1.Hive 是什么,讲一下你理解的 Hive
- 用于数据的统计,提供类 sql 的查询功能,本质上就是将 HQL 转化为 Mapreduce.
- Hive 的数据存储在 hdfs 上。
- Hive 底层数据分析的实现是由 MR 完成。
- 执行程序是运行在 Yarn 上。
2.为什么使用 hive ,hive 的优点,相比较数据库而言
核心点在于 数据量问题,Hive 的数据量是存储在分布式集群的 hdfs 上,所以能存储很大的数据量,而 mysql 存存在本地文件系统中,存储的少量的数据。
由于数据量大,没有索引,Hive 查询数据时需要扫描整张表,又由于 hive 使用 MR 去做数据分析,MR 本身就具有较高的延迟,所以hive 的执行延迟就比较高,mysql 存在本地,数据量小,所以执行延迟就比较低,数据更新问题,hive 是针对数据仓库应用设计的,数据仓库的内容是读多写少的,所以 hive 中不建议对数据的改写,所有的数据都是在加载的时候确定好的。而数据库中的数据经常需要修改。
思考:如何降低 Hive 的延迟,其实就是 Hive 的优化问题,优化的关键点主要在于避免数据倾斜。
3.Hive 数据倾斜问题
Hive的执行是分阶段的,map处理数据量的差异取决于上一个stage的reduce输出,所以如何将数据均匀的分配到各个reduce中,就是解决数据倾斜的根本所在。
1. 找到可能产生数据倾斜的函数尤为关键:
-
如数据量较大的时候,避免使用
count(distinct), count(distinct) 容易产生数据倾斜(原因:某特殊值过多,处理此特殊值的reduce耗时),可考虑使用 group by 代替
。 -
大小表 join 时
,其中一个表较小,但是 key 集中,分发到 某一个 或某几个 reducer 上的数据量远高于平均值。
解决方法
:将key相对分散,并且数据量小的表放在join的左边,这样可以有效减少内存溢出错误发生的几率;再进一步,可以使用map join让小的维度表(1000条以下的记录条数)先进内存。在map端完成reduce。(
新版 Hive 中已对大小表的 Join 做了优化,小表放在左边或者或者右边已经没有明显区别
)。 -
大表 Join 大表时
,注意空 Key 的情况,如果某些 Key 对应的空值较多,那么相同的 key 就会分发到相同的 ruducer 中,从而导致内存不够,如果 空 key 是异常数据造成的,就过滤掉这部分空 key .
如果 空 key 不是异常数据造成的,而且必须包含在 Join 的结果中,此时我们可以将表中 key 为空的字段赋一个随机的值,使得数据均匀地分布在不同地reduce 中。 -
group by
之后维度过小,就是 key 的种类比较少,但是每个 key 下的值特别多,导致处理某几个 key 时,reducer 比较耗时。 -
总结原因如下:
1)、key分布不均匀2)、业务数据本身的特性
3)、建表时考虑不周
4)、某些SQL语句本身就有数据倾斜
-
1.3表现:
任务进度长时间维持在99%(或100%),查看任务监控页面,发现只有少量(1个或几个)reduce子任务未完成。因为其处理的数据量和其他reduce差异过大。
单一reduce的记录数与平均记录数差异过大,通常可能达到3倍甚至更多。 最长时长远大于平均时长。
3.2 数据倾斜的解决方案
3.2.1参数调节:
hive.map.aggr=true
Map 端部分聚合,相当于Combiner
hive.groupby.skewindata=true
有数据倾斜的时候进行负载均衡,当该选项设定为 true,生成的查询计划回有两个 MR job.
