概述
现在许多应用程序编程是不需要用到汇编语言写代码的,但是在需要高度优化的情况下,汇编语言就会凸显它的优势。启动代码、设备驱动程序或开发操作系统时都需要用到汇编。最后,在调试C代码时能够阅读汇编代码,特别是理解汇编指令和C语句之间的映射,这是非常有用的。
1、指令助记符
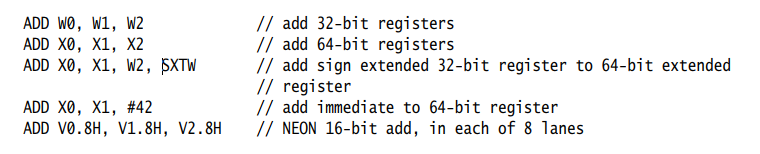
A64汇编语言重载指令助记符,并根据操作数寄存器名称区分不同形式的指令。例如,下面的ADD指令都有不同的编码,但您只需要记住一个助记符,汇编程序会根据操作数自动选择正确的编码。
2、数据处理指令
这些是处理器的基本算术和逻辑运算,对通用寄存器或寄存器和立即数中的值进行运算。第6-4页上的乘法和除法指令可视为这些指令的特殊情况。
数据处理指令主要使用一个目标寄存器和两个操作数。一般格式可以认为是指令,后跟操作数,如下:
Instruction Rd, Rn, Operand2
第二个操作数可以是寄存器、修改后的寄存器或立即数。使用R表示它可以是X或W寄存器。
数据处理操作包括:
- 算术和逻辑运算
- 移位和翻转操作
- 符号和零扩展指令
- 位和位字段操作
- 条件比较和数据处理
2.1 算术和逻辑运算
表6-1显示了一些可用的算术和逻辑运算

有些指令还有一个S后缀,表示指令设置了标志。在上表中还包括ADDS, SUBS, ADCS, SBCS, ANDS, and BICS。还有其他标志设置指令,特别是CMP、CMN和TST,但它们不带S后缀。
ADC和SBC操作执行加法和减法,也使用进位条件标志作为输入。

逻辑运算基本上与在寄存器的各个位上操作的相应布尔运算符相同。
BIC(按位清除)指令对目标寄存器后的第一个寄存器执行AND运算,并将第二个操作数的值反转。
例如,要清除寄存器X0的位[11],可使用:
MOV X1, #0x800
BIC X0, X0, X1
ORN和EON分别使用第二个操作数的按位NOT并执行OR或EOR。
比较指令仅修改标志,没有其他操作。这些指令的立即值范围为12位,并且该值可以选择性地向左移位12位。
2.2 乘法和除法指令
乘法指令与ARMv7中类似,但一条指令能执行64位运算。

有些乘法指令对32位或64位值进行运算,并返回与操作数大小相同的结果。例如,可以将两个64位寄存器相乘,以使用MUL指令生成64位结果。
MUL X0, X1, X2 // X0 = X1 * X2
还可以使用MADD或MSUB指令在将运算结果加上或减去第三个位置的值。
MNEG指令可用于将运算结果取负号,例如:
MNEG X0, X1, X2 // X0 = -(X1 * X2)
此外,还有一系列乘法指令产生长结果,即将两个32位数字相乘并生成64位结果。
这些长乘法有符号和无符号两种变体(UMULL、SMULL)。还有从另一个寄存器累加值(UMADDL,SMADDL)或求反(UMNEGL,SMNEGL)的选项。
下列指令包括32位和64位乘法以及可选累加,结果大小与操作数大小相同:

加宽乘法(即有符号和无符号)和累加得到单个64位结果:
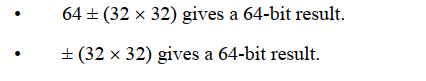
64×64至128位乘法运算需要两条指令序列来生成一对64位结果寄存器:

