一、GAN对抗生成神经网络简介
GAN全名是Generative Adversarial Nets,中文名叫对抗生成神经网络,论文地址:
https://arxiv.org/pdf/1406.2661v1.pdf
。
于2014年提出,其模型思想简单,一个生成器Generator生成虚假的数据,另外一个判别器Discriminator负责判断哪些是虚假的数据,哪些是真实的数据。
GAN的用处很广,可以生成虚假图像、文本等数据,当模型训练的数据量很少的时候,也同样可以利用GAN生成数据进行训练,所以GAN也是一种数据增强的方式,可以提高模型的鲁棒性。
训练过程中,判别器不断判别哪些是真实的数据,输出标签为1,表示真,哪些数据为假,输出标签为0,表示假。然后降低这个判断误差,而生成器则是生成虚假数据,不断提高判别器的判别误差,生成器和判别器不断相互对抗,最终达到一个纳什均衡点。
先贴出公式如下:
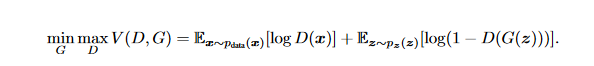
这是论文里面的原始概念公式,可以理解为D和G 互相针对对方的模型判别不断干扰。
下面贴出具体的算法流程,来源于原始论文。

1.1 判别器discriminator
上面的x表示真实数据,z表示虚假数据,模型一开始是先训练判别器discriminator,简称D,更新过程为
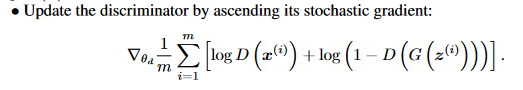
请注意这里是梯度提升:ascending its stochastic gradient。不是我们常见的梯度下降,所以在用代码实现时,记得损失函数前面加个负号,转换成梯度下降,因为深度模型框架基本都是利用梯度下降。
这里有两个部分,一个是针对真实的数据的判别,我们希望生成器尽可能把真实数据输出为1,把虚假数据输出为0,那么也就是希望该部分
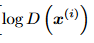
不断增大,表示对真实数据的判断能力提高了。
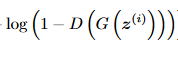
同时希望对虚假数据输出为0,也就是D(G(z))输出尽可能接近0,那么前面1-D(G(z))也是在尽可能增大,表示对虚假数据判断能力的提高。
1.2 生成器 generator
生成器部分的更新公式为
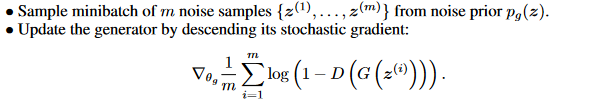
这里又需要注意论文里描述的生成器的优化是梯度下降更新法:descending its stochastic gradient,和判别器的梯度上升更新不同。
生成器部分就比较简单了,只有一个任务,就是混淆判别器的判断能力,也就是让D(G(z))输出尽可能接近1,让生成器误以为是真实数据,然后结合梯度下降法,目标就是让1-D(G(z))尽可能小。
二、数据集
这里直接采用台湾大学李宏毅老师针对GAN讲解用的示例,也就是二次元妹子的数据集。
数据集有33430张图像,每张图像都为3通道的96×96大小的图像数据。
内容如下

三、判别器D和生成器G的代码实现
请注意把下面两个模型的代码单独保存为一个文件:Model.py。
3.1 判别器D
判别器的实现非常简单,就是一个简单的CNN模型,然后输出节点利用sigmoid函数进行映射到0-1之间即可,注意输入的图像尺寸,计算每一层的卷积层大小关系。
#判别器
class CNN_Discriminator(nn.Module):
def __init__(self):
super(CNN_Discriminator, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2), # batch, 32, 96,96,
nn.LeakyReLU(0.2, True),
nn.AvgPool2d(2, stride=2), # batch, 32, 48, 48
)
self.conv2 = nn.Sequential(
nn.Conv2d(32, 64, 5, padding=2), # batch, 64, 48, 48
nn.LeakyReLU(0.2, True),
nn.AvgPool2d(2, stride=3) # batch, 64, 16, 16
)
self.fc = nn.Sequential(
nn.Linear(64 * 16 * 16, 1024),
nn.LeakyReLU(0.2, True),
nn.Linear(1024, 1),
nn.Sigmoid()
)
def forward(self, x):#输入为3通道的96x96大小的图像数据矩阵
'''
x: batch, width, height, channel=3
'''
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
3.2 生成器G
生成器相对复杂一些,生成器考虑的是怎么把输入转换为一个和判别器对应输入尺寸的图像数据,一般常见的是两种方法:逆卷积和维度转换。
逆卷积是通过卷积层添加大的卷积操作,把小的卷积结果向大的卷积维度映射。
维度转换比较简单,直接输入一个很大的一维的数据,把这个数据转换为一个比较大的二维图像,这个图像经过我们的生成器模型卷积操作后恰好等于判别器D的输入数据大小。
维度转换实现也比较简单,这里展示维度转换的生成器G的模型构成。
#生成器
class CNN_Generator(nn.Module):
def __init__(self):
super(CNN_Generator, self).__init__()
