1.join()方法
这个方法通常的使用方式为caller.join(),其中caller为DataFrame类型的数据。先来看join()方法中的参数,具体如下:
| 参数 | 参数说明 |
|---|---|
| other | 要与caller合并拼接的数据。该参数可以接收三种类型的数据分别为:Series,DataFrame以及多个DataFrame组成的list。如果other为Series时,该Series必须设置name属性,在最终返回的DataFrame中,该name属性的值将作为column名出现。 |
| on |
可选参数。规定caller中的字段用来与other进行匹配连接。可以接收三种类型的变量:str,多个str组成的list,以及类array类型的数据。这里指定的是caller中的column列名或者索引层级名,然后用column对应的数据或index与other的index进行对比。也就是说, other只能使用index与caller的index或column进行相等性匹配。 |
| how |
共有四种匹配方式:left(默认)、right、outer、inner。具体这四种方式与SQL中同名的匹配方式相同。 |
| lsuffix、rsuffix | 这两个参数主要用来对caller和other中的同名列进行改名。 |
| sort | 接收bool型参数,默认为False。当为False时,依据how参数对返回的DataFrame进行排序。当为True时,依据连接字段的字典序进行排序。 |
import pandas as pd
import numpy as np
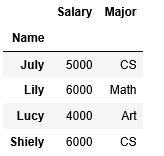
df1=pd.DataFrame({'Name':['July','Shiely','Lucy','Lily'],'Salary':[5000,6000,4000,6000]})
ser1=pd.Series(['US','CN','UK','UK'],index=['July','Shiely','Lucy','Lily'],name='Nation')
df2=pd.DataFrame({'Name':['July','Shiely','Lucy','Joy','Lily'],'Major':['CS','CS','Art','Art','Math']})
df3=pd.DataFrame({'Name':['July','Shiely','Lucy','Lily','Joy'],
'University':['Beking','Beking','Tsing','Tsing','Beking']})
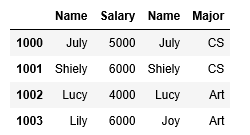
r1=df1.join(ser1,how='inner',on='Name')#用df1.Name字段和Ser1.index匹配
r2=df1.set_index('Name').join(df2.set_index('Name'),how='inner',sort=True)
#这里是将Name属性都设为df1和df2的索引然后再进行匹配连接的。这时候就不用写on条件了,
#同时df1和df2中的Name顺序不一致也可以正常处理。
#同时sort字段实现了按name的字典序重新排序
r3=df1.join([df2.set_index('Name'),df3.set_index('Name')],on='Name',how='outer')
#other为多个DataFrame组成的列表时,只能实现index对index的匹配,这个时候不能设置on参数
#而且df2和df3中不能有相同的columnr1、r2、r3的运行结果分别为:


import pandas as pd
import numpy as np
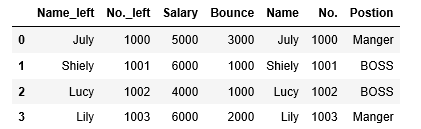
df1=pd.DataFrame({'No.':range(1000,1004),
'Name':['July','Shiely','Lucy','Lily'],
'Salary':[5000,6000,4000,6000]})
df2=pd.DataFrame({'No.':range(1000,1005),
'Postion':['Manger','BOSS','BOSS','Manger','Manger'],
'Name':['July','Shiely','Lucy','Lily','Joy'],
'Bounce':[3000,1000,1000,2000,5000]})
r4=df1.join(df2.set_index(['No.','Name']),on=['No.','Name'],how='inner')
#如果df2中的有多层索引时,需要都出现在on条件中才能正确进行匹配
r5=df1.join(df2,lsuffix='_left',how='inner')#如果没有设置lsuffix或rsuffix则会报错r4、r5的代码运行结果如下:

总结:
- 首先,从join()的参数列表可以看出,join中没有axis参数,所以该方法只能实现按行拼接。
- 其次,该方法不仅能实现两个DataFrame的合并,还可以实现单个DataFrame与单个Series,或与多个DataFrame的拼接。
- 最后,该方法只能用caller的column或index与other的index进行匹配。
2.merge()方法
merge()(通常以left.merge(right)方式使用)方法和join()功能上有些类似,但merge()方法中caller可以和right中的任意index或column进行匹配。具体参数列表如下:
| 参数 | 参数说明 |
|---|---|
| right | DataFrame(到底能不能接收Series,还需要进一步确认) |
| how | 共有四种匹配方式:left、right、outer、inner(默认)。与SQL中类似。 |
| on | 可以接收column或index名。出现在这个参数中column或index必须同时出现在left和righ中。如果为None,则默认使用两个DataFrame中共有的column进行匹配。 |
| left_on、right_on | 可以单独制定left和right的匹配的column或index。当left和right中要匹配的字段名不相同时,则可以使用这两个参数。这两个参数都可以接收label、list或类array的变量。 |
|
left_index、right_idnex |
bool型变量,默认为False。分别使用left或right的index作为连接匹配字段。 |
| sort | 与join()中的同名参数用法相同。 |
| suffixes | 类似join()中的lsuffix和rsuffix。可以接收tuple型变量。 |
| copy | 布尔型变量,默认为True。当为False时,如果可能则避免拷贝。(这个参数具体什么作用,目前还不清楚。) |
| indicator | bool型变量、str型变量。默认为False。当为True时,会在返回的DataFrame中增加一个名为‘_merge’的列来表名每行数据的来源(共三种标记;left_only、right_only、both)。当接收str型变量时,将新增的该列名字改为indicator指定的名字。 |
| validate | 可选变量。接收str型变量。对left和right做检查,如果不符合指定的匹配类型,则直接报错。可指定的检查类型为:one_to_one、one_to_many、many_to_one、many_to_many |
import pandas as pd
import numpy as np
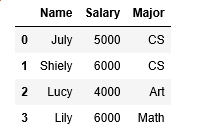
df1=pd.DataFrame({'Name':['July','Shiely','Lucy','Lily'],'Salary':[5000,6000,4000,6000]})
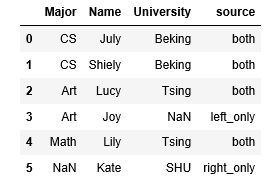
df2=pd.DataFrame({'Name':['July','Shiely','Lucy','Joy','Lily'],'Major':['CS','CS','Art','Art','Math']})
df3=pd.DataFrame({'Name':['July','Shiely','Lucy','Lily','Kate'],
'University':['Beking','Beking','Tsing','Tsing','SHU']})
df4=pd.DataFrame({'No.':range(1000,1004),
'Name':['July','Shiely','Lucy','Lily'],
'Salary':[5000,6000,4000,6000]})
df5=pd.DataFrame({'No.':range(1000,1005),
'Postion':['Manger','BOSS','BOSS','Manger','Manger'],
'Name':['July','Shiely','Lucy','Lily','Joy'],
'Bounce':[3000,1000,1000,2000,5000]})
r1=df1.merge(df2.set_index('Name'),left_on='Name',right_index=True)
#df1.merge(df2,on='Name')
r2=df2.merge(df3,how='outer',indicator='source',validate='one_to_one')
r3=df4.merge(df5,on='No.',suffixes=('_left','_right'))
r4=df1.set_index('Name').merge(df2.set_index('Name'),left_index=True,right_index=True)r1、r2、r3、r4的运行结果分别如下:
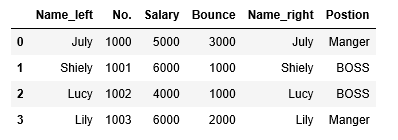
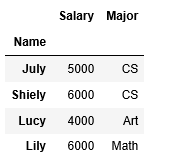
总结:
- merge()方法和join()方法实现的功能相似,都是按行拼接。但merge()的用法更灵活。不仅支持index-on-index和column-on-index,还支持column-on-column。
3.pd.concat()方法
| 参数 | 参数说明 |
|---|---|
| objs | 待合并的数据。可以接受Series、DataFrame、Panel对象组成的序列或映射型数据。如果objs中有为None的对象,则默认直接删除。(但如果objs中全为None,则报错) |
| axis |
可取0或1(默认为0)。指定objs的合并拼接方向。当为0时,为按列拼接。 当axis=1时,则与join()、merge功能类似,此时依据index进行合并,即index相同的会合并到同一行去。 |
| join | 可以取inner和outer(默认值)。用来指定如何处理非axis指定的轴上的index |