不能将32位W寄存器与64位X寄存器直接相乘
ARMv8-A体系结构支持32位和64位大小值的有符号和无符号除法。例如:
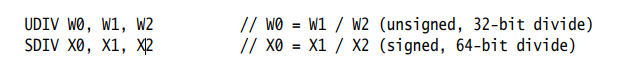
溢出和除0不受限制:
- 任何整数除以零返回零
- 溢出只能在SDIV中发生:INT_MIN/-1返回INT_MIN,其中INT_MIN是可在用于操作的寄存器中编码的最小负数。结果总是向零舍入,就像大多数C/C++一样。
2.3 移位操作
以下是特殊的移位指令:
- 逻辑左移(LSL)。LSL指令执行2次幂的乘法。
- 逻辑右移(LSR)。LSR指令按2的幂进行除法。
- 算术右移(ASR)。ASR指令执行2的幂除法,保留符号位。
-
向右翻转(ROR)。ROR指令执行位旋转,将从LSB旋转的位转换到MSB。


为移位指定的寄存器可以是32位或64位。要移位的数量可以指定为立即数,即寄存器大小减1,或者通过一个寄存器,该寄存器的值仅取自底部的五位(32位模式)或六位(64位模式)。
2.4 位域和字节操作指令
有些指令将字节、半字或字扩展到寄存器大小,寄存器大小可以是X或W。这些指令存在于有符号(SXTB、SXTH、SXTW)和无符号(UXTB、UXTH)变体中,是相应位字段操作指令的别名。
这些指令的有符号和无符号变体都将字节、半字或字(尽管只有SXTW对字进行操作)扩展到寄存器大小。源始终是一个W寄存器。目标寄存器为X或W寄存器,但SXTW必须为X寄存器。

位字段指令与ARMv7中的指令类似,包括位字段插入(BFI)和有符号和无符号位字段提取((S/U)BFX)。还有一些额外的位字段指令,如BFXIL(位字段提取和插入低位)、UBFIZ(无符号位字段零插入)和SBFIZ(有符号位字段零插入)。

还有BFM、UBFM和SBFM指令。这些是位字段移动指令,是ARMv8的新增指令。但是,不需要显式使用说明,因为所有情况下都提供别名。这些别名是已经描述的位字段操作:[SU]XT[BHWX]、ASR/LSL/LSR immediate、BFI、BFXIL、SBFIZ、SBFX、UBFIZ和UBFX。
如果您熟悉ARMv7体系结构,您可能会认识到其他位操作指令:
- CLZ:寄存器中前导零位的计数
- RBIT:反转所有bit
- REV:反转寄存器的字节顺序
-
REV16:反转寄存器的半字顺序

-
REV32:反转寄存器的字顺序

这些操作可以在字(32位)或双字(64位)大小的寄存器上执行,REV32除外,REV32仅适用于64位寄存器。
2.5 条件指令
A64指令集不是每条指令都有都支持条件执行。第4-6页的处理器状态描述了四个状态标志:零(Z)、负(N)、进位(C)和溢出(V)。表6-4显示了用于标志设置操作的这些位的值。


有一小组条件数据处理指令。这些指令无条件执行,但使用条件标志作为指令的额外输入。提供此集合是为了替换ARM代码中条件执行的常见用法,如下指令:
- 带进位的加减法:例如,传统的ARM指令用于多精度算术和校验和。
-
带增加、取反、翻转的条件选择:在一个源寄存器和第二个递增寄存器之间有条件地选择,
求反、求反或未修改的源寄存器。这些是A32和T32中单个条件指令最常见的用法。典型用途包括有条件计数或计算有符号数量的绝对值
条件运算
A64指令集仅允许有条件执行程序流控制分支指令。这与A32和T32不同,在A32和T32中,大多数指令都可以使用条件代码。这些可以总结如下:
条件选择(移位)
- CSEL根据条件在两个寄存器之间进行选择。无条件指令,后跟条件选择,可以替换短条件序列。
- CSINC根据条件在两个寄存器之间进行选择。返回递增1的第一个源寄存器或第二个源寄存器。
- CSINV根据条件在两个寄存器之间进行选择。返回第一个源寄存器或反转的第二个源寄存器。
- CSNEG根据条件在两个寄存器之间进行选择。返回第一个源寄存器或求反的第二个源寄存器。
条件设置
有条件地选择0和1(CSET)或0和-1(CSETM)。例如,用于在通用寄存器中将条件标志设置为布尔值或掩码
条件比较
(CMP和CMN)如果原始条件为真,则将条件标志设置为比较结果。如果不为true,则将条件标志设置为指定的条件标志状态。条件比较指令对于表示嵌套或复合比较非常有用。
使用FCSEL和FCCMP指令的浮点寄存器也可使用条件选择和条件比较。

