Paxos:
Paxos算法是一种基于消息传递且具有高度容错特性的一致性算法。用于解决在多个节点间确定一个值。Paxos算法实现多个节点间达成共识的过程分为两个阶段:准备阶段、接受阶段
准备阶段:
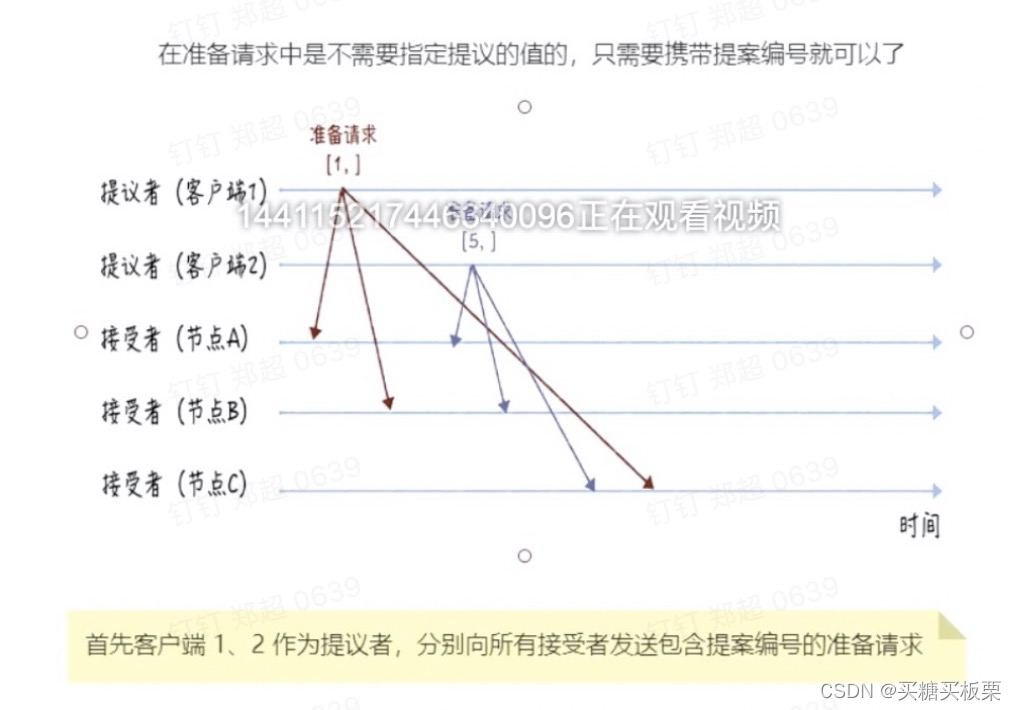


Acceptor的响应规则总结:
- 如果Acceptor之前没有响应任何提案,返回一个尚无提案的响应;如果准备请求的提案编号,小于等于Acceptor已经响应过的准备请求的提案编号,那么将承诺不响应这个准备请求
- 如果接受请求的提案编号,小于Acceptor已经响应的准备请求的提案编号,那么将承诺不通过这个提案
- 如果Acceptor之前有通过提案,那么Acceptor将承诺,会在准备请求的响应中,包含已经通过的最大编号的提案信息。
接受阶段:


客户端发送”接受请求”的条件:
client获得大多数(超过半数)节点的准备阶段的响应(只要有响应即可,无论这个响应是否是”尚无提案”的响应)
发送的提案的值,如果尚无提案,就是自身的提案值,如果有过提案,提案值是准备阶段的响应返回的最大提案编号的值。
存在问题:
客户端在获得大多数的准备阶段的响应后,才发送”接受请求”,存在这样一种情况:有5个节点,3个客户端,3个客户端收到的响应分别为1, 2, 2个,这样每个客户端都无法在发送”接受请求”。这是只能多次执行Basic Paxos实例,来实现一系列值的共识。但是客户端和接受者之间通讯是一个rpc远程调用,多次的执行Basic Paxos实例,就会导致往返消息多、耗性能、延迟大,延迟一直是分布式的痛点,是需要我们在开发分布式系统中认真考虑的。
Raft:
根据 Raft 协议,一个应用 Raft 协议的集群在刚启动时,所有节点的状态都是 Follower。由于没有 Leader,Followers 无法与 Leader 保持心跳(Heart Beat),因此,Followers 会认为 Leader 已经下线,进而转为 Candidate 状态。然后,Candidate 将向集群中其它节点请求投票,同意自己升级为 Leader。如果 Candidate 收到超过半数节点的投票(N/2 + 1),它将获胜成为 Leader。
第一阶段:所有节点都是 Follower。
上面提到,一个应用 Raft 协议的集群在刚启动(或 Leader 宕机)时,所有节点的状态都是 Follower,初始 Term(任期)为 0。同时启动选举定时器,每个节点的选举定时器超时时间都在 100~500 毫秒之间且并不一致(避免同时发起选举)。
所有节点都是 Follower
第二阶段:Follower 转为 Candidate 并发起投票。
没有 Leader,Followers 无法与 Leader 保持心跳(Heart Beat),节点启动后在一个选举定时器周期内未收到心跳和投票请求,则状态转为候选者 Candidate 状态,且 Term 自增,并向集群中所有节点发送投票请求并且重置选举定时器。
注意,由于每个节点的选举定时器超时时间都在 100-500 毫秒之间,且彼此不一样,以避免所有 Follower 同时转为 Candidate 并同时发起投票请求。换言之,最先转为 Candidate 并发起投票请求的节点将具有成为 Leader 的“先发优势”。
Follower 转为 Candidate 并发起投票
第三阶段:投票策略。
节点收到投票请求后会根据以下情况决定是否接受投票请求(每个 follower 刚成为 Candidate 的时候会将票投给自己):
请求节点的 Term 大于自己的 Term,且自己尚未投票给其它节点,则接受请求,把票投给它;
请求节点的 Term 小于自己的 Term,且自己尚未投票,则拒绝请求,将票投给自己。
投票策略
第四阶段:Candidate 转为 Leader。
一轮选举过后,正常情况下,会有一个 Candidate 收到超过半数节点(N/2 + 1)的投票,它将胜出并升级为 Leader。然后定时发送心跳给其它的节点,其它节点会转为 Follower 并与 Leader 保持同步,到此,本轮选举结束。
注意:有可能一轮选举中,没有 Candidate 收到超过半数节点投票,那么将进行下一轮选举。
Candidate 转为 Leader