一、简介
1. 分片集群简介
-
1.分片原因
分片集群是为了解决单节点存在的CPU和存储,IO的瓶颈问题,将原来存储在单个mongo实例中的数据,按照一定的规则分散存储在多个mongo实例中,每个mongo中只存储一部分数据,对数据进行读写时仅需要访问存储这条数据的mongo分片节点即可。
-
2.分片优势
-
分片性能有极大提升,且方便扩展
-
集群对客户端透明,客户端不需要知道分片信息,客户端不需要额外的配置
-
每个分片都可以使用副本集群保障分片的高可用,从而可以保障整个分片集群高可用
-
-
3.分片劣势
分片集群架构与单实例和副本集群相比复杂很多,运维成本要高一些
2. 分片集群角色
-
1.config server
配置节点,存储集群的配置信息,分片数据的路由信息等,为保障高可用,默认最少需要三个config server节点的副本集群
-
2.mongos
路由节点,提供对外访问接口,所有客户端的请求通过mongos路由到具体的数据节点,mongos节点不存储任何信息,通过config server获取分片信息。一般有多个mongos节点,但不需要配置为集群,可以和客户端部署在同一个节点上,每个客户端部署一个mongos
-
3.mongod
mongod即数据存储的节点,一般有多个mongod节点,存储不同的分片数据。可以将一个副本集群作为一个分片节点,保障分片的高可用
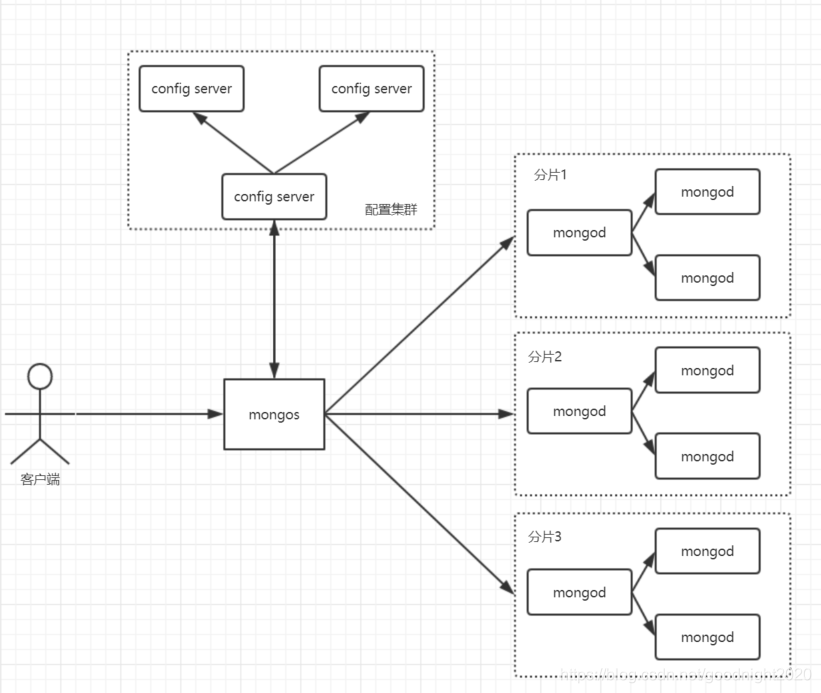
3. 分片集群架构
-
1.集群架构
-
客户端通过mongos读写数据
-
mongos通过config server获取分片信息
-
mongos找到对应的分片插入或读取数据
-
每一个分片可以是单个mongo实例也可以是一个副本集群,下图画的都是副本集群
-
-
2.分片存储
-
chunks:
chunk是数据存储单元,mongod存储数据时把多条数据存储到同一个chunk,当一个chunk大于配置中的chunk size时,会把该chunk切分成更小的chunk, -
balancer
balancer是一个后台进程,复制chunk迁移,从而均衡各个mongod的负载。
-
-
3.chunk大小
chunk size默认64M,可以调整配置中的chunk size- chunk size越小,chunk的分裂次数越多,数据分布越均匀。反之,chunk的分裂和迁移会少,但可能导致数据不均匀
- chunk自动分裂只会在数据写入时发生,如果chunk size调小,不会立即触发chunk的分裂和迁移,需要一定时间达到指定的大小
- chunk只会分裂,不会合并,也就是说即使将chunk size调大,现有的chunk数量也不会变少
4. 分片键
-
1.分片键介绍
-
mongo数据的分布是以分片键为拆分的依据,因此分片键至关重要。
-
mongo的分片使用基于范围的或是基于哈希的
-
-
2.分片键特点
- 分片键确定后不可改变
- 分片键必须有索引
- 分片键最大为512bytes
- 无法在设置了分片的collection上插入无分片键的文档
- 如果查询条件中没有包含分片键,那么查询性能会很糟糕
-
3.基于范围的分片
按照分片键的范围把数据分为不同部分,相似或连续的分片键很可能存储在同一个数据块中。
基于范围的分片键查询时mongos可以很高效的知道查询的数据在哪一个数据块中,但范围分片也可能会导致数据分布不均匀,或是热点数据集中在个别数据块中的现象。比如对于自增的字段作为分片键,新写入的数据都会集中在最后一个数据块中。
-
4.基于哈希的分片
基于哈希的分片,mongo对分片键计算一个哈希值,并用这个哈希值确定数据分布在哪个数据块,因此数据的分布更均匀,相似的分片键并不会被写入到相同的数据块中。
哈希分片解决了范围分片的问题,但由于数据太过分散,当执行范围查询时可能需要后端的所有节点都执行查询操作然后进行合并排序后才能得到结果
-
5.分片键的选择
-
单调升序的分片键(递增)
相似或连续数据集中,范围查询可以快速定位数据块,但可能导致数据分布不均,最后一个数据块是写热点
-
随机分片键
比如md5,哈希值等,数据分布均匀,IO分布均匀,但会产生大量的随机IO,磁盘负担大
-
混合分片键
组合升序分片键和随机分片键,设置合理的分片算法,使数据大范围上集中,但又不会因为太集中而产生局部热点,比如按照月份范围分片,和一个md5值哈希分片,同一个月份的数据集中在一个“大局部”,而md5可以使数据在“大局部”中的均匀分布,不至于产生“小局部”热点。
-
使用常用的查询相关的字段作为分片键,并且能包含唯一字段
-
二、分片集群搭建与测试
1. 环境介绍
我们就按照上面架构图中的架构搭建一个全高可用的分片集群
这里是在一台机器上启动了多个mongo实例,实际生产环境中需要分开
-
配置节点副本集群
副本集名称 角色 端口 数据文件路径 config config server 20001 /data/mongo/20001/ config config server 20002 /data/mongo/20002/ config config server 20003 /data/mongo/20003/ -
第一个分片的副本集群
副本集名称 角色 端口 数据文件路径 shard1 mongod 30001 /data/mongo/30001/ shard1 mongod 30002 /data/mongo/30002/ shard1 mongod 30003 /data/mongo/30003/ -
