基于近年来图像处理和语言理解方面的技术突破,融合图像和文本处理的多模态任务获得了广泛的关注并取得了显著成功。
文本生成图像(text-to-image)是图像和文本处理的多模态任务的一项子任务,其根据给定文本生成符合描述的真实图像,具有巨大的应用潜力,如视觉推理、图像编辑、视频游戏、动画制作和计算机辅助设计。
目前,各种各样的模型已经开发用于文本到图像的生成,模型主要可以分为三大类:扩散模型(Diffusion Model)、自回归模型(Autoregressive Model)、生成对抗网络模型(Generative Adversarial Networks),下面梳理一些近几年重要的模型并对比这三种方法的优劣:
一、基本原理
1.1、扩散模型(Diffusion Model)
扩散模型是一类生成模型,其通过迭代去噪过程将高斯噪声转换为已知数据分布的样本,生成的图片具有较好的多样性和写实性。
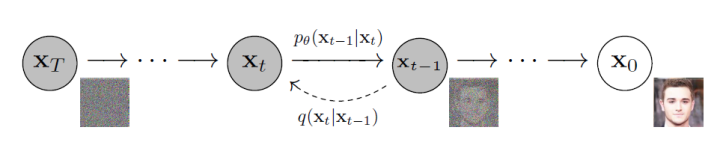
扩散过程逐步向原始图像添加高斯噪声,是一个固定的马尔科夫链过程,最后图像也被渐进变换为一个高斯噪声。而逆向过程则通过去噪一步步恢复原始图像,从而实现图像的生成。
随机输入一张高斯噪声显然不能按照人的意愿生成我们想要的内容,我们需要将一些具体的指导融入扩散模型中去,如:Classifier Guidance、Semantic Diffusion Guidance、Classifier-Free Guidance。

扩散模型在实现文本生成图像上大概有以下策略:
- 使用外部模型(分类器 or 广义的判别器)的输出作为引导条件来指导扩散模型的去噪过程,从而得到我们想要的输出;
- 直接把我们想要的引导条件 condition 也作为模型输入的一部分,从而让扩散模型见到这个条件后就可以直接生成我们想要的内容。
这两种想法可以将普通扩散模型改进为引导扩散模型(Guided Diffusion),并对生成的图像进行一定程度上的细粒度控制。
1.2、自回归模型(Autoregressive Model)
自回归模型模型利用其强大的注意力机制已成为序列相关建模的范例,受GPT模型在自然语言建模中的成功启发,图像GPT(iGPT)通过将展平图像序列视为离散标记,采用Transformer进行自回归图像生成。生成图像的合理性表明,Transformer模型能够模拟像素和高级属性(纹理、语义和比例)之间的空间关系。Transformer整体主要分为Encoder和Decoder两大部分,利用多头自注意力机制进行编码和解码。
