Set接口
基本介绍
- set接口的实现集合类都是无序存储的(添加与取出的顺序不一样),且没有索引
- 不允许重复元素,可以添加一个null
Set接口的注意事项
Set接口的常用方法
Set接口和List接口一样都是Collection的子接口,所以Collection的常用方法Set的实现集合类也可以用
Set接口的便利方式
Collection接口的实现类都可以使用迭代器进行遍历,Set接口自然也可以使用迭代器遍历,且增强for循环底层也是迭代器,所以也可以使用增强for循环
Set接口的无序
下面通过一段代码来体现set接口的实现集合类无序存储的体现。
需要注意的是虽然存储和取出的顺序不一样,但是一旦取出那么此集合的顺序就是固定的。
public class test {
public static void main(String[] args) {
Set set = new HashSet();
//存入4个元素
set.add("jack");
set.add("null");
set.add("mary");
set.add("tttt");
System.out.println("取出集合查看集合顺序"+set);
//遍历集合进一步确认是否取出后顺序是固定的
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
Object next = iterator.next();
System.out.print(next+" ");
}
//增强for循环再看一次
for (Object obj:set) {
System.out.print(obj+" ");
}
}
}
输出结果:
取出集合查看集合顺序[null, tttt, mary, jack]
null tttt mary jack null tttt mary jack
可以看到存入的顺序与取出的顺序不一样,但是连续两次遍历的顺序却是一样的。
由于set接口的实现集合类是没有索引的,所以无法通过普通for循环来遍历
HashSet
- HashSet实现了Set接口
- HashSet实际上是HashMap
- 可以存放null,但只能存一个
- HashSet不保证元素的存入顺序和取出顺序是一致的,取决于hash后再确定索引的结果
- 不能有重复的元素/对象
HashSet无法存储重复元素
上面说的无法存储重复元素,其中有一点需要注意:
地址相同的无法重复
例如:add了两次”jack”,那么两次都是保存常量池中的同一个地址,所以无法重复添加进去。
但是如果new了两次Dog对象,名字是相同的,那么是可以添加进去的。因为这是两个对象,他们的地址不同
代码演示
public class test2 {
public static void main(String[] args) {
Set hashSet = new HashSet();
hashSet.add("jack");
hashSet.add("jack");
hashSet.add(new Dog("tom"));
hashSet.add(new Dog("tom"));
System.out.println(hashSet);
}
}
class Dog{
private String name;
public Dog(String name) {
this.name = name;
}
@Override
public String toString() {
return "Dog{" +
"name='" + name + '\'' +
'}';
}
}
运行结果:
[Dog{name=‘tom’}, Dog{name=‘tom’}, jack]
可以看到存了两个地址不同的Dog。
但是如果存是下方这样存储的也是存不进去的
hashSet.add(new String("mary"));