第二个分片的副本集群
副本集名称 角色 端口 数据文件路径 shard2 mongod 40001 /data/mongo/40001/ shard2 mongod 40002 /data/mongo/40002/ shard2 mongod 40003 /data/mongo/40003/ -
第三个分片的副本集群
副本集名称 角色 端口 数据文件路径 shard3 mongod 50001 /data/mongo/50001/ shard3 mongod 50002 /data/mongo/50002/ shard3 mongod 50003 /data/mongo/50003/ -
路由节点
路由节点不需要副本集,单节点即可
角色 端口 数据文件路径 mongos 60001 /data/mongo/60001/
2. 搭建配置节点的副本集群
-
1.创建mongo用户
useradd mongo echo "mongo" | passwd --stdin mongo -
2.解压mongo二进制文件
tar -xzvf mongodb-linux-x86_64-rhel70-4.2.3.tgz -C /usr/local/ cd /usr/local/ mv mongodb-linux-x86_64-rhel70-4.2.3 mongodb chown mongo:mongo mongodb/ -R -
3.修改环境变量
- 若允许所有用户都可以使用mongo命令则在
/etc/profile中加入如下行,然后执行source /etc/profile生效 - 若仅允许mongo用户使用mongo则切换到mongo用户,在mongo用户家目录中的
.bash_profile文件中加入如下行,然后source ~/.bash_profile生效
export PATH=/usr/local/mongodb/bin:$PATH - 若允许所有用户都可以使用mongo命令则在
-
4.创建所需的数据目录
mkdir -p /data/mongo/2000{1,2,3}/{data,log} chown mongo:mongo -R /data/mongo创建完成后目录如下:
/data/mongo/20001 ├── data └── log /data/mongo/20002 ├── data └── log /data/mongo/20003 ├── data └── log -
5.在20001,20002,20003三个目录下新建
mongo.conf配置文件,文件内容如下,每个实例修改端口和路径配置# /data/mongo/20001/mongo.conf dbpath=/data/mongo/20001/data logpath=/data/mongo/20001/log/mongo.log fork=true port=20001 replSet=config #副本集的名称,三个节点一致 configsvr=true #表示这是个配置节点 # /data/mongo/20002/mongo.conf dbpath=/data/mongo/20002/data logpath=/data/mongo/20002/log/mongo.log fork=true port=20002 replSet=config configsvr=true # /data/mongo/20003/mongo.conf dbpath=/data/mongo/20003/data logpath=/data/mongo/20003/log/mongo.log fork=true port=20003 replSet=config configsvr=true -
6.启动三个实例
# 切换到mongo用户 su - mongo # 启动三个实例 mongod -f /data/mongo/20001/mongo.conf mongod -f /data/mongo/20002/mongo.conf mongod -f /data/mongo/20003/mongo.conf -
7.检查
分别执行连接这三个端口看能否正常连接
mongo --port 20001 mongo --port 20002 mongo --port 20003 -
8.初始化这个副本集群
登录任意一个实例
mongo --port 20001初始化集群
rs.initiate()加入另外两个节点
rs.add("localhost:20002") rs.add("localhost:20003")查看集群状态是否正常
rs.status()
3. 搭建第一个分片的副本集群
步骤和上面的配置节点集群相同,因为我们是搭建在同一台机器上,所以直接从第四步开始
-
1.创建所需的数据目录
mkdir -p /data/mongo/3000{1,2,3}/{data,log} chown mongo:mongo -R /data/mongo创建完成后目录如下:
/data/mongo/30001 ├── data └── log /data/mongo/30002 ├── data └── log /data/mongo/30003 ├── data └── log -
2.在30001,30002,30003三个目录下新建
