转自:https://www.cnblogs.com/study-everyday/p/6430462.html
前言
以前写过介绍HashMap的文章,文中提到过HashMap在put的时候,插入的元素超过了容量(由负载因子决定)的范围就会触发扩容操作,就是rehash,这个会重新将原数组的内容重新hash到新的扩容数组中,在多线程的环境下,存在同时其他的元素也在进行put操作,如果hash值相同,可能出现同时在同一数组下用链表表示,造成闭环,导致在get时会出现死循环,所以HashMap是线程不安全的。
我们来了解另一个键值存储集合HashTable,它是线程安全的,它在所有涉及到多线程操作的都加上了synchronized关键字来锁住整个table,这就意味着所有的线程都在竞争一把锁,在多线程的环境下,它是安全的,但是无疑是效率低下的。
其实HashTable有很多的优化空间,锁住整个table这么粗暴的方法可以变相的柔和点,比如在多线程的环境下,对不同的数据集进行操作时其实根本就不需要去竞争一个锁,因为他们不同hash值,不会因为rehash造成线程不安全,所以互不影响,这就是锁分离技术,将锁的粒度降低,利用多个锁来控制多个小的table,这就是这篇文章的主角ConcurrentHashMap JDK1.7版本的核心思想
ConcurrentHashMap
JDK1.7的实现
在JDK1.7版本中,ConcurrentHashMap的数据结构是由一个Segment数组和多个HashEntry组成,如下图所示:
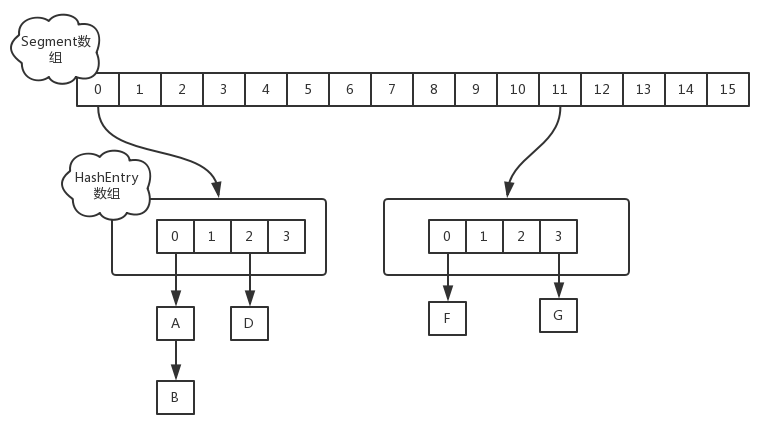
Segment数组的意义就是将一个大的table分割成多个小的table来进行加锁,也就是上面的提到的锁分离技术,而每一个Segment元素存储的是HashEntry数组+链表,这个和HashMap的数据存储结构一样
初始化
ConcurrentHashMap的初始化是会通过位与运算来初始化Segment的大小,用ssize来表示,如下所示
|
1 2 3 4 5 6 |
|
如上所示,因为ssize用位于运算来计算(ssize <<=1),所以Segment的大小取值都是以2的N次方,无关concurrencyLevel的取值,当然concurrencyLevel最大只能用16位的二进制来表示,即65536,换句话说,Segment的大小最多65536个,没有指定concurrencyLevel元素初始化,Segment的大小ssize默认为16
每一个Segment元素下的HashEntry的初始化也是按照位于运算来计算,用cap来表示,如下所示
|
1 2 3 |
|
如上所示,HashEntry大小的计算也是2的N次方(cap <<=1), cap的初始值为1,所以HashEntry最小的容量为2
put操作
对于ConcurrentHashMap的数据插入,这里要进行两次Hash去定位数据的存储位置
|
1 |
|
从上Segment的继承体系可以看出,Segment实现了ReentrantLock,也就带有锁的功能,当执行put操作时,会进行第一次key的hash来定位Segment的位置,如果该Segment还没有初始化,即通过CAS操作进行赋值,然后进行第二次hash操作,找到相应的HashEntry的位置,这里会利用继承过来的锁的特性,在将数据插入指定的HashEntry位置时(链表的尾端),会通过继承ReentrantLock的tryLock()方法尝试去获取锁,如果获取成功就直接插入相应的位置,如果已经有线程获取该Segment的锁,那当前线程会以自旋的方式去继续的调用tryLock()方法去获取锁,超过指定次数就挂起,等待唤醒
get操作
ConcurrentHashMap的get操作跟HashMap类似,只是ConcurrentHashMap第一次需要经过一次hash定位到Segment的位置,然后再hash定位到指定的HashEntry,遍历该HashEntry下的链表进行对比,成功就返回,不成功就返回null
size操作
计算ConcurrentHashMap的元素大小是一个有趣的问题,因为他是并发操作的,就是在你计算size的时候,他还在并发的插入数据,可能会导致你计算出来的size和你实际的size有相差(在你return size的时候,插入了多个数据),要解决这个问题,JDK1.7版本用两种方案
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
|
- 第一种方案他会使用不加锁的模式去尝试多次计算ConcurrentHashMap的size,最多三次,比较前后两次计算的结果,结果一致就认为当前没有元素加入,计算的结果是准确的