hashSet.add(new String("mary"));
这样也是只会存一个进去,具体为什么得分析源码看看
HashSet底层存储数据的结构
根据上面的无参构造可以看到,HashSet底层是用了HashMap作用存储的
而HashMap底层是用
数组+链表+红黑树
的数据结构存储的
下面就简化了解下什么是数组+链表的数据结构
数组+链表
数组是有序的元素序列
数组+链表实际上就是在数组的空间中里存一个对象(链表的节点),而这个对象的属性next指向另一个对象(另一个节点),另一个对象的属性next又指向另一个对象…以此形成一个链表。而数组有多个下标对于多个元素,每个下标元素就可以存一条链表。类似之前学过的二维数组
图示:
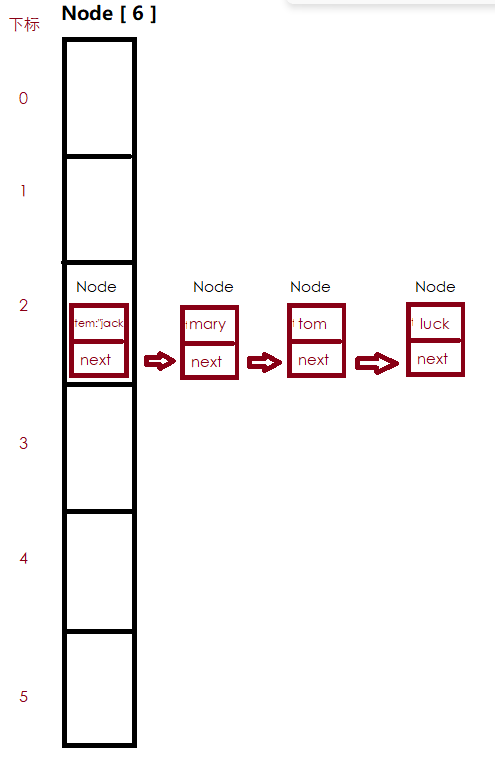
要存储的数据会保存在Node类中的Object item属性中,Node next属性负责指向下一个对象,下一个对象中同样有item和next
代码演示:
public class test3 {
public static void main(String[] args) {
//新建一个Node数组
Node[] nodes = new Node[6];
//在数组的2号下标存入一个节点
nodes[2] = new Node("jack",null);
//创建一个新节点,让上一个节点的next指向这个新节点
nodes[2].next = new Node("mary",null);
//再创建一个节点,让前一个节点的next指向此节点
nodes[2].next.next = new Node("tom",null);
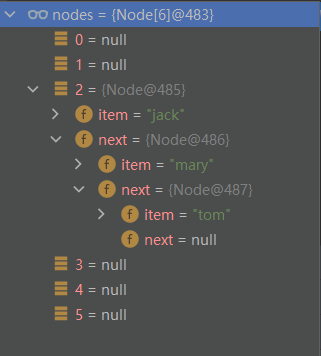
System.out.println(nodes);
}
}
class Node{
public Node(Object item, Node next) {
this.item = item;
this.next = next;
}
Object item;
Node next;
}
最后nodes数组的2号下标就有了一个链表,首先是jack,jack的next指向mary,mary又指向tom
这就是数组+链表的形式,此结构是为了优化存储的效率。而当数组存储不下的时候,又会变成另一种数据结构-
树
。树后面再说
HashSet底层扩容机制
从上面了解到HashSet底层是使用HashMap,而HashMap底层是使用数组+链表的形式存储的。
那么下面了解一下存储的机制,以及扩容的机制。且什么时候会把数组+链表的形式变成树来存储
结论
- HashSet底层是HashMap
- 添加一个元素时,会先得到Hash值,然后通过算法得到索引值
- 然后找到存储数据表table也就是存储数据的数组,看这个数组的这个索引位置是否已经有存放的元素了
- 如果没有任何元素则直接存入
- 如果有元素则通过equals进行比较,如果相同就放弃添加,如果不相同则添加在这个索引位置链表的最后
- 在Java8中,如果一条链表的元素个数到达TREEIFY_THRESHOLD(默认是8),且table数组的大小>=MIN_TREEIFY_CAPACITY(默认是64)就会进行树化(红黑树)
HashSet第一次添加扩容底层源码
HashSet set = new HashSet();
set.add("jack");
set.add("tom");
set.add("jack");
}
-
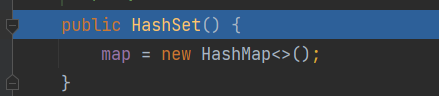
使用无参构造创建一个HashMap实例,通过这里可以看出HashSet底层的确是HashMap
-
接着进入add方法,通过return调用,HashMap的put方法,且传入要添加的元素。另外由于HashMap的put方法必须要传入一个PRESENT(Object实例),占位用的,意义不大