mongo.conf配置文件,文件内容如下,每个实例修改端口和路径配置# /data/mongo/30001/mongo.conf dbpath=/data/mongo/30001/data logpath=/data/mongo/30001/log/mongo.log fork=true port=30001 replSet=shard1 #副本集的名称,三个节点一致 shardsvr=true #表示这是个分片节点 # /data/mongo/30002/mongo.conf dbpath=/data/mongo/30002/data logpath=/data/mongo/30002/log/mongo.log fork=true port=30002 replSet=shard1 shardsvr=true # /data/mongo/30003/mongo.conf dbpath=/data/mongo/30003/data logpath=/data/mongo/30003/log/mongo.log fork=true port=30003 replSet=shard1 shardsvr=true -
3.启动三个实例
# 切换到mongo用户 su - mongo # 启动三个实例 mongod -f /data/mongo/30001/mongo.conf mongod -f /data/mongo/30002/mongo.conf mongod -f /data/mongo/30003/mongo.conf -
4.检查
分别执行连接这三个端口看能否正常连接
mongo --port 30001 mongo --port 30002 mongo --port 30003 -
5.初始化这个副本集群
登录任意一个实例
mongo --port 30001初始化集群
rs.initiate()加入另外两个节点
rs.add("localhost:30002") rs.add("localhost:30003")查看集群状态是否正常
rs.status()
4. 搭建第二个分片的副本集群
步骤和上一个分片的副本集群完全一样,只需要修改端口和副本集名称即可
-
1.创建所需的数据目录
mkdir -p /data/mongo/4000{1,2,3}/{data,log} chown mongo:mongo -R /data/mongo创建完成后目录如下:
/data/mongo/40001 ├── data └── log /data/mongo/40002 ├── data └── log /data/mongo/40003 ├── data └── log -
2.在40001,40002,40003三个目录下新建
mongo.conf配置文件,文件内容如下,每个实例修改端口和路径配置# /data/mongo/40001/mongo.conf dbpath=/data/mongo/40001/data logpath=/data/mongo/40001/log/mongo.log fork=true port=40001 replSet=shard2 #副本集的名称,三个节点一致 shardsvr=true #表示这是个分片节点 # /data/mongo/40002/mongo.conf dbpath=/data/mongo/40002/data logpath=/data/mongo/40002/log/mongo.log fork=true port=40002 replSet=shard2 shardsvr=true # /data/mongo/40003/mongo.conf dbpath=/data/mongo/40003/data logpath=/data/mongo/40003/log/mongo.log fork=true port=40003 replSet=shard2 shardsvr=true -
3.启动三个实例
# 切换到mongo用户 su - mongo # 启动三个实例 mongod -f /data/mongo/40001/mongo.conf mongod -f /data/mongo/40002/mongo.conf mongod -f /data/mongo/40003/mongo.conf -
4.检查
分别执行连接这三个端口看能否正常连接
mongo --port 40001 mongo --port 40002 mongo --port 40003 -
5.初始化这个副本集群
登录任意一个实例
mongo --port 40001初始化集群
rs.initiate()加入另外两个节点
rs.add("localhost:40002") rs.add("localhost:40003")查看集群状态是否正常
rs.status()
5. 搭建第三个分片的副本集群
步骤和上一个分片的副本集群完全一样,只需要修改端口和副本集名称即可
-
1.创建所需的数据目录
mkdir -p /data/mongo/5000{1,2,3}/{data,log} chown mongo:mongo -R /data/mongo创建完成后目录如下:
/data/mongo/50001 ├── data └── log /data/mongo/50002 ├── data └── log /data/mongo/50003 ├── data └── log -