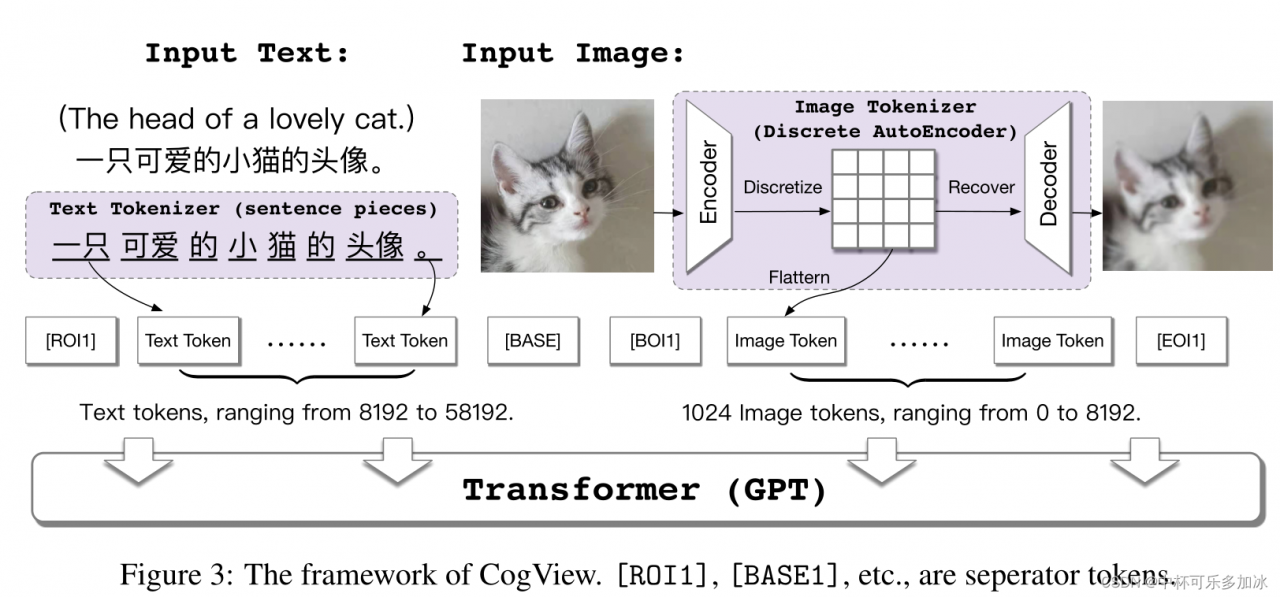
自回归模型在实现文本生成图像上大概有以下策略:
- 和VQ-VAE(矢量量化变分自动编码器)进行结合,首先将文本部分转换成token,利用的是已经比较成熟的SentencePiece模型;然后将图像部分通过一个离散化的AE(Auto-Encoder)转换为token,将文本token和图像token拼接到一起,之后输入到GPT模型中学习生成图像。
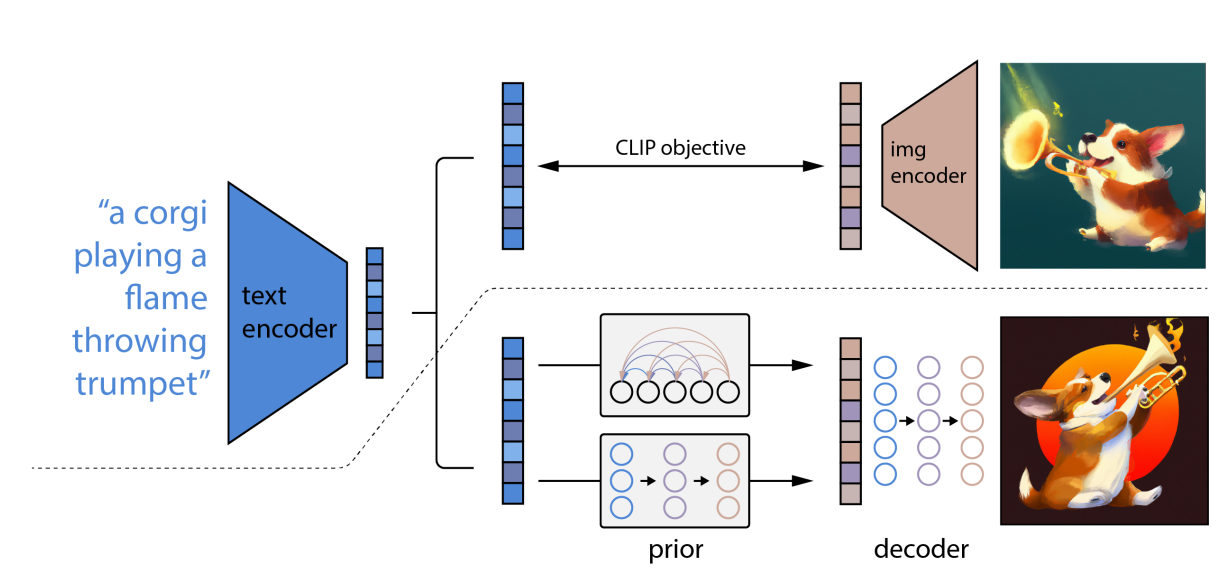
- 和CLIP结合。首先对于一幅没有文本标签的图像,使用 CLIP 的图像编码器,在语言-视觉(language-vision)联合嵌入空间中提取图像的 embedding。接着,将图像转换为 VQGAN 码本空间(codebook space)中的一系列离散标记(token)。最后,再训练一个自回归 Transformer,用它来将图像标记从 Transformer 的语言-视觉统一表示中映射出对应图像。经过这样的训练后,面对一串文本描述,Transformer 就可以根据从 CLIP 的文本编码器中提取的文本嵌入(text embedding)生成对应的图像标记(image tokens)了。
1.3、生成对抗网络模型(Generative Adversarial Networks)
生成对抗网络包含一个生成模型和一个判别模型。其中,生成模型负责捕捉样本数据的分布,而判别模型一般情况下是一个二分类器,判别输入是真实数据还是生成的样本。整个训练过程都是两者不断地进行相互博弈和优化。生成器不断得生成图像的分布不断接近真实图像分布,来达到欺骗判别器的目的,提高判别器的判别能力。判别器对真实图像和生成图像进行判别,来提高生成器的生成能力。
生成对抗网络实现文本生成图像主要分为三大部分:文本编码器、生成器和鉴别器。文本编码器由RNN或者Bi-LSTM组成,生成器可以做成堆叠结构或者单阶段生成结构,主要用于在满足文本信息语义的基础上生成图像,鉴别器用于鉴别生成器生成的图像是否为真和是否符合文本语义。
生成对抗网络模型在实现文本生成图像上主要有以下策略:
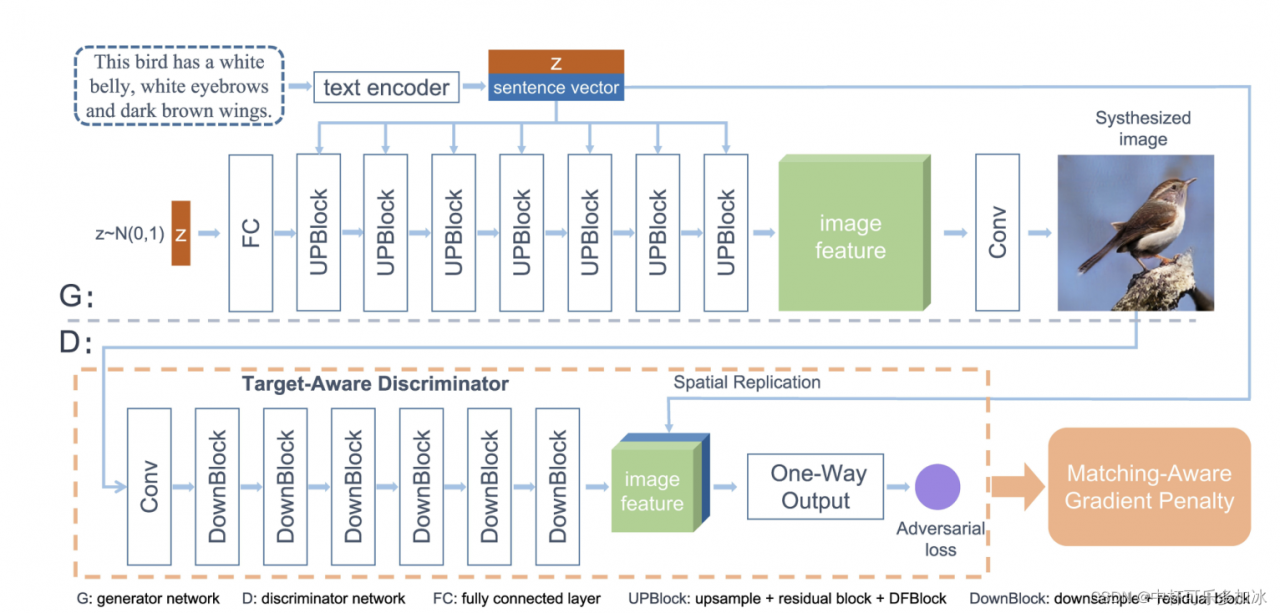
- 多阶段生成网络。由树状结构堆叠的多个生成器(G)和多个鉴别器(D)组成。从低分辨率到高分辨率的图像是从树的不同分支生成的。在每个分支上,生成器捕获该尺度的图像分布,鉴别器分辨来自该尺度样本的真假。对生成器进行联合训练以逼近多个分布,并且以交替方式对生成器和鉴别器进行训练。