-
进入put方法,通过return调用putVal方法,且将hash(key)方法返回的值传进去,另外的value就是占位的。

-
进入hash方法可以看到,定义了一个int变量h,然后将要保存元素的hash值右移3位,这是为了后面不冲突减少耦合。然后将这个值返回。

-
所以再回到put方法就可以理解,hash(key)等同于要添加元素的hash值算法后的值

-
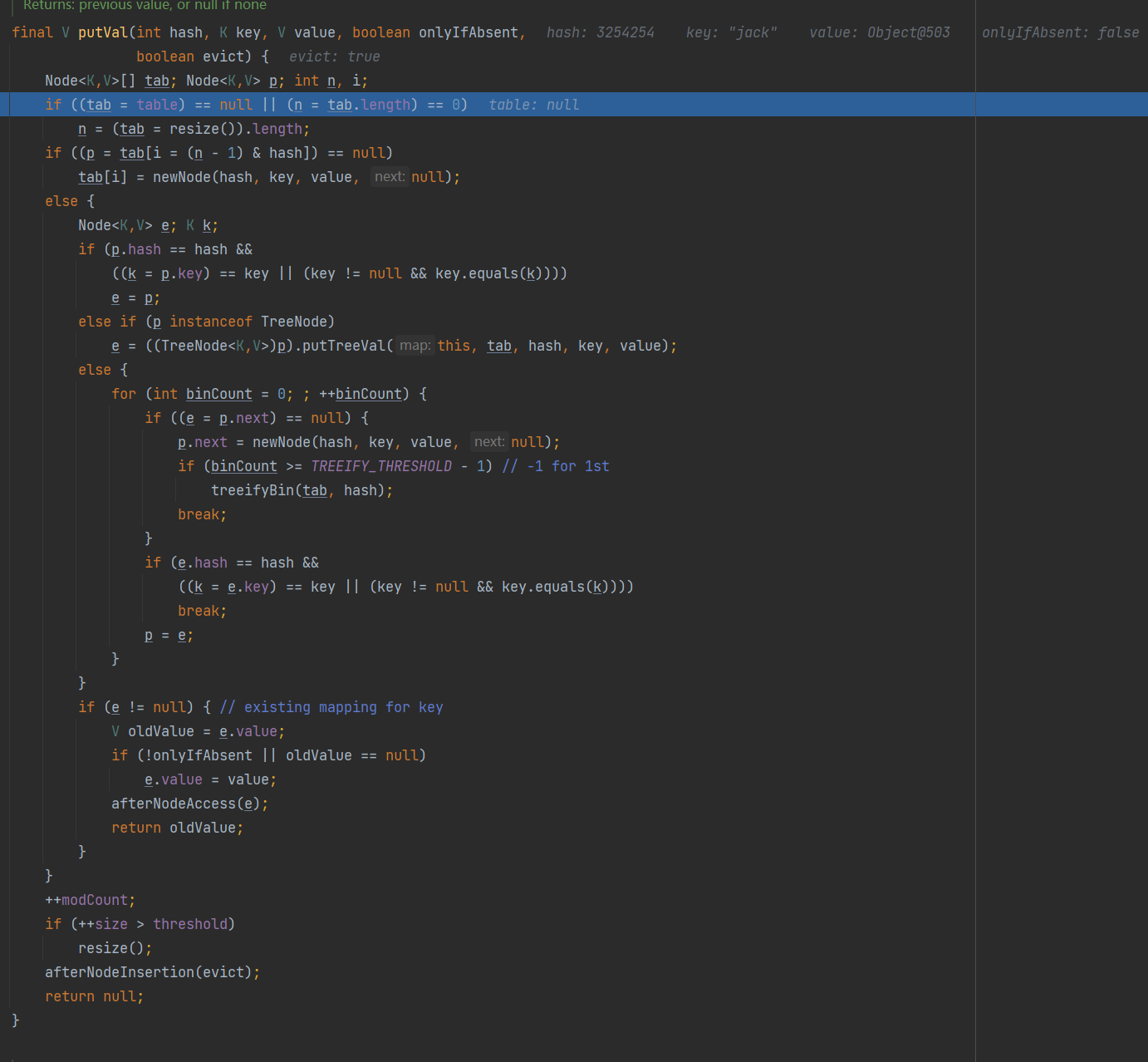
进入putVal方法:(第一次进入)
6.1:首先定义Node<K,V>[] tab; Node<K,V> p; int n, i;这几个辅助的变量
6.2:进入一个if判断,在进入判断之前先把保存数据的数组table备份一份给到tab。然后将tab的长度给n。接着执行判断看是否是第一次进入,如果是第一次进入就调用resize方法进行扩容
-
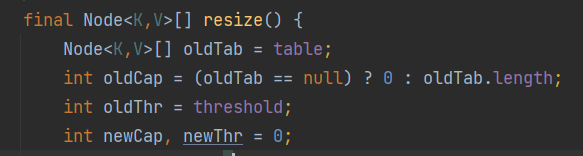
进入resize方法,首先将table备份一个给oldTab,然后将长度给int类型的old Cap,将默认的扩容门槛threshold(12)给oldThr
然后创建 两个int 类型的临时变量 newCap 和 newThr(都是0)
接着将DEFAULT_INITIAL_CAPACITY(默认初始容量)给newCap
将DEFAULT_INITIAL_CAPACITY的75%给newThr,也就是说newThr(扩容门槛)是容量的75%(一旦到达这个门槛就得扩容了)
然后将newThr(新门槛)给成员变量threshold(门槛)。
接着最重要的操作
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];//新定义一个数组,开辟空间为newCap(16)
table = newTab;//然后将newTab给成员变量数组table,最后返回这个数组



