redis做缓存是用来解决读取数据的问题,即读取指令不先去数据库,而先查询。
如果数据查询不到再去数据库进行查询
。
Redis的击穿
可以理解成一个狙击枪子弹打向了数据库,redis没有挡住,一击打瘫痪了数据库。
穿透就是一个点的热点数据突然查询不到,导致所有的请求直接访问数据库。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gPdNdJAZ-1590141132100)(images\image-20200522115216932.png)]](https://img-blog.csdnimg.cn/20200522175547681.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80NTU2ODY0OA==,size_16,color_FFFFFF,t_70#pic_center)
核心:热点数据的过期。
思路,要么缓存不要出现过期,要么再加一层。
方案
1、设置热点数据永不过期
从缓存层面来说,没有设置过期时间,就不会产生穿透问题。
2、加互斥锁
(加入程序层)
分布式锁:只要加了锁,可以保证每个key,只有一个线程去查询后端的服务。只能够等待。
核心:转移压力,尽量服务不崩。 将数据库承受的压力转义到了分布式锁上面。
Redis穿透
可以理解成一个冲锋枪,redis没有起到掩体作用,导致数据库身中数枪。
步骤:查询语句先查询redis,没有发现想要的数据;进入数据库(不管有没有程序层),在数据库中依然没有查到,(没有查到所以没法在redis中写入数据),这样会导致所有查询这个数据的指令都要进入数据库。即即便是有redis和程序作为格挡,数据依然可以进入数据库。

核心:redis和程序没有拦截到请求。
方案:
1.布隆过滤器
可以做到检测数据存在不存在,如果数据不存在就挡回去,不进入redis。

2.存一个空对象。
缺点,对象更新不及时。比如先取后存。
Redis雪崩
其那面相当于是子弹打redis,结果没有挡住直接打到数据库了。这个相当于是“炸开了redis”,造成大规模数据集体失效,或者redis崩了。所有的请求打到了redis上。

核心:数据失效。
方案
1、
Redis的高可用。
redis可能挂掉,这个时候第一保证高可用。
2、
限流降级
,缓存失效后的处理,(加锁,返回预定的对象)
3、
数据预热
, 在正式的部署之前,我们先将这批数据放入到redis缓存中,假设即将发生高并发的情况,这个时候设置不同的过期时间。让缓存失效时间比较均匀。
其实缓存雪崩最怕的还是Redis断网宕机。(自然雪崩)
布隆过滤器
场景:手机推送时候,需要区分这个消息有没有给这个用户推送过。但具体这个消息是什么并不关心;或者在redis前,防止redis的穿透。
特点:
- 对数据进行判断是否存在,但并不关心数据是什么。
- 空间量尽可能的少。
- 可以存在误差。
数据原理
:
每一个数据的唯一标识,通过一定的算法记性散列成一些位。对位数进行统计。
以推送为场景介绍一下