- 单级生成网络。抛弃了堆叠结构,只使用一个生成器、一个鉴别器、一个预训练过的文本编码器。使用一系列包含仿射变换的UPBlock块学习文本与图像之间的映射关系,由文本生成图像特征。
二、三种框架的对比
2.1、图像质量
在生成图像的质量上:扩散模型最好,自回归模型和生成对抗网络其次:
| 模型名 | 模型类型 | FID分数 |
|---|---|---|
| KNN-Diffusion | 扩散模型 | 16.66 |
| Stable Diffusion | 扩散模型 | 12.63 |
| GLIDE | 扩散模型 | 12.24 |
| DALL-E 2 | 扩散模型 | 10.39 |
| Imagen | 扩散模型 | 7.27 |
| Re-Imagen | 扩散模型 | 6.88 |
| DALL-E | 自回归模型 | 28 |
| CogView | 自回归模型 | 27.1 |
| CogView2 | 自回归模型 | 24.0 |
| Parti | 自回归模型 | 7.23 |
| StackGAN++ | 生成对抗网络 | 81.59 |
| AttnGAN | 生成对抗网络 | 35.49 |
| DM-GAN | 生成对抗网络 | 32.64 |
| DF-GAN | 生成对抗网络 | 21.42 |
| SSA-GAN | 生成对抗网络 | 19.37 |
2.2、参数量
在参数量的比较上,自回归模型和扩散模型参数量达到了十亿级别,属于自回归模型的Parti甚至达到了百亿级别的参数量,而生成对抗网络的模型参数量一般在千万级别,明显轻巧便捷。
| 模型名 | 模型类型 | 参数量(大概) |
|---|---|---|
| GLIDE | 扩散模型 | 35亿 |
| DALLE-2 | 扩散模型 | 35亿 |
| Imagen | 扩散模型 | 34亿 |
| Re-Imagen | 扩散模型 | 36亿 |
| DALLE | 自回归模型 | 120亿 |
| Cogview | 自回归模型 | 40亿 |
| Cogview2 | 自回归模型 | 60亿 |
| Parti | 自回归模型 | 200亿 |
| DFGAN | 生成对抗网络 | 0.19亿 |
2.3、易扩展性
在易扩展度的比较上,由于训练的计算成本小,且开源模型较多,生成对抗网络在文本生成图像的任务上仍然有很大的优势。而扩散模型和自回归模型的开源量较少,目前大多数都是大型公司(谷歌、Meta等)在研究,大型通用模型对设备的要求较高,在单张A100 GPU下,DALL-E需要18万小时,拥有200亿参数的 Parti 更是需要超过100万小时,成本高昂。