-
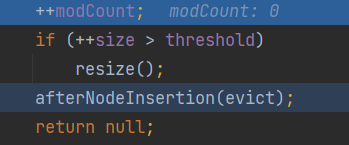
接着回到putVal方法,将table备份给tab,且将他的长度给n。接着进入if判断根据对添加元素的hash值进行算法得到索引,判断索引位置是否有元素,因为是第一次添加,所以肯定没有元素,就直接添加在索引处

-
最后修改次数+1,再判断一下如果再添加一个元素的话是否超过了门槛,如果超过了就进行扩容。最后添加成功返回 null
-
putVal执行完毕回到put,回到add,如果没有添加成功的话返回是是其他,就不会与null相等返回true,就会返回false。

HashSet第二次添加的底层源码
HashSet set = new HashSet();
set.add("jack");
set.add("tom");//执行到这里的时候
set.add("jack");
}
-
进入add方法,通过return调用put方法传入要添加的元素 e 和占位对象PRESENT
此时的e代表“tom” , PRESENT不用在意

-
进入put方法将这里的K key就是要添加的元素“tom”,value代表占位对象
put方法通过return调用putVal方法,且传入要添加元素的hash值(算法后的),和要添加的元素key,value占位对象
hash(key):要添加元素的hash值
key:要添加的元素

-
进入putVal方法
3.1定义辅助变量(临时变量):Node [] tab, Node p ,int n , int i
3.2首先将当前集合储存数据的数组给到临时变量tab,再将tab的长度给到变量 n
3.3接着借用tab和n,判断当前这个集合用于存储数据的数组是不是null,且长度是不是0.
3.4如果有一项成立,就代表是第一次添加.则进入resize方法进行扩容。但是由于这里是第二次添加。所以不进入
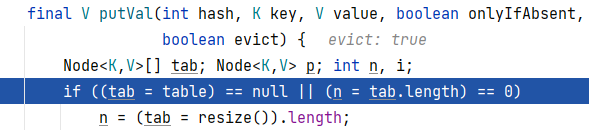
3.5接着又进入一个if判断,这里的 i 代表着通过将添加元素的hash值进行算法后得到的索引。然后将这个索引位置的头号元素给临时变量p
3.6因为第一次添加的元素hash值算法后的索引是14,而这次的得到的索引是3.而此时索引3下面没有任何东西,因此赋了个null给到 p
3.7而p(null) == null,所以进入下方if的执行语句
3.8在存储数组的索引3位置处直接添加一个新节点,将hash值传入,要添加的元素“tom”传入,null是给节点的next变量的
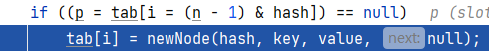
3.9修改次数+1,size+1.且判断一下加了这个元素之后,数组的长度会不会大于门槛。如果大于就要resize扩容一下,最后返回null
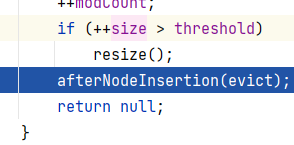
-
putVal执行完毕,返回put执行完毕,返回add。因为返回的也是null,所以add方法返回true。


HashSet第三次添加重复的底层源码
HashSet set = new HashSet();
set.add("jack");
set.add("tom");
set.add("jack");//执行到这里的时候
}
-
进入add方法,通过return调用put方法。传入要添加的元素和一个占位对象
e:“jack”
PRESENT:占位对象

