YOLACT:Real-time Instance Segmentation
这篇文章精度不高(mAP=29.8%),但是速度上有了较大的提升(33fps),能够达到实时级别。文中提到训练时只用了一个GPU,titanx。我下载源码用4块1080Ti卡跑的时候,采用COCO2014数据集,默认max_iter为400000次,batchsize为8,显示需要34天。看了下代码,感觉很复杂,数据预处理部分参考的是SSD源码实现中的预处理部分,处理方式比较全,可以借鉴。
**主要创新点:**将实例分割任务分成两个并行的过程:1.产生一系列的模板mask。2.预测每个实例mask的系数。之后将模板mask和实例mask系数进行线性组合来获得实例的mask,在此过程中,网络学会了如何定位不同位置、颜色和语义实例的mask。
目前的实例分割方法
聚焦于精度而不是速度,本文的目标是建立快速的单级实例分割模型。两级实例分割像Mask RCN在模板mask上非常依赖于特征定位准确与否(将roi pooling换为roi align),单级的实例分割方法如FCIS是并行的,但是引入inside/outside score maps处理定位问题,仍然达不到实时性的要求。
本文的主要内容
就是在单级目标检测网络基础上添加一个mask分支,但是不包含特征定位步骤(如roi align)。
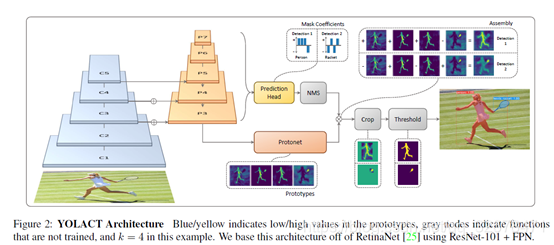
对于Prediction Head部分下面这张图表达地更清楚:
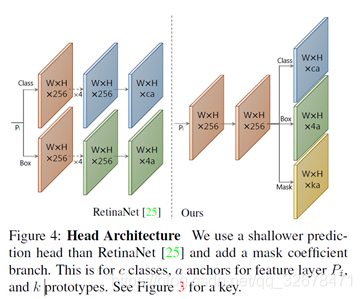
**我的理解是:**基网络增加一个分支输出“prototype mask”,原目标检测分支增加mask coefficients的输出。
可以这样做的原因是卷积层可以保持特征相关性,它的输出可以作为mask,而fc层在产生语义向量上有优势,适合产生mask coefficients。
因为模板mask和mask coefficients的计算是可以分别进行的,所以检测器的主要计算就花费在两者的组合上,但这可以用用单个矩阵相乘来实现。这样一来,可以在特征域上保持空间相关性的同时保持单级网络的快速性。
基网络最后一输出有k个channel,每个channel对应一个mask,目标检测过程增加一个分支计算k个mask系数。
将产生模板的分支和产生mask系数的分支使用线性组合的方法进行结合,并对组合结果使用Sigmoid非线性化来获得最终的mask,该过程可以用单个矩阵相乘的方法来高效实现。
损失函数:
1.分类损失Lcls
2.边界框回归损失Lbox
3.mask损失Lmask = BCE(M,Mgt),M是预测mask,Mgt是真实的mask,公式为两者像素级二进制交叉熵。
传统NMS:
1.将所有框的得分排序,选中最高分及其对应的框
2.遍历其余的框,如果和当前最高分框的IOU大于一定阈值,就将框删除
3.从未处理的框中继续选一个得分最高的,重复上述过程
Fast NMS:
1.对每一类的得分前n名的框互相计算IOU,得到cxnxn的矩阵X(对角矩阵),对每个类别的框进行降序排列。
2.其次,通过检查是否有任何得分较高的框与其IOU大于某个阈值,从而找到要删除的框,通过将X的下三角和对角区域设置为0实现。这可以在一个批量上三角中实现,之后保留列方向上的最大值,来计算每个检测器的最大IOU矩阵K。
3.最后,利用阈值t(K<t)来处理矩阵,对每个类别保留最优的检测器。