第一个 MR job
,Map 的输出结果集合会随机分布到 Reducer中,每个 Reducer 做部分聚合操作,并输出结果,这样处理的结果是相同的 Group by key 有可能会被分发到不同的 Reducer 中,从而达到负载均衡的目的;
第二个 MR job
,再根据预处理的数据结果按照 group by key 分布到 Reducer 中(这个过程保证了相同的 key 被分布到同一个 Reducer 中),最后完成最终的聚合操作。
3.2.2 不同数据类型关联产生数据倾斜
场景:用户表中user_id字段为int,log表中user_id字段既有string类型也有int类型。当按照user_id进行两个表的Join操作时,默认的Hash操作会按int型的id来进行分配,这样会导致所有string类型id的记录都分配到一个Reducer中。
解决方法:把数字类型转换成字符串类型
select * from users a
left outer join logs b
on a.usr_id = cast(b.user_id as string)
3.2.3 总结
如果确认业务需要这样倾斜的逻辑,考虑以下的优化方案:
1、对于join,在判断小表不大于1G的情况下,使用map join
2、对于group by或distinct,设定 hive.groupby.skewindata=true
3、尽量使用上述的SQL语句调节进行优化
4. Hive 性能的优化问题
-
Hadoop 数据处理过程中,有几个显著的特征:
(1)不怕数据量大,就怕数据倾斜。
(2)jobs 数比较多的作业运行效率相对较低,比如即使有几百行的表,如果多次关联多次汇总,产生十几个jobs,没半小时是跑不完的。因为 map reduce 的初始化是很耗时的。
(3)对sum,count来说,不存在数据倾斜问题。
(4)对count(distinct ),效率较低,数据量一多,准出问题,如果是多count(distinct )效率更低。
优化可以从以下几个方面:
4.1 数据量较小时,开启本地模式
set hive.exec.mode.local.auto=true; //开启本地mr
//设置local mr的最大输入数据量,当输入数据量小于这个值时采用local mr的方式,默认为134217728,即128M
set hive.exec.mode.local.auto.inputbytes.max=50000000;
//设置local mr的最大输入文件个数,当输入文件个数小于这个值时采用local mr的方式,默认为4
set hive.exec.mode.local.auto.input.files.max=10;
4.2 fetch 抓取,能不使用 MR 就不适用 MR,设置参数
hive.fetch.task.conversion默认是more,老版本时 less ,该属性修改为more以后,在全局查找、字段查找、limit查找等都不走mapreduce。
4.3 解决数据倾斜问题
1.表的优化
-
大小表的 Join ,使用 mapjoin 让小表先进内存,扫描小表,将其转化成一个Hashtable 的数据结构,并写入本地的文件中,然后将文件加载到 DistributeCache 中, 然后另一个 task 是 一个没有 reduce 的MR 任务,启动 maptasks 扫描大表,在 map 阶段,根据大表的每一条数据去和 distributecache 中 b 表对应的 HashTable 关联,并直接输出结果。
MapJoin 相比较于 Reduce 端的 join ,一定程度上能够避免数据倾斜问题。 -
大表之间的 join ,注意 空key 的处理,如果 不是异常数据造成的,可以直接过滤,如果不是异常数据,可以 用 “字符串 + 随机数” 代替 ,以让这些 空 key 分布到不同的 reducer 中。
2. group by 问题
-
默认情况下,Map 阶段同一 Key 数据分发给同一个 reduce ,当一个 key 数据过大时,就容易数据倾斜。
默认情况下,Map阶段同一Key数据分发给一个reduce,当一个key数据过大时就倾斜了。并不是所有的聚合操作都需要在Reduce端完成,很多聚合操作都可以先在Map端进行部分聚合,最后在Reduce端得出最终结果。
-
解决方案,参数设置
hive.groupby.skewindata = true
-
1. 开启Map端聚合参数设置
(1)是否在Map端进行聚合,默认为True
hive.map.aggr = true
(2)在Map端进行聚合操作的条目数目
hive.groupby.mapaggr.checkinterval = 100000
(3)有数据倾斜的时候进行负载均衡(默认是false)
hive.groupby.skewindata = true
-
当选项设定为 true,生成的查询计划会有两个MR Job。第一个MR Job中,Map的输出结果会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的Group By Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;第二个MR Job再根据预处理的数据结果按照Group By Key分布到Reduce中(这个过程可以保证相同的Group By Key被分布到同一个Reduce中),最后完成最终的聚合操作。
3. count(distinct)
-
数据量小的时候无所谓,数据量大的情况下,由于COUNT DISTINCT操作需要用一个
Reduce Task
来完成,这一个Reduce需要处理的数据量太大,就会导致整个Job很难完成,一般COUNT DISTINCT使用先GROUP BY再COUNT的方式替换.