提供了示例指令的一些别名,其中使用零寄存器,或者使用同一寄存器作为指令的目标寄存器和源寄存器。
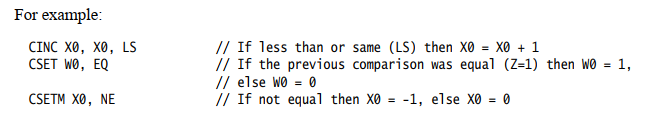
这类指令提供了一种强大的方法来避免使用分支或有条件执行的指令。编译器或汇编程序员可能采用一种技术,对if-then-else语句的两个分支执行操作。然后在最后选择正确的结果。

3、内存访问指令
与所有以前的ARM处理器一样,ARMv8体系结构是一种加载/存储体系结构。这意味着没有数据处理指令直接对内存中的数据进行操作。数据必须首先加载到寄存器、修改,然后存储到内存中。程序必须指定地址、要传输的数据大小以及源寄存器或目标寄存器。还有其他加载和存储指令,它们提供了进一步的选项,例如非临时加载/存储、加载/存储独占和获取/释放。
内存指令可以以未对齐的方式访问普通内存(参见第13章内存顺序)。独占访问、加载或存储的变体不支持这一点。如果不需要未对齐的访问,可以将其配置为故障。
3.1 加载指令格式
加载指令的一般形式:
LDR Rt, < addr >
对于加载到整数寄存器,可以选择要加载的大小。例如,要加载小于指定寄存器值的大小,将以下后缀之一附加到LDR指令:

还有一些未标度的偏移量形式,如LDUR(参见第6-14页指定加载或存储指令的地址)。程序员通常不需要显式地使用LDUR表单,因为大多数汇编器可以根据使用的偏移量选择适当的版本。您不需要为X寄存器指定零扩展负载,因为写入W寄存器实际上是零扩展到整个寄存器宽度。

3.2 存储指令格式
类似地,存储指令的一般形式如下所示:
STR Rn, < addr >
也有未标度的偏移量形式,如STUR(参见第6-14页指定加载或存储指令的地址)。
程序员通常不需要显式地使用STUR表单,因为大多数汇编器可以根据使用的偏移量选择适当的版本。
要存储的大小可能小于寄存器。您可以通过向STR添加B或H后缀来指定这一点。在这种情况下,它始终是寄存器中最不重要的部分。
3.3 浮点和标量加载和存储
加载和存储指令也可以访问浮点/NEON寄存器。这里,大小仅由正在加载或存储的寄存器确定,该寄存器可以是B、H、S、D或Q寄存器中的任何一个。表6-6和表6-7总结了这些信息。


没有符号扩展选项可用于加载到FP/SIMD寄存器。此类加载的地址仍然使用通用寄存器指定。例如:
LDR D0, [X0, X1]
在X0加X1指向的内存地址处加载双字寄存器D0双字。
浮点和标量加载和存储使用与整数加载和存储相同的寻址模式。
3.4 指定加载或存储指令的地址
A64可用的寻址模式与A32和T32中的寻址模式类似。有一些额外的限制以及一些新功能,但A64可用的寻址模式对熟悉A32或T32的人来说并不奇怪。
在A64中,地址操作数的基址寄存器必须始终是X寄存器。然而,有几条指令支持零扩展或符号扩展,因此32位偏移量可以作为W寄存器提供。
偏移模式
偏移寻址模式向64位基址寄存器添加立即值或可选修改的寄存器值以生成地址。