- 进入put方法,通过return调用putVal方法,传入要添加的元素的(无符号右移3位的)hash值和要添加元素的本身,and一个占位对象

3. 进入putVal方法
hash:要添加元素的(向右无符号位移3位的hash值)
key:要添加的元素
value:占位对象
3.1定义辅助变量(临时变量)Node[]tab,Node p , int n,int i
3.2首先将当前集合储存数据的数组给到临时变量tab,再将tab的长度给到变量 n
3.3接着借用tab和n,判断当前这个集合用于存储数据的数组是不是null,且长度是不是0.
3.4如果有一项成立,就代表是第一次添加.则进入resize方法进行扩容。但是由于这里是第三次添加。所以不进入
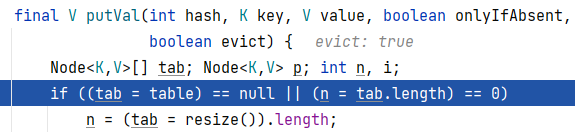
3.5接着通过对hash的算法得到此次要添加索引的下标 14,然后将14给到 i。接着将tab[i]上的头节点给到 p
3.5然后将p和null进行比较。但是由于第一次添加也是“jack”所以他们得到的下标是一样的,因此p此时是tab[14]的头节点对象,而这个头节点对象的key变量保存着“jack”。所以不进入true的执行语句
3.6进入else执行语句,首先定义临时变量Node e,Node k,
3.7然后进入if判断:
将p的hash和此次要添加的hash进行比较
将p保存的key指向的元素给k,将k与此次要添加的元素进行比较
以上两项都为true的话就将p指向的节点复制一份给 e
或者
此次要添加的元素不是null
此次要添加元素的equals方法传入k进行比较返回true时。
当上面两项都为true的话就将p指向的节点复制一份给 e
而此次要传入的是”jack”,而p.key也是“jack”.因此满足下面两条,所以最后p会给e
else执行完毕

