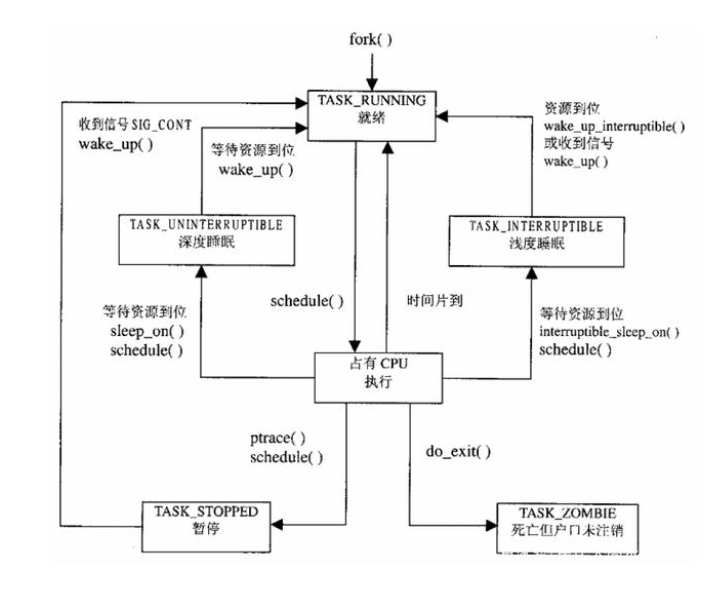
调度域与调度组(CFS 负载均衡)
根域(ld/rt 负载均衡)
腾讯云原生:Linux 内核调度器源码分析 – 初始化 _ 【IIS7站长之家】
调度周期:预期多长时间会执行一次
时间片:在调度周期内分配的运行时间
/proc/sys/kernel 下面有对应的时间
调度延迟:从挂入队列到获得
cpu
资源的等待时间
最小调度粒度:在调度周期内保证的最小运行时间
每个cpu rq 对应cfs_rq 和rt_rq

ps -AT -o cmd,pid,sched,nice,rtprio,pri
查看调度信息

RT
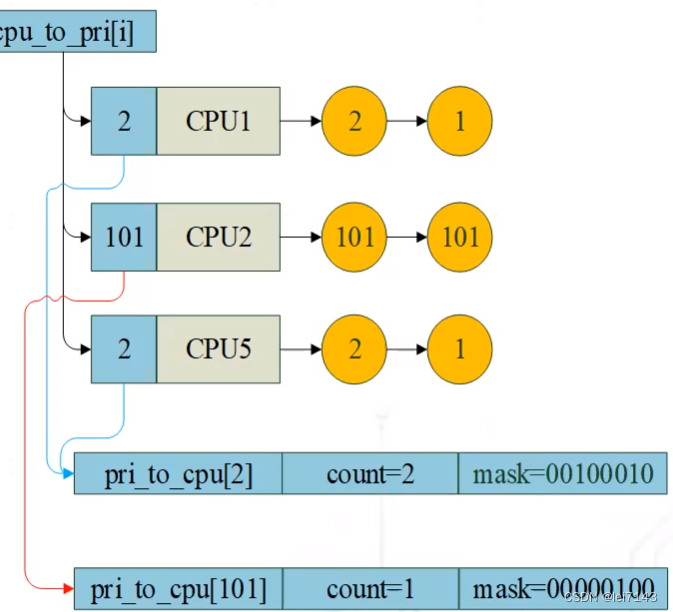
scheduler中的RT调度器,其中有看到一个cpupri,作为选核的一部分,
暂把一个cpu中正在排队以及正在running的所有rt task最高的优先级叫做此cpu的优先级。
根据这个优先级可以对CPU进行排序,
对于RT调度器来讲,其重要任务是保证优先级高的task优先执行,优先级高的task的响应时间也要最快。
假定一个task上面已经有比较高优先级的Task在排队或者run的话,这时候一个就绪的优先级比较低的task加入就得等待,
那么这个task 就会排队,造成runnable,即便是其他cpu上面所有task的优先级都比这个task还低。这样显然不合理。
而cpupri则负责跟踪记录各个cpu中所有task的最高优先级情况,方便后面寻找优先级最低的cpu出来,供RT调度器进行选择。
kernel-4.19/kernel/sched/cpupri.h
1 /* SPDX-License-Identifier: GPL-2.0 */
2
3 #define CPUPRI_NR_PRIORITIES (MAX_RT_PRIO + 2)
4
5 #define CPUPRI_INVALID -1
6 #define CPUPRI_IDLE 0
7 #define CPUPRI_NORMAL 1
8 /* values 2-101 are RT priorities 0-99 */
9
10 struct cpupri_vec {
11 atomic_t count;
12 cpumask_var_t mask;
13 };
14
15 struct cpupri {
//有多少个RT优先级就有多少个元素。每个元素记录吧这个优先级分别是哪些个cpu的最高优先级。所以理论上讲最多只有8个元素是有值的,假定有8个cpu的话。
//102个元素,见convert_prio(),invalid:-1,idle:0,cfs:1,rt:101-prio(0-99)
16 struct cpupri_vec pri_to_cpu[CPUPRI_NR_PRIORITIES];
//一个有多少个cpu就有多少个元素的数组。每个元素代表对应cpu中当前最高优先级的值。