2.在50001,50002,50003三个目录下新建
mongo.conf配置文件,文件内容如下,每个实例修改端口和路径配置# /data/mongo/50001/mongo.conf dbpath=/data/mongo/50001/data logpath=/data/mongo/50001/log/mongo.log fork=true port=50001 replSet=shard3 #副本集的名称,三个节点一致 shardsvr=true #表示这是个分片节点 # /data/mongo/50002/mongo.conf dbpath=/data/mongo/50002/data logpath=/data/mongo/50002/log/mongo.log fork=true port=50002 replSet=shard3 shardsvr=true # /data/mongo/50003/mongo.conf dbpath=/data/mongo/50003/data logpath=/data/mongo/50003/log/mongo.log fork=true port=50003 replSet=shard3 shardsvr=true -
3.启动三个实例
# 切换到mongo用户 su - mongo # 启动三个实例 mongod -f /data/mongo/50001/mongo.conf mongod -f /data/mongo/50002/mongo.conf mongod -f /data/mongo/50003/mongo.conf -
4.检查
分别执行连接这三个端口看能否正常连接
mongo --port 50001 mongo --port 50002 mongo --port 50003 -
5.初始化这个副本集群
登录任意一个实例
mongo --port 50001初始化集群
rs.initiate()加入另外两个节点
rs.add("localhost:50002") rs.add("localhost:50003")查看集群状态是否正常
rs.status()
6. 搭建路由节点
路由节点不存储任何数据,不需要集群,一般可以和客户端部署在一起,一个客户端部署一个路由节点。
我们这里就部署一个路由节点
-
1.创建所需的数据目录
mkdir -p /data/mongo/60001/{data,log} chown mongo:mongo -R /data/mongo创建完成后目录如下:
/data/mongo/60001 ├── data └── log -
2.在60001目录下新建
mongo.conf配置文件,文件内容如下路由节点不存储数据,因此配置文件中不能设置dbpath参数,否则会报错
# /data/mongo/60001/mongo.conf logpath=/data/mongo/60001/log/mongo.log fork=true port=60001 configdb=config/localhost:20001,localhost:20002,localhost:20003 # 指定配置服务器的副本集名称和地址端口 -
3.使用mongos命令启动路由节点
mongos -f /data/mongo/60001/mongo.conf
7.配置分片
-
在路由节点加入分片
登录路由节点
mongo --port 60001加入三个分片
sh.addShard("shard1/localhost:30001,localhost:30002,localhost:30003") sh.addShard("shard2/localhost:40001,localhost:40002,localhost:40003") sh.addShard("shard3/localhost:50001,localhost:50002,localhost:50003")对
testdb数据库的testcol集合启用分片,分片键为testkey# 在testdb库启用分片 sh.enableSharding("testdb") # 使用范围分片 sh.shardCollection("testdb.testcol",{"testkey":1}) # 使用哈希分片 sh.shardCollection("testdb.testcol",{"testkey":"hashed"})查看分片集群状态
sh.status()[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oAji2klV-1600328284507)(C:/Users/suzhao/Desktop/a/2.png)]
8.测试
测试前把chunk size 调成1M,便于观察(生产环境不要调太小,一般默认的64M就可以)
mongos> use config
mongos> db.settings.save({_id:"chunksize",value:1})
-
范围分片测试
对
testdb数据库的testcol集合启用分片,分片键为testkey,testkey是一个自增字段,使用范围分片配置分片前需要先创建索引