self.br = nn.Sequential(
nn.BatchNorm2d(15),
nn.ReLU(True)
)
self.downsample1 = nn.Sequential(
nn.Conv2d(15, 50, 3, stride=1, padding=1), # batch, 50, 192, 192
nn.BatchNorm2d(50),
nn.ReLU(True)
)
self.downsample2 = nn.Sequential(
nn.Conv2d(50, 25, 3, stride=1, padding=1), # batch, 25, 192, 192
nn.BatchNorm2d(25),
nn.ReLU(True)
)
self.downsample3 = nn.Sequential(
nn.Conv2d(25, 3, 2, stride=2), # batch, 3, 96, 96
nn.Tanh()
)
def forward(self, x):
x = self.fc(x)#经过线性映射,得到一个很大的一维输出数据
x = x.view(x.size(0), 15, 192, 192)#把一维数据转换成15个通道的192x192大小的矩阵数据
x = self.br(x)
x = self.downsample1(x)
x = self.downsample2(x)
x = self.downsample3(x)#卷积操作最后输出一个3通道的96x96大小的数据矩阵
return x
四、原始模型的模型与优化
4.1 导入判别器和生成器
D = Model.CNN_Discriminator() #加载判别器
D.to(args.device)
G = Model.CNN_Generator(args.z_dimension,15*192*192)#加载生成器
G.to(args.device)#把模型放到对应的显卡设备上
d_optimizer = torch.optim.Adam(D.parameters(), lr=0.0002)#定义Adam优化器
g_optimizer = torch.optim.Adam(G.parameters(), lr=0.0002)
4.2 开始按原始论文方式训练
for epoch in range(args.num_epoch):
for i, (img,_) in enumerate(dataloader):
if torch.cuda.is_available(): #清空显卡缓存
torch.cuda.empty_cache()
num_img = img.size(0)
#train discriminator
# compute loss of real_matched_img
img = img.view(num_img,3,96,96)
real_img = Variable(img).to(args.device)
#----------------------------训练判定器--------------------------------
matched_real_out = -1.0 * torch.log(D(real_img).squeeze(-1).sum())
# compute loss of fake_matched_img
z = Variable(torch.randn(num_img, args.z_dimension)).to(args.device)
fake_img = G(z)
matched_fake_out = -1.0 * torch.log((1.0 - D(fake_img).squeeze(-1)).sum())
# bp and optimize
d_loss = matched_real_out + matched_fake_out
d_optimizer.zero_grad()
d_loss.backward()
d_optimizer.step()
# ============================train generator================================
# compute loss of fake_img
# compute loss of fake_matched_img
z = Variable(torch.randn(num_img, args.z_dimension)).to(args.device)
fake_img = G(z)
matched_fake_out = torch.log((1.0 - D(fake_img).squeeze(-1)).sum())
g_loss = matched_fake_out
# bp and optimize
g_optimizer.zero_grad()
g_loss.backward()
g_optimizer.step()
print('Epoch [{}/{}], Batch {},d_loss: {:.6f}, g_loss: {:.6f} '
.format(
epoch, args.num_epoch,i,d_loss.data, g_loss.data,
))
4.3 训练结果
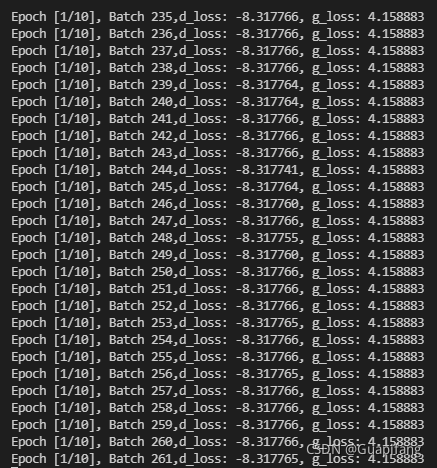
可以看到G和D的损失一直没有变化,越到后面越容易陷入一种局部最优的情况,然后没有很大波动,所以我中止了训练。
可以查看图像生成效果如下;
