文章目录
数据准备
建表
create table analyse_tmp.tmp_prov_shop_20220714
(prov_name string
,shop_id string
,sale_amt double)
插入数据
INSERT OVERWRITE TABLE analyse_tmp.tmp_prov_shop_20220714
values ('安徽省','001',100),
('安徽省','001',120),
('安徽省','002',150),
('安徽省','002',140),
('浙江省','003',80),
('浙江省','003',150),
('浙江省','004',120)
数据含义
每条数据表示某个省份下面的某个门店的销售金额(为了简化说明,省去了日期,所以会有一个门店多条的数据)
Cube
语法
在group by 语句后直接加 with cube就行,如下
select
prov_name
,shop_id
,sum(sale_amt) sale_amt
from analyse_tmp.tmp_prov_shop_20220714
group by prov_name,shop_id
with cube
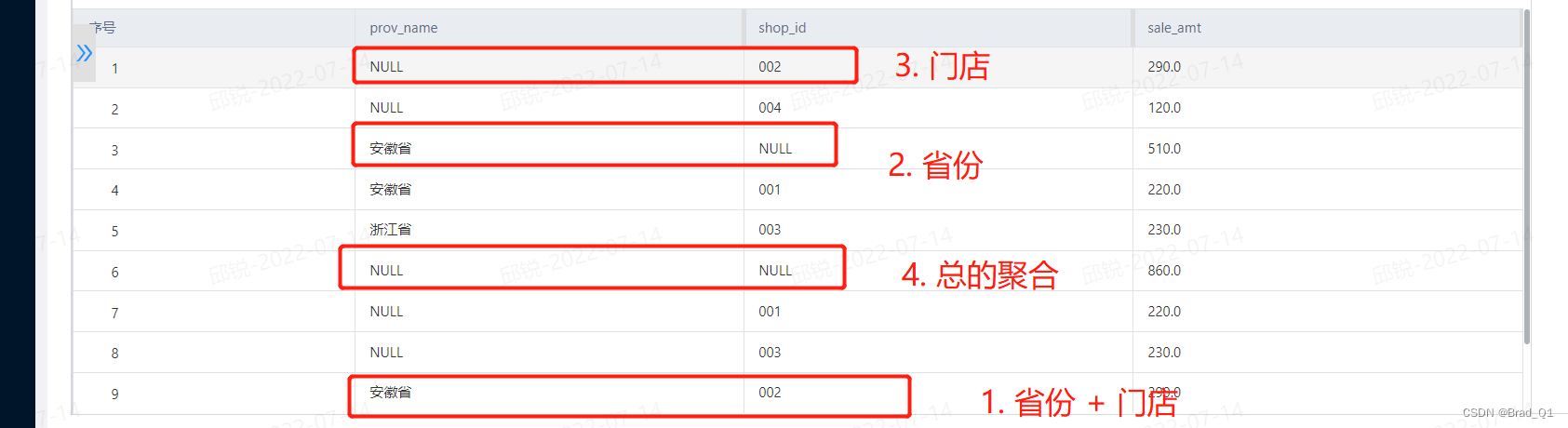
Cube解释
如上图所示,cube是在各个维度上面进行聚合,原本是有两个维度:省份+门店,那么组合起来会有:
- 聚合省份+门店
- 只聚合省份
- 只聚合门店
- 计算总数的聚合
grouping sets
语法
cube会一次性把所有的维度都聚合了,有时候不够灵活,所以如果要定制化的话,可以使用grouping sets, 比如目前只关注省份
或者
门店的维度
select prov_name
,shop_id
,sum(sale_amt) sale_amt
from analyse_tmp.tmp_prov_shop_20220714
group by prov_name,shop_id
grouping sets
(prov_name,shop_id)
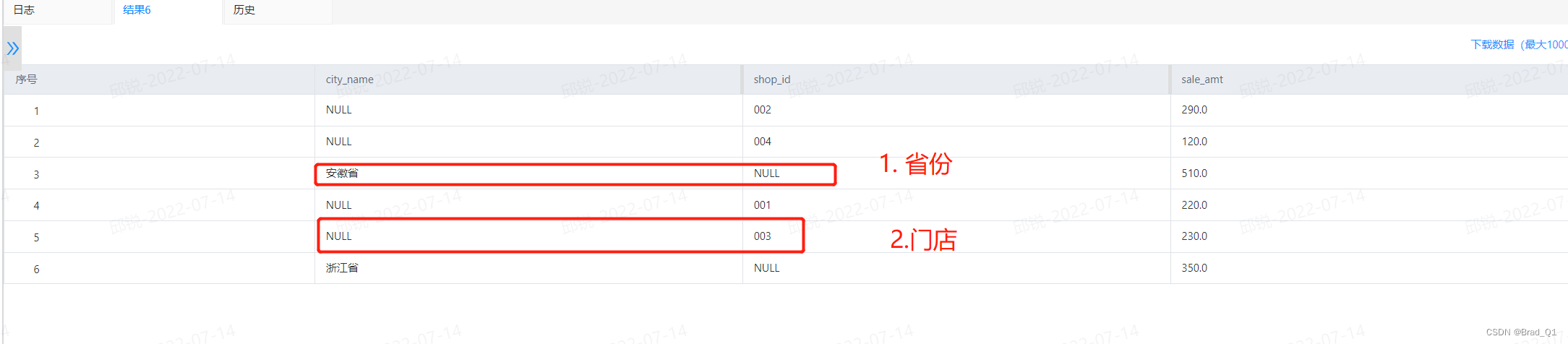
grouping sets解释
grouping sets 会根据括号里面的内容依次进行单个的group by 操作,而把其他的值放空,所以会看到上面截图中,要么省份的聚合,要么门店聚合的情况。
现在如果是要打算同时聚合省份+门店要怎么操作呢,其实就是在括号里面再加上一个括号,里面加上(city_name,shop_id) 就行,文字不懂的话可以看下面的代码:
select prov_name
,shop_id
,sum(sale_amt) sale_amt
from analyse_tmp.tmp_prov_shop_20220714
group by prov_name,shop_id
grouping sets
(prov_name,shop_id,(prov_name,shop_id))
结果展示:
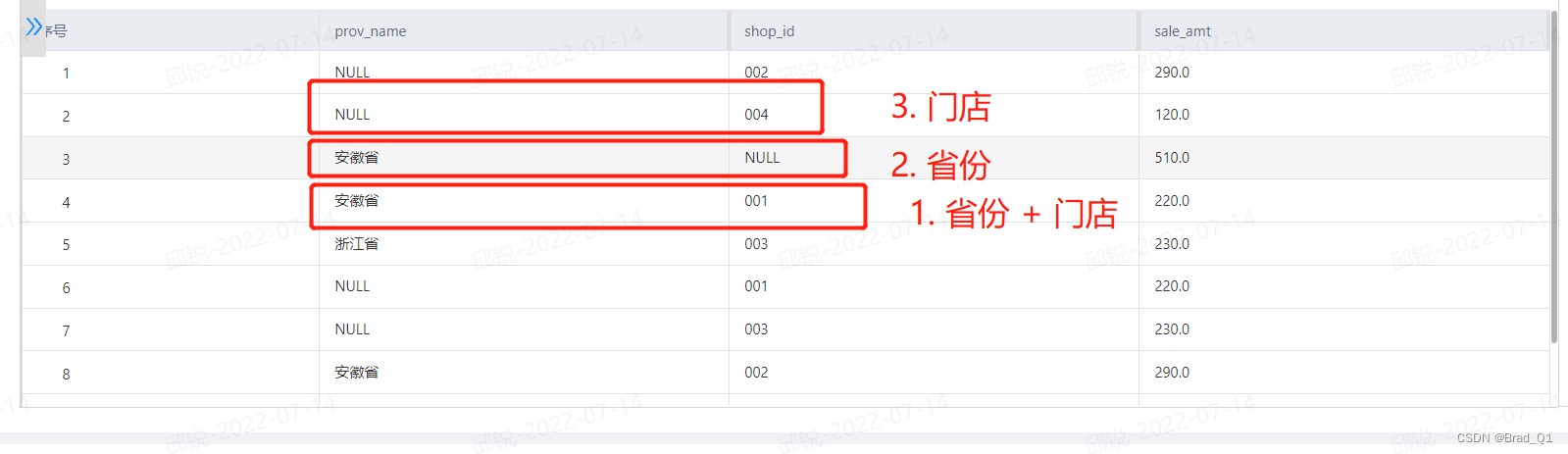
grouping__id
语法
grouping__id可以直接放在select 语句中使用,例如上述的例子中
select Grouping__ID
,prov_name
,shop_id
,sum(sale_amt) sale_amt
from analyse_tmp.tmp_prov_shop_20220714
group by prov_name,shop_id
grouping sets
(prov_name,shop_id,(prov_name,shop_id))
不过这里打算以全部的维度组合,也就是cube的方式看grouping__id的例子,具体实现如下(在上面的grouping sets语句中再加一副“括号”,用来实现计算总数的聚合),代码如下
select Grouping__ID
,prov_name
,shop_id
,sum(sale_amt) sale_amt
from analyse_tmp.tmp_prov_shop_20220714
group by prov_name,shop_id
grouping sets
(prov_name,shop_id,(prov_name,shop_id),())

这里面需要注意的是grouping__id的顺序跟group by字段的顺序有关,会按照:
- 先所有字段聚合,也就是省份+ 门店
- 按照group by中第一个字段聚合,这里也就是省份
- 按照group by 第二个字段聚合,这里是门店
- 总的聚合(也就是全表聚合,即sql中 SELECT SUM(sales_amt) FROM analyse_tmp.tmp_prov_shop_20220714)
上述顺序依次做grouping__id的增长
grouping__id的具体应用
grouping__id可以在SQL中先加工成不同维度的名称(比如该字段名字叫dim_name)。这样在BI报表中,不同的用户,比如门店的用户只关注门店的销售额可以通过筛选相关的门店维度,只查看门店的销售额;而省区的负责人可以通过查看省区的维度,查看跟自己相关的省区数据,实现同一张报表满足不同层级用户查看数据的需求。