通常,在指定移位或扩展选项时,移位量可以是访问大小的0(默认值)或log2(以字节为单位)(以便Rn << < shift > 将Rn乘以访问大小)。这支持常见的数组索引操作。

索引模式
索引模式与偏移模式类似,但它们也会更新基址寄存器。语法与A32和T32中的相同,但操作集限制更大。通常,索引模式只能提供即时偏移。
有两种变体:在访问内存之前应用偏移量的预索引模式和在访问内存之后应用偏移量的后索引模式。

PC相对模式(load-literal)
A64添加了另一种专门用于访问文本池的寻址模式。文字池是在指令流中编码的数据块。池不会被执行,但是可以使用PC相对内存地址从周围的代码访问它们的数据。
文字池通常用于编码不适合简单移动立即指令的常量值。在A32和T32中,PC可以像通用寄存器一样读取,因此只需将PC指定为基址寄存器即可访问文本池。
在A64中,PC通常不可访问,但有一种特殊的寻址模式(仅适用于加载指令)可访问PC相对地址。这种专用寻址模式的范围也比A32和T32中的PC相对负载大得多,因此文字池的位置可以更稀疏。

3.5 访问多个内存位置
A64不包括A32和T32代码的加载倍数(LDM)或存储倍数(STM)指令。
在A64代码中,有加载对(LDP)和存储对(STP)指令。与A32 LDRD和STRD指令不同,可以读取或写入任意两个整数寄存器。数据被读取或写入相邻的内存位置。为这些指令提供的寻址模式选项比其他内存访问指令更具限制性。LDP和STP指令只能使用具有缩放7位有符号立即数值的基址寄存器,并具有可选的前置或后置增量。与32位LDRD和STRD不同,LDP和STP可以进行未对齐的访问。


3.6 非特权访问
A64 LDTR和STTR指令执行非特权加载或存储(请参阅ARMv8-A架构参考手册中的LDTR和STTR):
- 在EL0、EL2或EL3处,它们表现为正常加载或存储。
- 当在EL1执行时,它们的行为就像是在特权级别EL0执行一样。这些指令相当于A32 LDRT和STRT指令。
3.7 预取存储器
从内存预取(PRFM)使代码能够向内存系统提供提示,提示程序将很快使用来自特定地址的数据。此提示的效果由实现定义,但通常会导致将数据或指令加载到其中一个缓存中。
指令语法为:
PRFM < prfop >, < addr > | label
其中,prfop是以下选项的串联:

这些说明类似于A32 PLD和PLI说明。
3.8 非临时加载和存储对
RMv8中的一个新概念是非时态加载和存储。这些是LDNP和STNP指令,用于读取或写入一对寄存器值。此提供给memory system一个暗示(hint):这个访问是non-temporal或者流式(streaming)的,在短时间内很可能不会再次访问,要访问的数据
不需要缓存到cache中
。该提示不禁止内存系统活动,例如缓存地址、预加载或收集。但是,这表明缓存不太可能提高性能。
典型的用例可能是流数据,但请注意,有效使用这些指令需要一种特定于微体系结构的方法。
非时态加载和存储放宽了内存排序要求。在上述情况下,可能在前面的LDR指令之前观察到LDNP指令,这可能导致读取X0中的不确定地址。