4. 如果上面两边的条件都不满足,则进入else if判断此头节点是否是TreeNodeq存在继承的关系。
4.1.如果不存在继承的关系,则进入下面的else语句
4.2首先定义一个临时变量binCount,且进入无线for循环。每循环一次binCount+1.
4.3然后进入循环语句,首先将头节点的下一个节点,也就是第二个节点给到 e。判断第二个节点是不是null
4.4如果是空则直接新建一个节点,将要添加的元素存在新节点的key中,且将此节点变成第二个节点
4.5添加完毕后,进入if判断,根据binCount变量的数值判断是否大于等于7,如果>=了就将这个索引处的链表进行树化然后退出循环
4.6如果第二个节点不等于null,进入下方的比较
将e的hash和此次要添加的hash进行比较**(这里的e在上面的操作已经变成了第二个节点)**
将e保存的key指向的元素给k,将k与此次要添加的元素进行比较
以上两项都为true的话就将p指向的节点复制一份给 e
或者
此次要添加的元素不是null
此次要添加元素的equals方法传入k进行比较返回true时。
当上面两项都为true的话就代表要添加的元素是重复的就直接添加
4.7如果上面的判断都不成立,说明第二个节点保存的元素也跟要添加的元素不一样
4.8那就将第二个节点给到p,此时p就代表第二个节点
4.9直接又重新进入循环,将p.next指向的第三个节点给e,此时e就变成了第三个节点。接着又是判断第三个是不是空,是空就直接新建节点添加,如果不是空,就比较一下第三个节点保存的元素是否与要添加的元素相同。如果不是就继续循环,直到添加或者确认重复
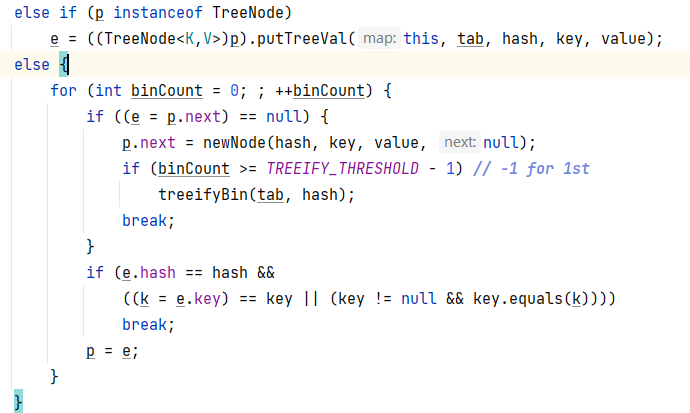
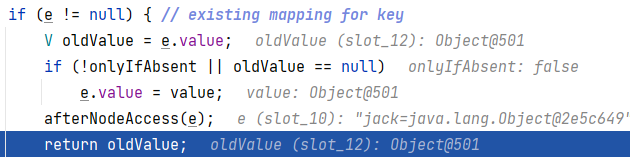
-
最后进入一个if语句,返回oldValue。此次添加就执行完毕了,返回到add。由于返回的不是null,所以添加失败返回一个false
HashSet的扩容与转成红黑树的机制
- HashSet底层是HashMap,第一次添加时table数组扩容到 16 ,临界值threshold是 16*加载因子loadFactor(0.75).所以第一次的扩容临界值是12
-
如果table数组使用到了临界值12,就会扩容到16
2,也就是32,新的临界值就是32
0.75=24.后面也是以此类推 - 再Java8中,如果一条链表的元素个数到达TREEIFY_THRESHOLD(默认是8).且table的大小>=MIN_TREEIFY_CAPACITY(默认是64)就会进行树化(红黑树)。如果链表元素个数达到,数组的大小没达到就是一直扩容数组,直到满足64的条件为止。
注意:上面说的当到达临界值就会扩容数组,底层是使用 ++size>threshold,时就会扩容。而++size并不是表示数组有多少个首节点就是多少。而是每当加入一个Node对象/加入一个元素。就会+1,不管是加在首节点还是某条链表的后面。
HashSet练习
-
定义一个Employee类,该类包含:private修饰的成员属性name,age
要求:
创建3个Employee对象放入HashSet中
当name和age的值相同时,认为是相同员工,不能添加到HashSet集合中
public class HomeWork1 {
public static void main(String[] args) {
Employee e1 = new Employee("jack",12);
Employee e2 = new Employee("mary",21);
Employee e3 = new Employee("jack",12);
Employee e4 = new Employee("mary",21);
Employee e5 = new Employee("mary2",21);
HashSet hashSet = new HashSet();
hashSet.add(e1);
hashSet.add(e2);
hashSet.add(e3);
hashSet.add(e4);
hashSet.add(e5);
System.out.println(hashSet);
}
}
class Employee{
private String name;
private int age;
public Employee(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public int hashCode() {
return 100;
}
@Override
public boolean equals(Object obj) {
Employee obj1 = (Employee)obj;
return this.age==obj1.age&&this.name.equals(obj1.name);
}
}
思路:首先add会先根据hash值判断,所以首先要让hash值一致。可以重写直接返回固定的数,也可以根据name和age一致就返回一样的,不一致就返回原本的。
其次可以重写equals,判断name和age是否相同,如相同就返回true。HashMap的底层会动态绑定使用重写的equals如果返回为true就不添加,false就添加
-
定义一个Employee类,包含私有属性name,sal,birthday(MyDate类型),其中birthday为MyDate类型(包含属性:year,month,day)
要求:
创建3个Employee对象放入HashSet中
当name和birthday的值相同时,认为是相同员工,不能添加到HashSet集合中
/*
*@author WINorYU
*/
@SuppressWarnings({"all"})
public class HomeWork2 {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
hashSet.add(new Employee2("jack",new MyDate(2001,5,21)));