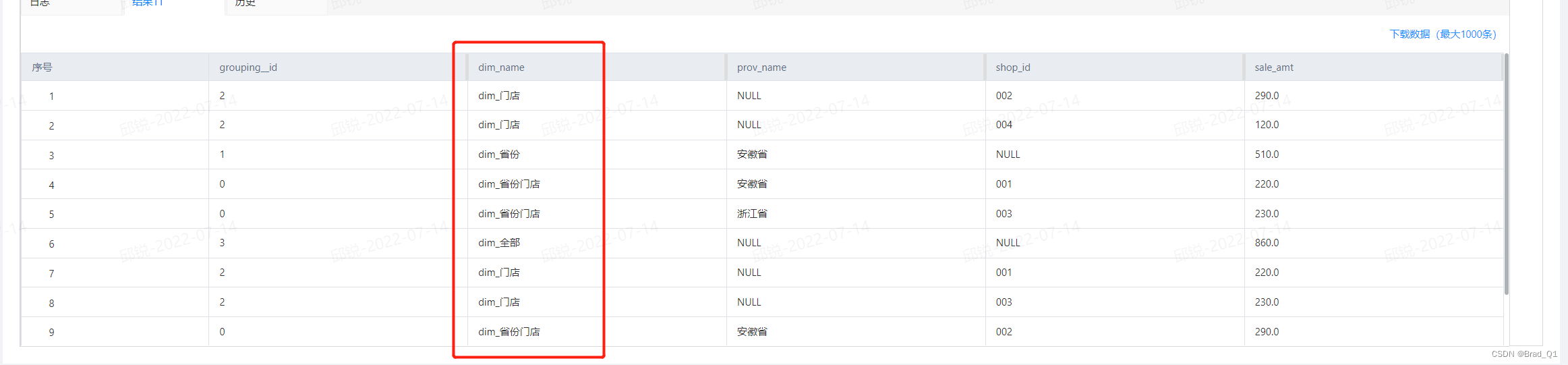
下面对比之前截图的grouping__id和可以产生维度组合:
-
0 表示的是prov_name和shop_id的组合,这样dim_name对应该组合的字段值是
dim_省份门店
-
1 表示的是prov_name,那dim_name对应的值是
dim_省份
-
2 表示的是shop_id,那dim_name对应的值是
dim_门店
-
3 表示的是总的聚合,那么dim_name对应的值是
dim_全部
先看下效果,如下:
那么要怎么通过grouping__id去实现这个效果呢?
可以通过类似位运算去具体的实现(也就是二进制)。 再看下上面的内容(先不看3这种对应全部的情况):

从图中可以看出,如果需要grouping__id转化为最终报表中业务人员可以理解的dim_name,中间需要做一次转换,也就是十进制转二进制。我们知道一般十进制转二进制,都是要通过与2不断的取模来实现,具体的实现SQL如下。
SQL解释
- power函数是取2的整数次方,得出的是浮点类型(也就是带有小数)
- 然后需要取整,这里使用floor函数,用其他函数也可以
- 再外面是grouping__id 跟上面得出的2的整数次方取取模
-
需要额外说明的是3是特殊处理的,如果不处理会变成
dim_
。 也就是后面跟的两个if语句中,第一个省份以及第二个门店的二进制位上都没有取到数据,这样判断下来都取的空字符串,再跟
dim_
拼接后还是
dim_
,这样对与前端用户显然是不友好的。
select Grouping__ID
,concat('dim_',if(Grouping__ID = 3,'全部','')
,if(cast(Grouping__ID AS INT ) & floor(power(2,1)) = 0,'省份','')
,if(cast(Grouping__ID AS INT ) & floor(power(2,0)) = 0,'门店','')
) as dim_name
,prov_name
,shop_id
,sum(sale_amt) sale_amt
from analyse_tmp.tmp_prov_shop_20220714
group by shop_id,city_name
grouping sets
(shop_id,prov_name,(prov_name,shop_id),())