17 int *cpu_to_pri;
18 };
19
20 #ifdef CONFIG_SMP
21 int cpupri_find(struct cpupri *cp, struct task_struct *p,
22 struct cpumask *lowest_mask);
23 int cpupri_find_fitness(struct cpupri *cp, struct task_struct *p,
24 struct cpumask *lowest_mask,
25 bool (*fitness_fn)(struct task_struct *p, int cpu));
26 void cpupri_set(struct cpupri *cp, int cpu, int pri);
27 int cpupri_init(struct cpupri *cp);
28 void cpupri_cleanup(struct cpupri *cp);
29 #endif
RT进程唤醒选核
1. 选择运行优先级最低cpu;
2. 选的核上如果curr优先级比唤醒的低,则会设置TIF_NEED_RESCHED
kernel-4.19/kernel/sched/sched.h
struct root_domain {
786 /*
787 * The “RT overload” flag: it gets set if a CPU has more than
788 * one runnable RT task.
789 */
790 cpumask_var_t rto_mask;
791 struct cpupri cpupri;
792
793 /* Maximum cpu capacity in the system. */
794 struct max_cpu_capacity max_cpu_capacity;
795
}
static int init_rootdomain(struct root_domain *rd){
512 init_dl_bw(&rd->dl_bw);
513 if (cpudl_init(&rd->cpudl) != 0)
514 goto free_rto_mask;
515
516 if (cpupri_init(&rd->cpupri) != 0)
517 goto free_cpudl;
518
519 init_max_cpu_capacity(&rd->max_cpu_capacity);
}
268 /**
269 * cpupri_init – initialize the cpupri structure
270 * @cp: The cpupri context
271 *
272 * Return: -ENOMEM on memory allocation failure.