# 在testdb库启动分片 mongos> sh.enableSharding("testdb") # 使用范围分片 mongos> sh.shardCollection("testdb.testcol",{"testkey":1})插入数据测试(数据可以插入更多一点观察效果)
mongos> use testdb mongos> for(i=0;i<20000;i++){ db.testcol.insert({"testkey":i,"value":"hello world","date":new Date()})}查看状态统计
mongos> sh.status()可以看出现在有五个分片
min-1 :在shard2集群中
1-13797:在shard1集群中
13797-max:在shard3集群中
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-j6uGziMV-1600328284512)(C:/Users/suzhao/Desktop/a/3.png)]
注意
此时用
db.testcol.count()统计的数据可能会超过20000# mongos统计数据超过20000 mongos> db.testcol.count() 33797 # 在shard1上执行有13796条 shard1:PRIMARY> db.testcol.find().count() 13796 # 在shard2上执行有1条 shard2:PRIMARY> db.testcol.count() # 在shard3上执行有20000条 shard3:PRIMARY> db.testcol.find().count() 20000可以看到shard1和shard2上都是正确的,但shard3上有全量的数据了,这是因为shard3分片是主分片,chunk迁移完成前,统计count会重复统计,但不用担心,从mongos查询数据时并不会返回重复数据
# 在mongos带条件查询时不会有重复数据 mongos> db.testcol.find({testkey:{$gte:0}}).count() 20000因此在分片集群中使用
count()查询可能是不准确的可以使用聚合的方式获取到准确的记录数
mongos> db.testcol.aggregate( [ {$group:{_id: null,count:{$sum:1}}} ] ) { "_id" : null, "count" : 20000 }过一会chunk迁移完成后,或者我们手动执行一次balance,过一会再看就正常了
如下:各分片加起来刚好等于20000
# mongos总数20000 mongos> db.testcol.count() 20000 # shard1分片的记录数 shard1:PRIMARY> db.testcol.count() 13796 # shard2分片的记录数 shard2:PRIMARY> db.testcol.count() 1 # shard3分片的记录数 shard3:PRIMARY> db.testcol.count() 6203
-
哈希分片测试
还是用刚才的数据库和集合,分片键依然使用testkey,只是把分片模式改为哈希
mongos> use testdb # 先删除这个集合清空数据和索引 mongos> db.testcol.drop() # 在testdb库启动分片 mongos> sh.enableSharding("testdb") # 使用范围分片 mongos> sh.shardCollection("testdb.testcol",{"testkey":"hashed"})插入测试数据
mongos> use testdb mongos> for(i=0;i<20000;i++){ db.testcol.insert({"testkey":i,"value":"hello world","date":new Date()})}查看统计状态
mongos> sh.status()[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-INyIerbc-1600328284515)(C:/Users/suzhao/Desktop/a/4.png)]
此时我们在统计下各个分片的数据
# mongos mongos> db.testcol.count() 20000 # shard1分片 shard1:PRIMARY> db.testcol.count() 6817 # shard2分片 shard2:PRIMARY> db.testcol.count() 6708 # shard3分片 shard3:PRIMARY> db.testcol.count() 6475通过以上测试也可以看出:
范围分片会有数据热点,数据都集中写在最后一个chunk中,所以刚写完后count统计数据会有重复(chunk 还没有完成迁移),且数据分布不够均匀
哈希分片可以避免数据热点(刚写完就count统计,没有重复数据,没有chunk在迁移),且数据分布更均匀,各个分片都差不多
-
混合分片测试
混合分片只能用两个范围分片键,不能范围分片模式和哈希分片模式混用
sh.shardCollection("testdb.testcol",{"key1":1,"key2":1}) # 正确 sh.shardCollection("testdb.testcol",{"key1":1,"key2":"hashed"}) #错误 sh.shardCollection("testdb.testcol",{"key1":"hashed","key2":"hashed"}) #错误为避免范围分片热点集中,哈希分片太过分散磁盘随机IO太多问题,可使用混合分片,第一个分片使用递增值,第二个分片使用一个比较离散的值,比如用户密码的md5加密字符串
