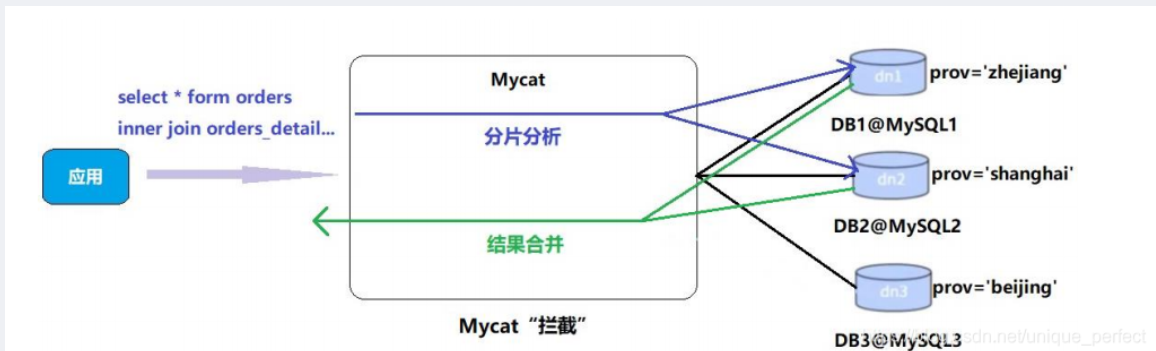
使用ER表解决上面的字表关联查询的问题,其将
子表的存储位置依赖于主表
,并且物理上紧邻存放,因此彻底解决了JION 的效率和性能问 题,根据这一思路,提出了基于E-R 关系的数据分片策略,子表的记录与所关联的父表记录存放在
同一个数据分片
上。
修改schema.xml文件
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn1">
<table name="tbl_consumer" dataNode="dn2"></table>
<!-- rule:水平分表得规则名称该名称可以随便定义。-->
<table name="tbl_orders" dataNode="dn1,dn2" rule="mod_rule">
<!-- childTale:定义子表得标签
name: 关联得子表名称
primaryKey:子表中得主键列名
joinKey: 子表中外键得列名
parentKey: 关联得父表得主键名称
-->
<childTable name="tbl_orders_detail" primaryKey="id" joinKey="order_id" parentKey="id"/>
</table>
</schema>
<dataNode name="dn1" dataHost="host1" database="orders" />
<dataNode name="dn2" dataHost="host2" database="orders" />
<dataHost name="host1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.179.131:3306" user="root"
password="123456">
</writeHost>
</dataHost>
<dataHost name="host2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM2" url="192.168.179.132:3306" user="root"
password="123456">
</writeHost>
</dataHost>
</mycat:schema>
主要注意的地方:
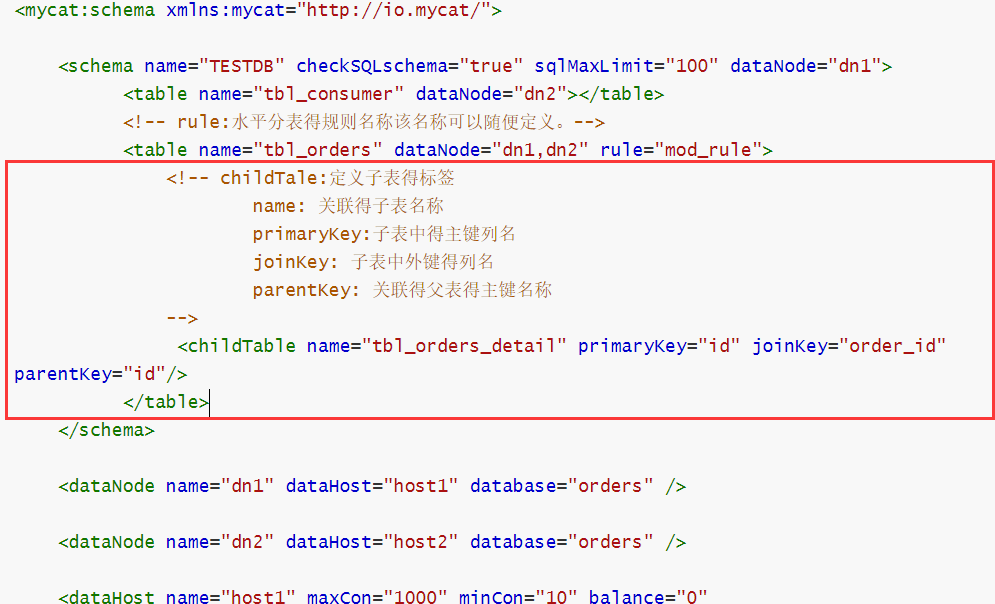
确保两个机器上都有tbl_orders_detail表
CREATE TABLE tbl_orders_detail(
id INT AUTO_INCREMENT,
detail VARCHAR(2000),
order_id INT,
PRIMARY KEY(id)
);
重启mycat
通过mycat往tbl_orders_detail表添加数据
INSERT INTO tbl_orders_detail(id,detail,order_id) values(7,'detail1',1);
INSERT INTO tbl_orders_detail(id,detail,order_id) VALUES(8,'detail1',2);
INSERT INTO tbl_orders_detail(id,detail,order_id) VALUES(9,'detail1',3);
INSERT INTO tbl_orders_detail(id,detail,order_id) VALUES(10,'detail1',4);
INSERT INTO tbl_orders_detail(id,detail,order_id) VALUES(11,'detail1',5);
INSERT INTO tbl_orders_detail(id,detail,order_id) VALUES(12,'detail1',6);
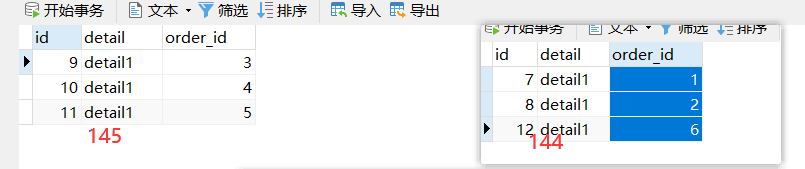
测试

全局表
订单数据字段表.—存放订单得状态—->支付 未支付 取消 待发货 已发货 已确认。。。。
由于订单数据字典表 再每个节点上都需要。所以我们把数据字典表定义为全局表。
什么样得表时候做全局表.