假设我们有data1-4,经过hash散列之后占个数如下
data1: 1 5 8 10
data2:2 6 8
data3:5 6 8 10
data4:5 6 8 10 12
data1存储的时候,都为零所以data1之前没有,所以data1,推送;和他有关的所有格子变成了1。
data2判断的的时候,第6个格子的之前是0,所以可以判断data2没有推送过;将6变成1.
data3判断的时候,12号格子之前是0,所以可以判断data3没有推送过;将12变成1
data4推送的时候,发现所所有的都是1,所以即便是data4没有推送,也不会去推送。
而这个data4就是误差的来源。这时候我们的精度是最高的。
代码实现
:
导入依赖:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>28.0-jre</version>
</dependency>
java代码实现:
public static void main(String[] args) {
// 得到布隆过滤器
BloomFilter<String> integerBloomFilter =
BloomFilter.create(Funnels.stringFunnel(Charset.forName("utf-8")), 1000000, 0.01);
// 这里的1000000,是空间大小,如果空间太小会造成hash碰撞,即不同的值有着相同的hash值。100万时候 没有错误,而1万时候有近5万的错误。
// 后面的0.01是精度,精度越高,出现错误的几率越小。不过花费的时间就会增多。
int errorNum = 0;
// 先存数据
for (int i = 0; i < 100000; i++) {
integerBloomFilter.put(String.valueOf(i));
}
// 过滤器中一定没有的数据
for (int i = 100000; i < 150000; i++) {
if (integerBloomFilter.mightContain(String.valueOf(i))) {
errorNum++;
}
}
System.out.println("错误了: " + errorNum);
}
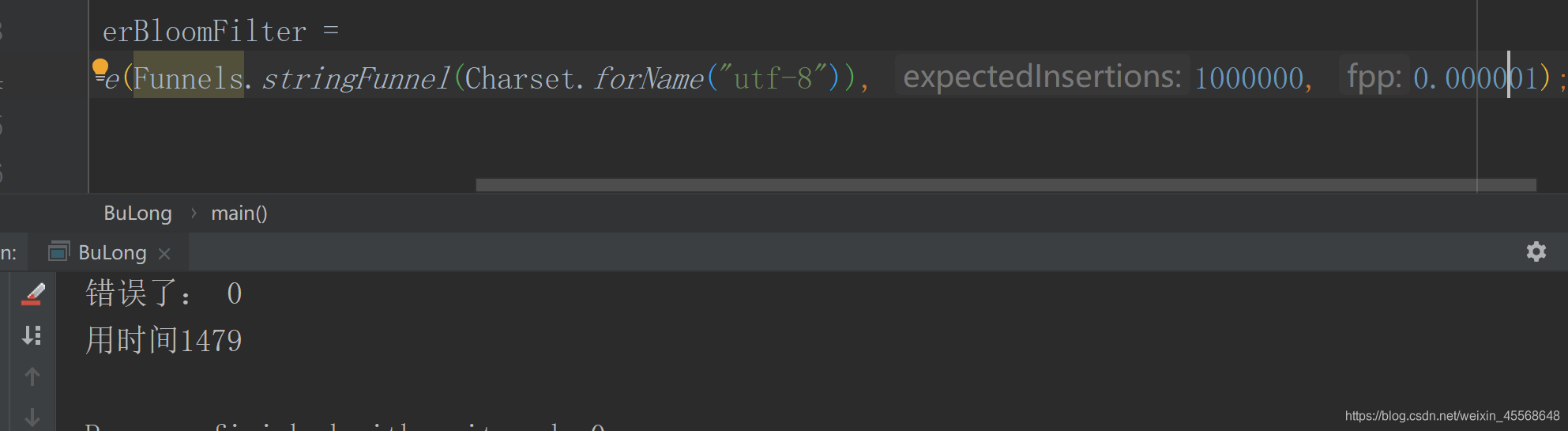
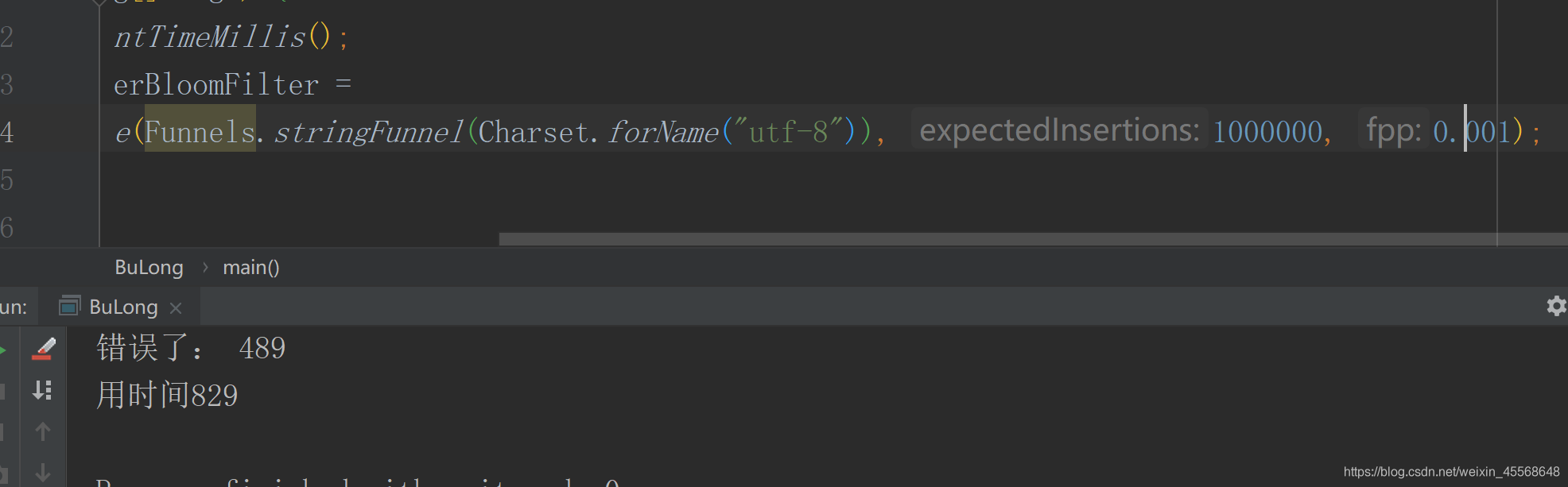
两次结果随着准确率的增高,时间也变长了。
这个是起过滤的作用。如果用来判断数值存在的准确路会是多少?
public static void main(String[] args) {
long begin = System.currentTimeMillis();
BloomFilter<String> integerBloomFilter =
BloomFilter.create(Funnels.stringFunnel(Charset.forName("utf-8")), 1000000, 0.001);
int errorNum = 0;
// 先存数据
for (int i = 0; i < 1000000; i++) {
integerBloomFilter.put(String.valueOf(i));
}
// 这里的数据都是有的100万次
for (int i = 0; i < 1000000; i++) {
if (integerBloomFilter.mightContain(String.valueOf(i))) {
errorNum++;
}
}
long endtime = System.currentTimeMillis();
System.out.println("正确了: " + errorNum);
long time = (endtime - begin) ;
System.out.println("用时间"+ time);
}