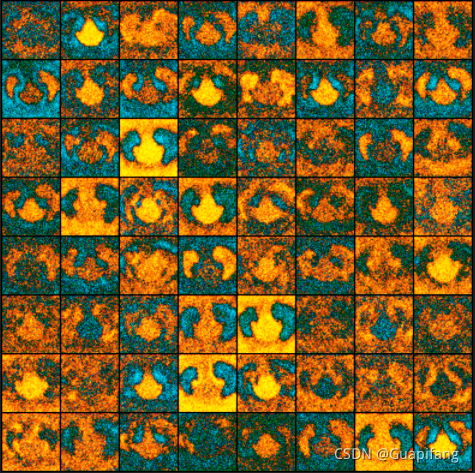
好吧,陷入不波动之后,效果一直没变化了。
猜想一种原因是模型不够强大,没法继续更好的判别哪些图像是真图像,哪些是假图像。
也可能是损失函数的原因,我们现在常用的损失函数为交叉熵损失函数,交叉熵损失函数具有更大的惩罚效果,原始论文的函数虽然也用到了log来代表损失惩罚,但整体而言可能表达没这么好。
4.4 利用交叉熵损失函数代替原论文损失函数
导入交叉熵损失函数
D = Model.CNN_Discriminator()
D.to(args.device)
G = Model.CNN_Generator(args.z_dimension,15*192*192)#加载生成器
G.to(args.device)#把模型放到对应的设备上
criterion = nn.BCELoss()#定义二分类交叉熵损失函数
d_optimizer = torch.optim.Adam(D.parameters(), lr=0.0002)#定义Adam优化器
g_optimizer = torch.optim.Adam(G.parameters(), lr=0.0002)
训练代码如下
for epoch in range(args.num_epoch):
for i, (img,_) in enumerate(dataloader):
if torch.cuda.is_available(): #清空显卡缓存
torch.cuda.empty_cache()
num_img = img.size(0)
#train discriminator
# compute loss of real_matched_img
img = img.view(num_img,3,96,96)
real_img = Variable(img).to(args.device)
real_label = Variable(torch.ones(num_img)).to(args.device)
fake_label = Variable(torch.zeros(num_img)).to(args.device)
#----------------------------训练判定器--------------------------------
matched_real_out = D(real_img)
#matched_real_out = -1.0 * torch.log(D(real_img).squeeze(-1).sum())
d_loss_matched_real = criterion(matched_real_out.squeeze(-1), real_label)
# compute loss of fake_matched_img
z = Variable(torch.randn(num_img, args.z_dimension)).to(args.device)
fake_img = G(z)
matched_fake_out = D(fake_img)
#matched_fake_out = -1.0 * torch.log((1.0 - D(fake_img).squeeze(-1)).sum())
d_loss_matched_fake = criterion(matched_fake_out.squeeze(-1), fake_label)
# bp and optimize
#d_loss = matched_real_out + matched_fake_out
d_loss = d_loss_matched_real + d_loss_matched_fake
d_optimizer.zero_grad()
d_loss.backward()
d_optimizer.step()
# ============================train generator================================
# compute loss of fake_img
# compute loss of fake_matched_img
z = Variable(torch.randn(num_img, args.z_dimension)).to(args.device)
fake_img = G(z)
matched_fake_out = D(fake_img)
#matched_fake_out = torch.log((1.0 - D(fake_img).squeeze(-1)).sum())
#matched_fake_out_scores = matched_fake_out
#g_loss = matched_fake_out
g_loss = criterion(matched_fake_out.squeeze(-1),real_label)
# bp and optimize
g_optimizer.zero_grad()
g_loss.backward()
g_optimizer.step()
训练过程


改用交叉熵损失函数后,效果明显好的太多。
再查看生成器生成的图像数据

效果比较明显,因为只训练了10个epoch,所以生成的图像没有这么完美。
五、总结
1、尽量采用交叉熵损失函数,训练效果较好。
2、尽量保证生成模型G和判别模型D的复杂度一致,避免导致某个模型被另外一个模型单方面碾压的情况,这样无法有效形成对抗训练的过程。
希望我的分享对你的学习有所帮助,如果有问题请及时指出,谢谢~