- 变动不频繁
- 数据量总体变化不大
- 数据规模不大,很少有超过数十万条记录
鉴于此,Mycat 定义了一种特殊的表,称之为“全局表”,全局表具有以下特性:
- 全局表的插入、更新操作会实时在所有节点上执行,保持各个分片的数据一致性
- 全局表的查询操作,只从一个节点获取
- 全局表可以跟任何一个表进行 JOIN 操作将字典表或者符合字典表特性的一些表定义为全局表,则从另外一个方面,很好的解决了数据JOIN 的难题。通过全局表+基于 E-R 关系的分片策略,Mycat 可以满足 80%以上的企业应用开发
修改schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn1">
<table name="tbl_consumer" dataNode="dn2"></table>
<!-- rule:水平分表得规则名称该名称可以随便定义。-->
<table name="tbl_orders" dataNode="dn1,dn2" rule="mod_rule">
<!-- childTale:定义子表得标签
name: 关联得子表名称
primaryKey:子表中得主键列名
joinKey: 子表中外键得列名
parentKey: 关联得父表得主键名称
-->
<childTable name="tbl_orders_detail" primaryKey="id" joinKey="order_id" parentKey="id"/>
</table>
<!-- type:global表示全局表得意思-->
<table name="tbl_dict_order_type" dataNode="dn1,dn2" type="global" ></table>
</schema>
<dataNode name="dn1" dataHost="host1" database="orders" />
<dataNode name="dn2" dataHost="host2" database="consumer" />
<dataHost name="host1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.179.131:3306" user="root"
password="123456">
</writeHost>
</dataHost>
<dataHost name="host2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM2" url="192.168.179.132:3306" user="root"
password="123456">
</writeHost>
</dataHost>
</mycat:schema>
主要注意的地方:
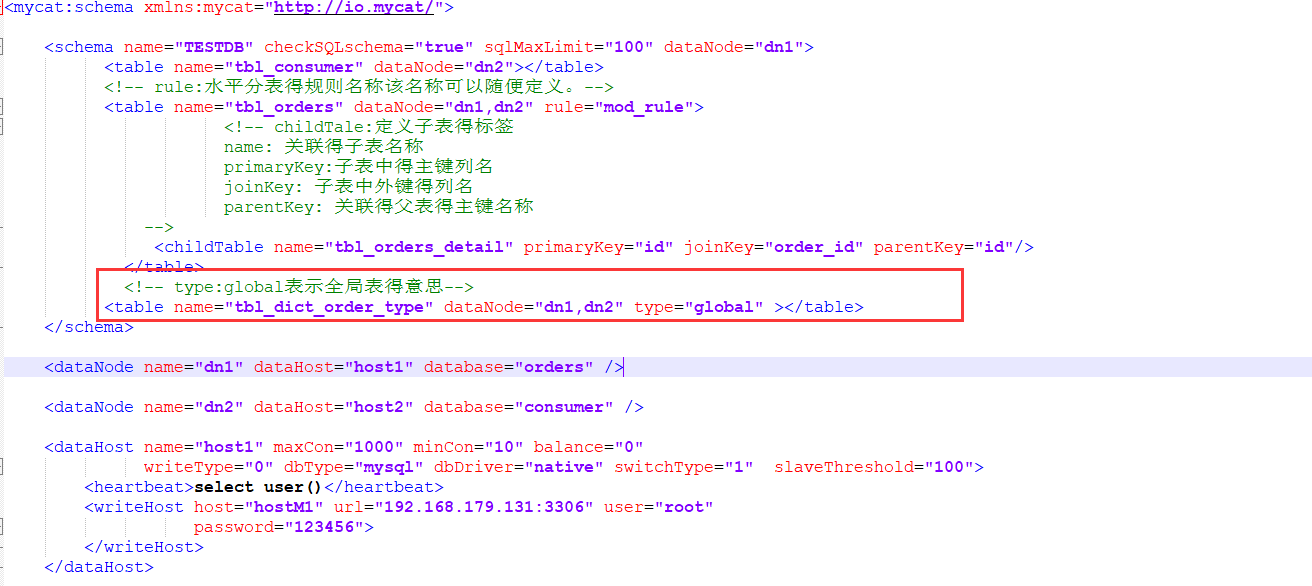
重启mycat
确保两个服务器机器上都有tbl_dict_order_type数据库,注意:需要通过mycat创建表
CREATE TABLE tbl_dict_order_type(
id INT AUTO_INCREMENT,
order_type VARCHAR(200),
PRIMARY KEY(id)
);
通过mycat添加数据
INSERT INTO tbl_dict_order_type(id,order_type) VALUES(101,'type1');
INSERT INTO tbl_dict_order_type(id,order_type) VALUES(102,'type2');
两个数据库中都有数据,全局表