个人总结来说:
| 扩散模型 | 自回归模型 | 生成对抗网络 | |
|---|---|---|---|
| 图像质量 | 优 | 良+ | 良 |
| 参数量 | 中 | 差 | 优 |
| 易扩展性 | 中 | 中 | 优 |
| 优势原因 | 逐渐添加/去除噪声的性质,只学习大规模的结构,不引入归纳偏差 | 更大的batch size、更多的隐藏层、Transformer的多头自注意力机制 | 生成器和判别器动态对抗的特点,避免了马尔科夫链式的学习机制,无需在学习过程中进行推断 |
| 优点 | 更好的可解释性,生成的质量高 | 生成质量较高,生成分布更加均匀 | 采样速度很快,灵活的设计框架 |
| 缺点 | 大量扩散步骤导致采样速度慢 | 需要将图像转为token进行自回归预测,采样速度慢 | 可解释性差,容易模式崩溃 |
三、生成性网络的三难困境
目前的生成式学习框架还不能同时满足三个关键要求,包括(i)高质量样本,(ii)模式覆盖和样本多样性,(iii)快速和低廉的计算成本。而这些要求往往是它们在现实问题中广泛采用所必需的,普遍来说:
- 扩散模型(Diffusion Model)可以生成质量比较高的图片,且具有较强的多样性,但是其应用在实践中非常昂贵;(满足i,ii,难以满足iii)
- 自回归模型(Autoregressive Model)可以达到较好的模式覆盖和样本多样性,但是其先验的学习使用的是文本到中间离散表征的映射导致其很难在低廉的计算成本下生成高质量样本,它们生成的输出模糊。往往产生不现实的、模糊的样本(满足i,但是难以同时满足ii,iii)
- 生成对抗网络(GANs)能够快速生成高质量样本,但模式覆盖率较差;(满足i,iii,但难以满足ii)
参考:
《TACKLING THE GENERATIVE LEARNING TRILEMMA WITH DENOISING DIFFUSION GANS》
《Retrieval-Augmented Multimodal Language Modeling》
https://blog.csdn.net/qq_32275289/article/details/126951463
https://blog.csdn.net/c9Yv2cf9I06K2A9E/article/details/124641910
💡 最后
我们已经建立了🏤T2I研学社群,如果你还有其他疑问或者对🎓文本生成图像很感兴趣,可以私信我加入社群。
📝 加入社群 抱团学习:中杯可乐多加冰-采苓AI研习社
🔥 限时免费订阅:文本生成图像T2I专栏
🎉 支持我:点赞👍+收藏⭐️+留言📝