| join_axes |
可接收index对象组成的列表。 |
| ignore_index | 布尔型变量。默认为False。当为True时,会重新指定返回值的索引 |
| keys | 可接收序列型数据。构建层次索引的最外层。objs中的每一个元素对应一个keys中的一个元素。还需要说明的是:一旦设置了keys,其长度必须大于等于1。如果keys的长度<objs的长度时,以keys的长度为准,剩下的objs不合并。如果keys的长度>objs的长度时,objs全部输出。 |
| levels | 可以接收序列组成的list作为参数。指定特定的层级构建复合索引。(这个参数到底怎么用,还需要进一步研究)。 |
| names | 可接收list型变量。默认值为None。用来指定层次索引的名字 |
| verify_integrity | bool型变量,默认为False。主要是检查新的合并的轴上是否有重复值。 |
| sort |
0.23.0版本之后的新增参数。 |
| copy | 与merge()中的同名参数作用相同。 |
import pandas as pd
se1=pd.Series(['July','Shiely','Lucy','Lily'])
se2=pd.Series([5000,6000,4000,6000],index=range(1000,1004))
r1=pd.concat({'name':se1,'salary':se2},axis=0,join='outer')
#se1和se2也可以放在list或tuple里
r2=pd.concat({'name':se1,'salary':se2},axis=0,join='outer',ignore_index=True)
#使用dict进行数据传输的时候,字典的键会作为外层索引的名字或列名
#所以这里series.name可以为None
#使用了ignore_index之后,会重新给返回结果设置索引
df1=pd.DataFrame({'Name':['July','Shiely','Lucy','Lily'],'Salary':[5000,6000,4000,6000]},index=range(1000,1004))
df2=pd.DataFrame({'Name':['July','Shiely','Lucy','Joy','Lily'],'Major':['CS','CS','Art','Art','Math']},
index=range(1000,1005))
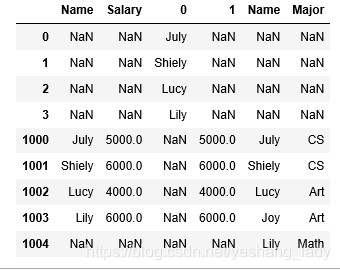
r3=pd.concat((df1,df2),axis=0,join='inner',sort=False)
#join作用,当axis=0时,则只保留两个待合并元素中的相同column
#当axis=1时,则只保留两个待合并元素中的相同index
r4=pd.concat((df1,df2),axis=1,join='inner',sort=False)
r5=pd.concat([df1,se1,se2,df2],axis=1,join='outer')
#pd.concat()支持同时合并多种类型的数据r1、r2、r3、r4、r5的返回结果依次如下
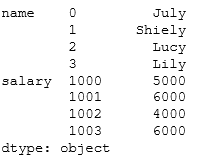
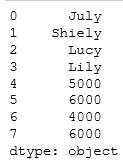

import pandas as pd
df1=pd.DataFrame({'No.':range(1000,1004),
'Name':['July','Shiely','Lucy','Lily'],
'Salary':[5000,6000,4000,6000]})
df2=pd.DataFrame({'No.':range(1000,1005),
'Postion':['Manger','BOSS','BOSS','Manger','Manger'],
'Name':['July','Shiely','Lucy','Lily','Joy'],
'Bounce':[3000,1000,1000,2000,5000]})
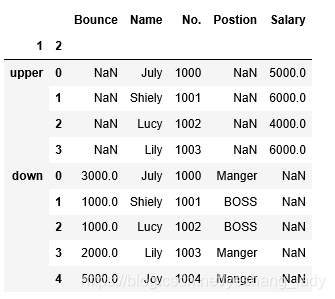
r1=pd.concat([df1,df2],keys=['upper','down'],names=['1','2'])
总结:
- 在使用方法上,join和merge都支持DataFrame.join()\merge()形式,但concat()方法不是DataFrame自带的方法,所以只能通过pd.concat()方式来使用该方法。基于此,pd.concat()支持更多类型的数据合并。不仅支持DataFrame之间的合并,也支持Serie之间的合并。
- 在axis=0轴上进行合并时,其功能类似于append。而当axis=1时,其功能类似于join或merge,但此时只能将index相同数据合并到同一行。若要依据其他column进行合并的话,则需要先将改列设为index。
参考资
1.
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.join.html
2.
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.merge.html
3.
https://pandas.pydata.org/pandas-docs/version/0.23.4/generated/pandas.concat.html