一、线性回归
1,线性关系模型
一个通过属性的线性组合来进行预测的函数:
f(x)=w1x1+w2x2+w3x3+…..+w(n)x(n)+b
其中w为权重,b称为偏置项,可以理解为:w0 X 1
2,线性回归
定义:线性回归通过一个或者多个自变量与因变量之间进行建模的回归分析,其中可以为一个或者多个自变量之间的线性组合(线性回归的一种)
一元线性回归:涉及到的变量只有一个
多元线性回归:涉及到的变量两个或两个以上

3,损失函数(误差大小)

4,最小二乘法之梯度下降

理解:沿着这个函数下降的方向找,最后就能找到山谷的最低点 ,然后更新W值。
使用:面对训练数据规模十分庞大的任务
5,sklearn线性回归正规方程、梯度下降API
- sklearn.linear_model.LinearRegression(正规方程)
- sklearn.linear_model.SGDRegressor(梯度下降)

from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression,SGDRegressor
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
def mylinear():
"""
线性回归直接预测房子价格
:return:
"""
# 读取数据
lb=load_boston()
#分割数据集到训练集和测试集
x_train,x_test,y_train,y_test=train_test_split(lb.data,lb.target,test_size=0.25)
print(y_train,y_test)
#进行标准化处理(?) 目标值处理?
#特征值和目标值是都必须进行标准化处理,实例化两个标准化API
std_x=StandardScaler()
x_train=std_x.fit_transform(x_train.reshape(-1,1))
x_test=std_x.transform(x_test)
#目标值
std_y=StandardScaler()
y_train=std_y.fit_transform(y_train.reshape(-1,1))
y_test=std_y.transform(y_test)
#estimator预测
#正规方程求解预测结果
lr=LinearRegression()
lr.fit(x_train,y_train)
print(lr.coef_)
#预测测试集的房子价格
y_predict=std_y.inverse_transform(lr.predict(x_test))
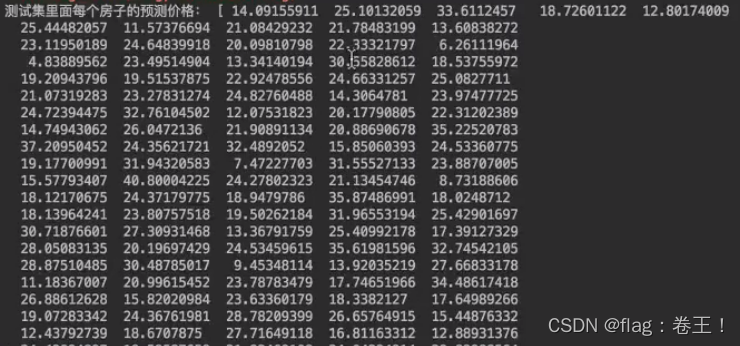
print("测试集里面每个房子的预测价格:",y_predict)
return None
if __name__=="__main__":
mylinear() 结果:
回归性能评估:

mean_squared_error:

注意:真实值,预测值为标准化之前的值
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression,SGDRegressor
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
def mylinear():
"""
线性回归直接预测房子价格
:return:
"""
# 读取数据
lb=load_boston()
#分割数据集到训练集和测试集
x_train,x_test,y_train,y_test=train_test_split(lb.data,lb.target,test_size=0.25)
print(y_train,y_test)
#进行标准化处理(?) 目标值处理?
#特征值和目标值是都必须进行标准化处理,实例化两个标准化API
std_x=StandardScaler()
x_train=std_x.fit_transform(x_train.reshape(-1,1))
x_test=std_x.transform(x_test)
#目标值
std_y=StandardScaler()
y_train=std_y.fit_transform(y_train.reshape(-1,1))
y_test=std_y.transform(y_test)
# estimator预测
# 正规方程求解预测结果
lr = LinearRegression()
lr.fit(x_train, y_train)
print(lr.coef_)
# 预测测试集的房子价格
y_lr_predict = std_y.inverse_transform(lr.predict(x_test))
print("测试集里面每个房子的预测价格:", y_lr_predict)
print("正规方程的均方误差:",mean_squared_error(std_y.inverse_transform(y_test),y_lr_predict))
return None
if __name__=="__main__":
mylinear()
结果:

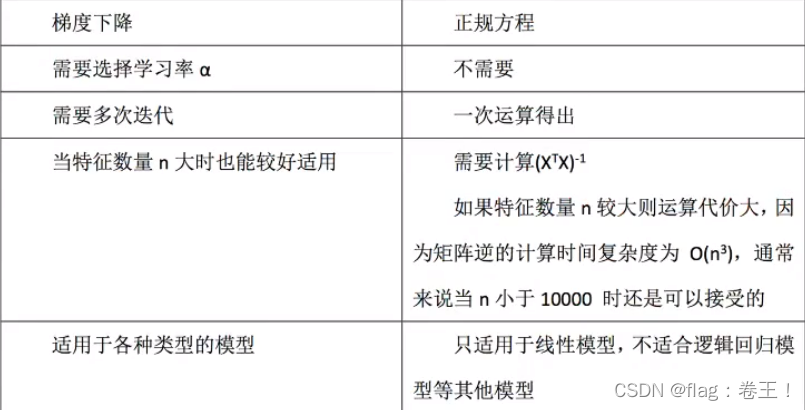
线性回归方程两种方法的对比:
二、过拟合和欠拟合

过拟合:一个假设在训练数据上能够获得比其他假设更好的拟合,但是在训练数据外的数据机上却不能很好的拟合数据,此时认为这个假设出现了过拟合的现象。(模型过于复杂)
欠拟合:一个假设在训练数据上不能获取更好的拟合,但是在训练数据外的数据集上也不能很好的拟合数据,此时认为这个假设出现了欠拟合的现象。(模型过于简单)
欠拟合的原因:学习到数据 的特征少
解决方法:增加数据的特征数量。
过拟合原因:原始特征过多,存在一些嘈杂的特征,模型过于复杂是因为模型尝试去兼顾各个测试数据点。
解决方法:
- 进行特征选择,消除关联性大的特征(很难做)
- 交叉验证(让所有数据都有过训练)
- 正则化(了解)
正则化:
作用:可以使得W的每个元素都很小,都接近于0
优点:越小参数说明模型越简单,越简单的模型越不容易产生过拟合现象
带有正则化的线性回归——Ridge:
sklearn.linear_model.Ridge
Ridge用法:

版权声明:本文为qq_60381063原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。