4. 行列过滤
-
列处理:在SELECT中,只拿需要的列,如果有,尽量使用分区过滤,少用SELECT *。 -
行处理:在分区剪裁中,当使用外关联时,如果将副表的过滤条件写在Where后面,那么就会先全表关联,之后再过滤。
5. JVM 重用
-
JVM重用是Hadoop调优参数的内容,其对Hive的性能具有非常大的影响,特别是对于很难避免小文件的场景或task特别多的场景,这类场景大多数执行时间都很短。 -
Hadoop的默认配置通常是使用派生JVM来执行map和Reduce任务的。这时JVM的启动过程可能会造成相当大的开销,尤其是执行的job包含有成百上千task任务的情况。JVM重用可以使得JVM实例在同一个job中重新使用N次。N的值可以在Hadoop的mapred-site.xml文件中进行配置。通常在10-20之间,具体多少需要根据具体业务场景测试得出。
6.推测执行
为“拖后腿”的任务启动一个备份任务,两个任务处理同一份数据,并最终选用最先成功运行的完成任务的计算结果作为最终结果。
7.压缩
-
map 输出阶段的压缩 -
reduce 输出阶段的压缩
5.Hive中的元数据存储在Derby和MySql中的区别?
Hive元数据默认保存在内嵌的 Derby 数据库中,但derby数据库只能允许一个会话连接,只适合简单的测试。实际生产环境中不适用,不可能只允许一个会话连接,需要支持多用户会话,通常部署的时候会将hive的元数据修改为保存在mysql中。
1、Derby 只支持一个会话连接
2、 MySQL 支持多个会话连接,并且可以独立部署
6. Hive 的底层原理

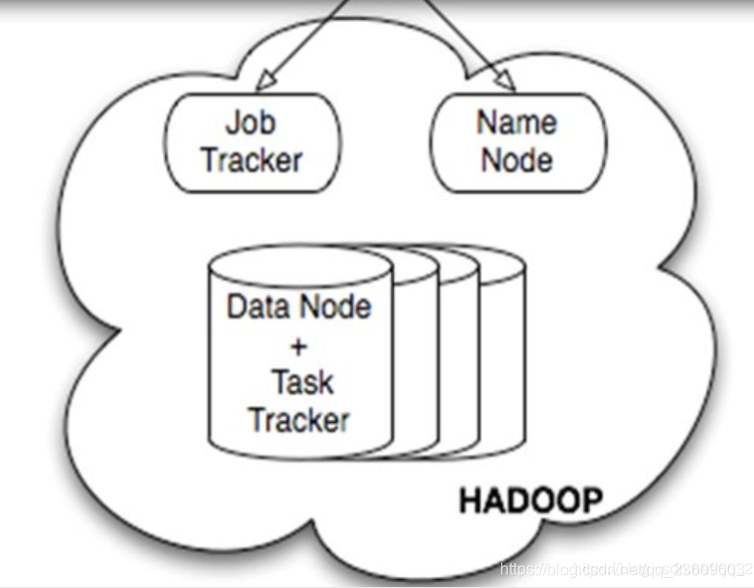
主要分为几个部分来说:元数据模块,Hadoop + hdfs + mr 模块,client (用户接口) driver(驱动模块)。
-
元数据:表名,表所属的数据库(默认时 default),表的拥有者,列/分区字段,表的类型(是否是外部表),表的存储位置。 -
client :主要是接口, CLI(shell 接口),JDBC/ODBC(java 接口), webui 接口(浏览器访问hive) -
hadoop:使用 hdfs 存储数据,使用 mr 计算 -
driver :解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划(plan)的生成。生成的查询计划存储在 HDFS 中,并在随后有 MapReduce 调用执行。
7.内部表(管理表)与外部表的区别
内部表的数据存储在自定义的子目录下,是由 Hive 自身管理的,删除内部表会删除元数据以及表中存储的数据,而外部表的数据存储在 hdfs 上,删除外部表时,只会删除元数据,不会删除存储的数据。
-
外部表与内部表的使用场景
每天将收集到的微博广告日志定期流入HDFS文本文件。在外部表(原始日志表)的基础上做大量的统计分析,用到的中间表、结果表使用内部表存储,数据通过SELECT+INSERT进入内部表。
8.Hive的udf、udaf和udtf了解过吗?自己有没有写过udf?