注意第二条指令可能在X0没有从X3指向的memory中读出前,就已经执行了,也就是虽然有地址依赖,但是指令1和2的顺序是没有办法保证的,是乱序的。因此需要加内存栅栏才可以达到预期目的。
这两条指令典型的应用场景是需要读写大片的数据,但是并不希望这些数据污染cache中的数据的的情况。
3.9 内存访问原子性
使用单个通用寄存器的对齐内存访问保证是原子的。
使用对齐的内存地址,将对指令加载和存储到一对通用寄存器中,保证显示为两个单独的原子访问。
未对齐的访问不是原子的,因为它们通常需要两个单独的访问。
此外,浮点和SIMD内存访问不保证是原子性的。
3.10 内存屏障和栅栏指令
ARMv7和ARMv8都支持不同的屏障操作。
程序在运行时内存实际的访问顺序和程序代码编写的访问顺序不一定一致,这就是内存乱序访问。内存乱序访问行为出现的理由是为了提升程序运行时的性能。内存乱序访问主要发生在两个阶段:
- 编译时,编译器优化导致内存乱序访问(指令重排)
-
运行时,多 CPU 间交互引起内存乱序访问
Memory Barrier 能够让 CPU 或编译器在内存访问上有序。
第13章内存排序中对这些进行了更详细的描述:
- 数据存储屏障(DMB)。DMB指令保证:仅当所有在它前面的存储器访问操作都执行完毕后,才提交在它后面的存取访问操作指令。当位于此指令前的所有内存访问均完成时,DMB指令才会完成
- 数据同步屏障( Data synchronization Barrier,DSB)。。比DMB要严格一些,仅当所有在它前面的存储访问操作指令都执行完毕后,才会执行在它后面的指令,即任何指令都要等待DSB前面的存储访问完成。位于此指令前的所有缓存,如分支预测和TLB( Translation Look- aside Buffer)维护操作全部完成
- 指令同步屏障( Instruction synchronization Barrier,ISB)。它最严格,冲洗流水线( Flush Pipeline)和预取buer( pretcLbuffers后,才会从 cache或者内存中预取ISB指令之后的指令。ISB通常用来保证上下文切换的效果,例如更改ASID( Address Space Identifier)、TLB维护操作和C15寄存器的修改等。
ARMv8引入了单边围栏,它与发布一致性模型相关联。
这些被称为加载获取(LDAR)和存储释放(STLR),是基于地址的同步原语。(参见第13-8页的单向屏障。)
这两个操作可以配对,形成一个完整的围栏。这些指令只支持基址寄存器寻址,不提供偏移量或其他类型的索引寻址。
3.11 同步原语
ARMv7-A和ARMv8-A体系结构都支持独占内存访问。在A64中,这是加载/存储专用(LDXR/STXR)对。
LDXR指令从内存地址加载一个值,并尝试以静默方式声明对该地址的独占锁定。然后,只有在成功获取并保持锁的情况下,Store EXCLUSIC指令才会将新值写入该位置。LDXR/STXR配对用于构造标准同步原语,如自旋锁。提供了一组成对的LDXRP和STXRP指令,以允许代码自动更新跨越两个寄存器的位置。字节、半字、字和双字选项可用。与Load Acquire/Store Release配对一样,只支持基址寄存器寻址,不支持任何偏移。
CLREX指令清除监视器,但与ARMv7不同,异常条目或返回也会清除监视器。监视器也可能被错误地清除,例如,由于缓存逐出或其他与应用程序不直接相关的原因。软件必须避免在成对的LDXR和STXR指令之间有任何显式内存访问、系统控制寄存器更新或缓存维护指令。
还有一对名为LDAXR和STLXR的专用装载获取/存储释放指令。参见第14-6页的同步。
4、流控制
A64指令集提供多种不同类型的分支指令(见表6-12)。对于简单的相对分支,即从当前地址偏移的分支,使用B指令。无条件简单相对分支可以从当前程序计数器位置向后或向前偏移到128MB。
条件简单相对分支,其中条件代码附加到B,跳转范围较小,为±1MB范围。
如果需要将返回地址存储在链接寄存器(X30)中,则对子例程的调用使用BL指令。此指令不支持条件。BL的行为类似于B指令,其附加作用是将返回地址(BL之后的指令地址)存储在寄存器X30中。