- 第二种方案是如果第一种方案不符合,他就会给每个Segment加上锁,然后计算ConcurrentHashMap的size返回
JDK1.8的实现
JDK1.8的实现已经摒弃了Segment的概念,而是直接用Node数组+链表+红黑树的数据结构来实现,并发控制使用Synchronized和CAS来操作,整个看起来就像是优化过且线程安全的HashMap,虽然在JDK1.8中还能看到Segment的数据结构,但是已经简化了属性,只是为了兼容旧版本

在深入JDK1.8的put和get实现之前要知道一些常量设计和数据结构,这些是构成ConcurrentHashMap实现结构的基础,下面看一下基本属性:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
|
基本属性定义了ConcurrentHashMap的一些边界以及操作时的一些控制,下面看一些内部的一些结构组成,这些是整个ConcurrentHashMap整个数据结构的核心
Node
Node是ConcurrentHashMap存储结构的基本单元,继承于HashMap中的Entry,用于存储数据,源代码如下
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
|
Node数据结构很简单,从上可知,就是一个链表,但是只允许对数据进行查找,不允许进行修改
TreeNode
TreeNode继承与Node,但是数据结构换成了二叉树结构,它是红黑树的数据的存储结构,用于红黑树中存储数据,当链表的节点数大于8时会转换成红黑树的结构,他就是通过TreeNode作为存储结构代替Node来转换成黑红树源代码如下
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
|
TreeBin
TreeBin从字面含义中可以理解为存储树形结构的容器,而树形结构就是指TreeNode,所以TreeBin就是封装TreeNode的容器,它提供转换黑红树的一些条件和锁的控制,部分源码结构如下
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
|
介绍了ConcurrentHashMap主要的属性与内部的数据结构,现在通过一个简单的例子以debug的视角看看ConcurrentHashMap的具体操作细节
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
我们先通过new ConcurrentHashMap()来进行初始化
|
1 2 |
|
由上你会发现ConcurrentHashMap的初始化其实是一个空实现,并没有做任何事,这里后面会讲到,这也是和其他的集合类有区别的地方,初始化操作并不是在构造函数实现的,而是在put操作中实现,当然ConcurrentHashMap还提供了其他的构造函数,有指定容量大小或者指定负载因子,跟HashMap一样,这里就不做介绍了
put操作
在上面的例子中我们新增个人信息会调用put方法,我们来看下
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
|
这个put的过程很清晰,对当前的table进行无条件自循环直到put成功,可以分成以下六步流程来概述
- 如果没有初始化就先调用initTable()方法来进行初始化过程
- 如果没有hash冲突就直接CAS插入
- 如果还在进行扩容操作就先进行扩容
- 如果存在hash冲突,就加锁来保证线程安全,这里有两种情况,一种是链表形式就直接遍历到尾端插入,一种是红黑树就按照红黑树结构插入,
- 最后一个如果该链表的数量大于阈值8,就要先转换成黑红树的结构,break再一次进入循环
- 如果添加成功就调用addCount()方法统计size,并且检查是否需要扩容
现在我们来对每一步的细节进行源码分析,在第一步中,符合条件会进行初始化操作,我们来看看initTable()方法
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
|
在第二步中没有hash冲突就直接调用Unsafe的方法CAS插入该元素,进入第三步如果容器正在扩容,则会调用helpTransfer()方法帮助扩容,现在我们跟进helpTransfer()方法看看
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
其实helpTransfer()方法的目的就是调用多个工作线程一起帮助进行扩容,这样的效率就会更高,而不是只有检查到要扩容的那个线程进行扩容操作,其他线程就要等待扩容操作完成才能工作