-
udf 就是在 hive 提供的内置函数(sum,count )无法满足业务需求时,就可以考虑 用户自定义函数,udf 是一进一出的。
-
udaf(user-designed aggregation function) 用户定义聚合函数
聚集函数,多进一出。
类似于 sum,count -
udtf(user-designed table-generating function) 用户自定义表生成函数
一进多出,类似 lateral view explode() over()编程实现步骤:
(1)继承org.apache.hadoop.hive.ql.UDF
(2)需要实现evaluate函数;evaluate函数支持重载;
(3)在hive的命令行窗口创建函数
举个你写udf 的场景,使用 split 分割字符串时,但是字符串中有用 “,” 和 “&”两种,所以不能直接使用 split(),就是用 udf 函数。
9.Hive的存储引擎了解哪些?
Hive支持的存储数的格式主要有:TEXTFILE 、SEQUENCEFILE、ORC、PARQUET。
例如常用默认的textfile,还了解哪些?orcfile。textfile和orcfile有什么区别?行列存储?是行存储还是列存储?
方式存储: Textfile、squencefile
列式存储:orcfile,parquetfile
10.order by 、sort by、distrubute by、clustera by 的区别
-
order by 是全局排序,一个 reducer ,是在所有执行语句的最后执行 -
sort by : 每个 Reducer 内部排序,对全局结果集来说不是排序,一般跟在 分区排序(distrubute by )后,是分区内排序。 -
distrubute by :分区排序,后常跟 sort by -
cluster by : 当 distrubute by 和 sort by 字段相同时就相当于 cluster by
11.分桶与分区的区别
分区针对的是数据的存储路径,是一个文件夹
分桶针对是数据文件。
12 .列转行与行转列
行转列:
-
CONCAT(string A/col, string B/col…):返回输入字符串连接后的结果,支持任意个输入字符串; -
CONCAT_WS(separator, str1, str2,…):它是一个特殊形式的 CONCAT()。第一个参数剩余参数间的分隔符。分隔符可以是与剩余参数一样的字符串。如果分隔符是 NULL,返回值也将为 NULL。 -
COLLECT_SET(col):函数只接受基本数据类型,它的主要作用是将某字段的值进行去重汇总,产生array类型字段。
列转行:
-
EXPLODE(col):将hive一列中复杂的array或者map结构拆分成多行。
用法:LATERAL VIEW udtf(expression) tableAlias AS columnAlias
解释:用于和split, explode等UDTF一起使用,它能够将一列数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合。
13.讲一下窗口函数
一般是我们又想显示聚合前的数据,又想显示聚合后的数据的时候,就用到了窗口函数。
在使用窗口函数 over() 前,要明白 over() 是最后执行的,执行顺序仅位于 order by 前面。
窗口函数:指定分析函数的的工作窗口大小,窗口大小可能随着行的变化而变化。
窗口说明:
n PRECEDING:往前n行数据
n FOLLOWING:往后n行数据
CURRENT ROW:当前行
UNBOUNDED:起点,UNBOUNDED PRECEDING 表示从前面的起点
UNBOUNDED FOLLOWING:表示到后面的终点
默认是自起点到当前行
LAG(col,n):往前第n行数据
LEAD(col,n):往后第n行数据
NTILE(n):把有序分区中的行分发到指定数据的组中,
各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号。
注意:n必须为int类型。
14.rank
-
rank():排序相同时会重复,总数不会变 -
dense_rank():排序相同时会重复,总数会变 -
row_number():排序相同时不重复,根据顺序排序。