hashSet.add(new Employee2("mary",new MyDate(2002,5,21)));
hashSet.add(new Employee2("jack",new MyDate(2001,5,21)));
hashSet.add(new Employee2("mary",new MyDate(2002,5,21)));
hashSet.add(new Employee2("mary2",new MyDate(2002,5,21)));
System.out.println(hashSet);
}
}
class Employee2{
private String name;
private MyDate birthady;
public Employee2(String name, MyDate birthady) {
this.name = name;
this.birthady = birthady;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
Employee2 e2 = (Employee2) o;
return this.name.equals(e2.name)&& birthady.equals(((Employee2) o).birthady);
}
@Override
public int hashCode() {
return 100;
}
}
class MyDate{
int year;
int month;
int day;
public MyDate(int year, int month, int day) {
this.year = year;
this.month = month;
this.day = day;
}
@Override
public boolean equals(Object obj) {
MyDate myDate = (MyDate) obj;
return this.year==((MyDate) obj).year&&this.month==((MyDate) obj).month&&this.day==((MyDate) obj).day;
}
}
LinkedHashSet
- LinkedHashSet是HashSet的子类
- LinkedHashSet底层是一个LinkedHashMap,它的底层维护了一个数组+双向链表
- LinkedHashSet根据元素的hashCode值决定元素的存储位置(数组下标)同时使用双向链表维护元素的次序
- LinkedHashSet不允许添加重复元素
- LinkedHashSet的存入顺序和取出顺序一致
LinkedHashSet底层存储结构刨析
LinkedHashSet底层遍历是通过双向链表,但是数组中每个索引的位置还保留着一条单向链表。
双向链表按照添加顺序保存,索引的单向链表通过索引前面保存。因此可以看作是一个十字
-
双向链表的连接
LinkedHashSet底层是数组+双向链表的形式,由HashCode决定存储在哪个下标。然后将上一次添加节点的after连接到当前添加的节点,当前添加的节点连接到下一次添加的节点的before。 - 单向链表的连接,当新添加的节点通过hash值计算分配到索引位置时,例如当前索引已经有一个元素,那么此次新添加的元素会先与双向链表进行连接(after,before)。然后再通过next与当前索引位置已有的元素进行连接。
图示:
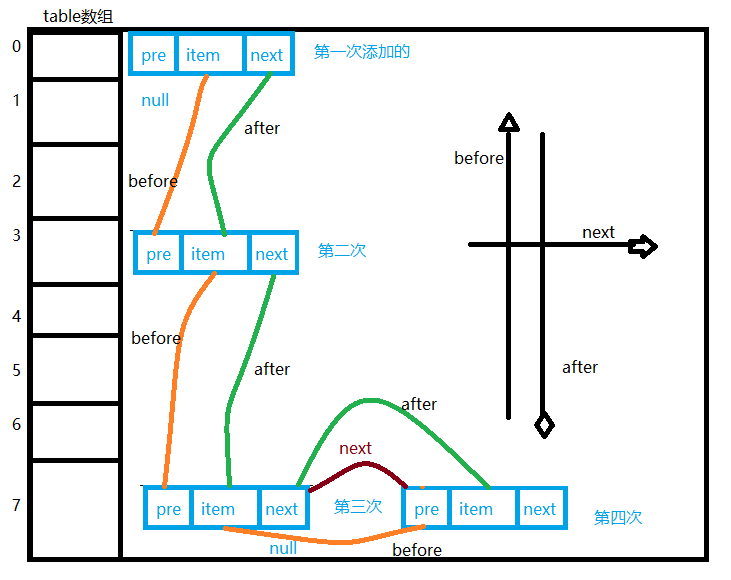
重点说明:
- LinkedHashSet中维护了一个hash表和双向链表
- LinkedHashSet有head和tail,分别指向第一个节点和最后一个节点。类似前面学习双向链表的first和last
- 每一个节点都有before和after属性,分别指向一个节点的前一个节点和后一个节点。类似之前的pre和next,这样可以形成双向链表
- 当在添加一个元素时,和HashSet底层使用的HashMap一样,也是先求hash值,再求索引以此确定在table数组的位置,然后将添加的元素加入到双向链表(如果已经存在则不添加,原则同HashSet)
LinkedHashSet练习
Car类有属性:name和price,如果这两个属性都相同则认为是相同属性,就不能添加
public class Work {
public static void main(String[] args) {
LinkedHashSet set = new LinkedHashSet();
set.add(new Car("奥迪",20000));
set.add(new Car("法拉利",4000000));
set.add(new Car("捷豹",6000000));
set.add(new Car("奥迪",20000));
System.out.println(set);
}
}
class Car{
private String name;
private double price;
public Car(String name, double price) {
this.name = name;
this.price = price;
}
@Override
public String toString() {
return "\nCar{" +
"name='" + name + '\'' +
", price=" + price +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Car car = (Car) o;
return Double.compare(car.price, price) == 0 && Objects.equals(name, car.name);
}
@Override
public int hashCode() {
return Objects.hash(name, price);
}
}