273 */
274 int cpupri_init(struct cpupri *cp)
275 {
276 int i;
277
278 for (i = 0; i < CPUPRI_NR_PRIORITIES; i++) {
279 struct cpupri_vec *vec = &cp->pri_to_cpu[i];
280
281 atomic_set(&vec->count, 0);
282 if (!zalloc_cpumask_var(&vec->mask, GFP_KERNEL))
283 goto cleanup;
284 }
285
286 cp->cpu_to_pri = kcalloc(nr_cpu_ids, sizeof(int), GFP_KERNEL);
287 if (!cp->cpu_to_pri)
288 goto cleanup;
289
290 for_each_possible_cpu(i)
291 cp->cpu_to_pri[i] = CPUPRI_INVALID;
292
293 return 0;
294
295 cleanup:
296 for (i–; i >= 0; i–)
297 free_cpumask_var(cp->pri_to_cpu[i].mask);
298 return -ENOMEM;
299 }
idle位于0元素,而normal task位于1元素,而后才是按照rt优先级排序的元素。
实际上由于只有rt调度器当中才会调用cpupri_set。所以,对于idle与normal来讲都是位于1元素位置,
75 void init_rt_rq(struct rt_rq *rt_rq)
76 {
77 struct rt_prio_array *array;
78 int i;
79
80 array = &rt_rq->active;
81 for (i = 0; i < MAX_RT_PRIO; i++) {
82 INIT_LIST_HEAD(array->queue + i);
83 __clear_bit(i, array->bitmap);
84 }
85 /* delimiter for bitsearch: */
86 __set_bit(MAX_RT_PRIO, array->bitmap);
87
88 #if defined CONFIG_SMP
89 rt_rq->highest_prio.curr = MAX_RT_PRIO;
90 rt_rq->highest_prio.next = MAX_RT_PRIO;
91 rt_rq->rt_nr_migratory = 0;
92 rt_rq->overloaded = 0;
93 plist_head_init(&rt_rq->pushable_tasks);
94 #endif /* CONFIG_SMP */
95 /* We start is dequeued state, because no RT tasks are queued */
96 rt_rq->rt_queued = 0;
97
98 rt_rq->rt_time = 0;
99 rt_rq->rt_throttled = 0;
100 rt_rq->rt_runtime = 0;
101 raw_spin_lock_init(&rt_rq->rt_runtime_lock);
102 }
103
1、try_to_wake_up 唤醒
2、select_task_rq_rt 选核
3、
find_lowest_task_rt 确定最低优先级
当一个任务被唤醒时候,需要根据任务的类型:
ui
,
task_demand_fit, boost
等,确定起始的调度域,如
ui
可能优先从中核开始调度;
根据任务特性选择是否走快速路径,如当前任务马上就要执行结束,满足一定条件将唤醒进程放在当前或者唤醒进程的
prev_cpu
上;
根据能耗比,选择
idle cpu
,或者当前空闲算力最大的
cpu
;
根据线程类型,进一步修正如,ui选核时候会优先从cpu_cap 大的往小的选;除非当前选核时 候大核超大核全是pri<MAX_RT_PRI;ui线程会选大核
设置重新调度的标志位:
1.
分配时间片用完;
2.
分配时间片没用完但已经保证了最小调度粒度,当前的队列中有虚拟时间更小的任务;
3. set_next_buddy:
唤醒的线程虚拟时间大于
curr
一个时间片;
pick_next_task_rt 选择任务
判断当前进程运行结束后下一个进程的优先级比当前优先级低,就会触发一次
pull_rt_task
的操作;
寻找
rt_rq
的最高优先级,通过位图确认;
选择list
头的任务
每个优先级对应一个列表,里面是属于该优先级的任务,从而根据这些信息选择优先级最高任务执行。
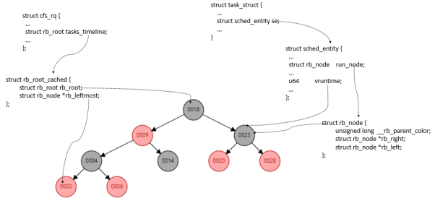
红黑树以虚拟时间为
key
值,每次选择虚拟时间最小的
task_struct
来执行;如果开启了
next_buddy
的
feature,
则
next
满足条件会抢占
left
执行;
2.
普通进程的优先级影响是虚拟时间的计算;
3.
优先级影响了将实际时间片转化为虚拟时间片的比例;
4.
虚拟时间片最终影响(例外:
next_buddy, ui
)选择某个进程
频率影响性能与功耗
P = C * F * V2
在调频的时候一般需要增加电压,当频率增加,功耗增加更加明显;