除了这些相对于PC地址的跳转以外,A64指令集还包括两个绝对分支跳转。BR Xn指令执行将跳转到Xn中的地址,而BLR Xn具有相同的效果,但也将返回地址存储在X30(链接寄存器)中。
RET指令的行为类似于BR Xn,但它向分支预测逻辑提示它是一个函数返回。默认情况下,RET分支到X30中的地址,但可以指定其他寄存器。
A64指令集包括一些特殊的条件分支。在某些情况下,这可以提高代码密度,因为不需要显式比较。
- CBZ Rt, label // Compare and branch if zero
- CBNZ Rt, label // Compare and branch if not zero
这些指令将源寄存器(32位或64位)与零进行比较,然后有条件地执行分支。分支偏移的范围为±1MB。这些说明不读取或写入条件代码标志(NZCV)。
有两种类似的测试和分支指令:
- TBZ Rt, bit, label // Test and branch if Rt< bit > zero
- TBNZ Rt, bit, label // Test and branch if Rt< bit > is not zero
这些指令根据位是否设置或清除,在立即分支和有条件分支指定的位位置测试源寄存器中的位。分支偏移的范围为±32kB。与CBZ/CBNZ一样,这些指令不读取或写入条件代码标志(NZCV)。
5、系统控制和其他指令
A64指令集包含与以下内容相关的指令:
- 异常处理
- 系统寄存器访问
- debug
- 提示指令,在许多系统中都有电源管理应用程序
5.1 异常处理说明
有三条异常处理指令,其目的是引起异常的发生。
这些用于调用在操作系统(EL1)、虚拟机监控程序(EL2)或安全监视器(EL3)中运行的更高异常级别的代码:

立即数值可用于异常寄存器中的处理程序。
这是从ARMv7的演变而来,其中必须通过读取调用指令的操作码来确定立即数。
有关更多信息,请参阅第10章AArch64异常处理。
要从异常返回,请使用ERET指令。此指令通过将SPSR_ELn复制到PSTATE并分支到ELR_ELn中保存的返回地址来恢复处理器状态。
5.2 系统寄存器访问
提供两个指令用于访问系统寄存器:

PSTATE的各个字段也可以通过MSR或MRS访问。例如,要选择与EL0或当前异常级别关联的堆栈指针:

这些指令有一些特殊形式,可用于清除或设置个别异常掩码位(见第4-5页保存的过程状态寄存器):
• MSR DAIFClr, #imm4
• MSR DAIFSet, #imm4
See System registers on page 4-7.
5.3 调试指令

5.4 提示指令

5.5 NEON instructions
NEON指令集也有一些增强功能,其中一些功能非常重要。第7章AArch64浮点和NEON更详细地描述了这些。
A64中NEON的改变包括:
- 支持双精度浮点,使使用双精度浮点的C代码能够矢量化
- 对存储在NEON寄存器中的标量数据进行操作的新指令
- 插入和提取矢量元素的新指令
- 型转换和饱和整数算法的新指令
- 浮点值标准化的新指令
- 用于矢量减少、求和以及取最小值或最大值的交叉运算新指令
- 用于执行比较、添加、查找绝对值和求反等操作的指令已扩展为能够对64位整数元素进行操作
5.6 浮点指令
A64提供了一组与ARMv7-a VFPv4扩展类似的浮点指令,该扩展提供了对标量浮点值的单精度和双精度数学运算。有许多更改和新功能:
- 浮点比较直接设置条件标志(NZCV)。A64中不需要显式地将比较结果从浮点标志传输到整数标志
- 添加了与IEEE754-2008标准相关的说明,例如,用于计算一对数字的最小值和最大
- 从整数格式转换为浮点格式时,现在可以显式指定舍入模式。在特定舍入模式下需要简单转换时,不再需要设置全局FPCR标志。其中一些选项也可用于ARMv8 A32和T32
- 已添加指令以支持64位整数和浮点格式之间的转换
- 在A64中,涉及整数类型的浮点操作直接作用于整数寄存器。转换操作不需要在浮点寄存器和整数寄存器之间手动传输整数值
5.7 密码指令
ARMv8的可选扩展添加了加密指令,可显著提高AES加密、SHA1和SHA256哈希等任务的性能。