创建分片
mongos> use testdb # 先删除这个集合清空数据和索引 mongos> db.testcol.drop() # 在testdb库启动分片 mongos> sh.enableSharding("testdb") # 使用联合分片 mongos> sh.shardCollection("testdb.testcol",{"key":1,"password":1})插入测试数据
这里使用一个python脚本插入数据
生成数据格式
{"_id": 自增 , "key" : 自增 , "password" : key的md5值 }#!/usr/bin/python import pymongo import hashlib mongo_str="mongodb://localhost:60001/" myclient=pymongo.MongoClient(mongo_str) mydb=myclient["testdb"] mycol=mydb["testcol"] mycol.delete_many({}) if __name__ == '__main__': key=0 while key<20000: md5=hashlib.md5(str(key)).hexdigest() mydict={"_id":key,"key":key,"password":md5,"value":"hello ,this is mix key"} x=mycol.insert_one(mydict) print(x.inserted_id) key+=1查看状态
rs.status()[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hVgiMmSR-1600328284518)(C:/Users/suzhao/Desktop/a/5.png)]
9. 集群操作
-
查看所有开启分片的数据库
use config db.databases.find() -
查看分片的片键
use config db.collections.find() -
查看分片的详细信息
db.printShardingStatus() sh.status -
删除分片
db.runCommand( { removeShard: "shard2" } )如果要删除的分片是主分片则需要先移动主分片,对于没有分片的库,则只有一个主分片,先移走在删除
db.runCommand({movePrimary:"testdb",to:"shard1"})可以多次运行删除分片命令查看状态。
-
添加刚才删除的分片
sh.addShard("shard2/localhost:40001,localhost:40002,localhost:40003")删除的分片想要添加回来,需要把原有的数据删除,否则会报如下错误,已经有
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GwDA0IDN-1600328284522)(C:/Users/suzhao/Desktop/a/6.png)]
# 登录刚才删除的mongo分片 mongo --port 40001 # 删除数据 shard2:PRIMARY> use testdb switched to db testdb shard2:PRIMARY> db.dropDatabase() # 在mongos上重新添加添加后数据会自动平衡
# 可以看到已经有数据迁移过来了 shard2:PRIMARY> db.testcol.count() 10082 shard2:PRIMARY>
10.balance操作
-
查看是否开启balance
mongos> sh.getBalancerState() true -
查看是否正在运行balance
mongos> sh.isBalancerRunning() false -
查看balance窗口
可以指定一个空闲时间执行balance操作,null表示没有设置窗口,任何时间都可以
mongos> sh.getBalancerWindow() null -
手动启停balance
sh.startBalancer() sh.stopBalancer() -
设置balance窗口
设置每晚2点到6点可以balance
use config db.settings.update({_id:"balancer"},{$set:{activeWindow:{start:"02:00",stop:"06:00"}}},{$upsert:true}) -
删除balance窗口
use config db.settings.update({_id:"balancer"},{$unset:{activeWindow:true}}) -
关闭或打开某个集合的balance
sh.disableBalancing("testdb.testcol") sh.enableBalancing("testdb.testcol") -
查看集合是否开启balance
db.collections.find({_id:"testdb.testcol"})