也就是如果存在的数据一个都不会漏掉。
redis集成
:
这个对于redis来说就是一个插件。
# 下载布隆过滤器插件
wget https://github.com/RedisBloom/RedisBloom/archive/v2.2.2.tar.gz
# 解压
tar -zxvf v2.2.2.tar.gz
# 进入解压目录之后make
make
核心文件

集成到redis中

重启测试布隆命令,安装完毕插件之后会有多余的命令
127.0.0.1:6379> BF.INSERT
127.0.0.1:6379> BF.MADD #
127.0.0.1:6379> BF.ADD # 添加数据
127.0.0.1:6379> BF.RESERVE # 配置bloomfilter 过滤器(容器和精度)
127.0.0.1:6379> BF.INFO
127.0.0.1:6379> BF.SCANDUMP
127.0.0.1:6379> BF.DEBUG
127.0.0.1:6379> BF.MEXISTS #
127.0.0.1:6379> BF.EXISTS # 判断这个值是否存在
127.0.0.1:6379> BF.LOADCHUNK
基本使用
127.0.0.1:6379> BF.add users value1 # 添加数据
(integer) 1
127.0.0.1:6379> BF.madd users value1 value2 # 添加多个数据
1) (integer) 0
2) (integer) 1
127.0.0.1:6379> BF.EXISTS users value1 # 判断是否存在
(integer) 1
127.0.0.1:6379> BF.EXISTS users value3
(integer) 0
127.0.0.1:6379> BF.mEXISTS users value1 value2 value3 # 判断多个数据是否存在
1) (integer) 1
2) (integer) 1
3) (integer) 0
127.0.0.1:6379> BF.RESERVE user-bm 0.001 10000 # 手动编写 bf 的配置
OK
127.0.0.1:6379> BF.ADD user-bm test
(integer) 1
java操作redis的bf
1、导入依赖
<!-- https://mvnrepository.com/artifact/com.redislabs/jrebloom -->
<dependency>
<groupId>com.redislabs</groupId>
<artifactId>jrebloom</artifactId>
<version>2.0.0-m2</version>
</dependency>
2、测试
import io.rebloom.client.Client;
public class TestBF {
public static void main(String[] args) {
// 布隆过滤器的对象
Client bfClient = new Client("ip", port);
// 创建一个过滤器 ubw是过滤器的一个名字
bfClient.createFilter("ubw",1000,0.1);
// 向bf中添加数据(将这个数据hash运算之后,1000位置中的任意位置,几个块来确定一个元素)
// 添加name到ubw这个过滤器中
bfClient.add("ubw","name");
// 然后再次判断这个值是够存在 ubw,在hash,然后比对。!
// 判断ubw过滤器中是不是有name这个key
System.out.println(bfClient.exists("ubw","name"));
}
}
小结:布隆过滤器,是用来判断数据存不存在的,他判断存在的数据100%正确;判断不存在的数据,会产生一些错误。