既然这里涉及到扩容的操作,我们也一起来看看扩容方法transfer()
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 |
|
其实helpTransfer()方法的目的就是调用多个工作线程一起帮助进行扩容,这样的效率就会更高,而不是只有检查到要扩容的那个线程进行扩容操作,其他线程就要等待扩容操作完成才能工作
既然这里涉及到扩容的操作,我们也一起来看看扩容方法transfer()
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 |
|
扩容过程有点复杂,这里主要涉及到多线程并发扩容,ForwardingNode的作用就是支持扩容操作,将已处理的节点和空节点置为ForwardingNode,并发处理时多个线程经过ForwardingNode就表示已经遍历了,就往后遍历,下图是多线程合作扩容的过程:
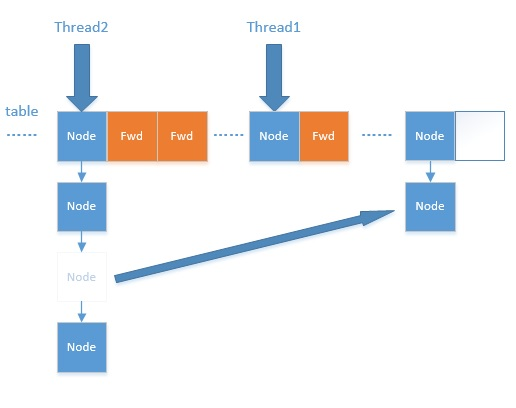
介绍完扩容过程,我们再次回到put流程,在第四步中是向链表或者红黑树里加节点,到第五步,会调用treeifyBin()方法进行链表转红黑树的过程
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
|
到第六步表示已经数据加入成功了,现在调用addCount()方法计算ConcurrentHashMap的size,在原来的基础上加一,现在来看看addCount()方法
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
|
put的流程现在已经分析完了,你可以从中发现,他在并发处理中使用的是乐观锁,当有冲突的时候才进行并发处理,而且流程步骤很清晰,但是细节设计的很复杂,毕竟多线程的场景也复杂
get操作
我们现在要回到开始的例子中,我们对个人信息进行了新增之后,我们要获取所新增的信息,使用String name = map.get(“name”)获取新增的name信息,现在我们依旧用debug的方式来分析下ConcurrentHashMap的获取方法get()
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
|
ConcurrentHashMap的get操作的流程很简单,也很清晰,可以分为三个步骤来描述
- 计算hash值,定位到该table索引位置,如果是首节点符合就返回
- 如果遇到扩容的时候,会调用标志正在扩容节点ForwardingNode的find方法,查找该节点,匹配就返回
- 以上都不符合的话,就往下遍历节点,匹配就返回,否则最后就返回null
size操作
最后我们来看下例子中最后获取size的方式int size = map.size();,现在让我们看下size()方法
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
在JDK1.8版本中,对于size的计算,在扩容和addCount()方法就已经有处理了,JDK1.7是在调用size()方法才去计算,其实在并发集合中去计算size是没有多大的意义的,因为size是实时在变的,只能计算某一刻的大小,但是某一刻太快了,人的感知是一个时间段,所以并不是很精确
总结与思考
其实可以看出JDK1.8版本的ConcurrentHashMap的数据结构已经接近HashMap,相对而言,ConcurrentHashMap只是增加了同步的操作来控制并发,从JDK1.7版本的ReentrantLock+Segment+HashEntry,到JDK1.8版本中synchronized+CAS+HashEntry+红黑树,相对而言,总结如下思考
- JDK1.8的实现降低锁的粒度,JDK1.7版本锁的粒度是基于Segment的,包含多个HashEntry,而JDK1.8锁的粒度就是HashEntry(首节点)
- JDK1.8版本的数据结构变得更加简单,使得操作也更加清晰流畅,因为已经使用synchronized来进行同步,所以不需要分段锁的概念,也就不需要Segment这种数据结构了,由于粒度的降低,实现的复杂度也增加了
- JDK1.8使用红黑树来优化链表,基于长度很长的链表的遍历是一个很漫长的过程,而红黑树的遍历效率是很快的,代替一定阈值的链表,这样形成一个最佳拍档
- JDK1.8为什么使用内置锁synchronized来代替重入锁ReentrantLock,我觉得有以下几点
- 因为粒度降低了,在相对而言的低粒度加锁方式,synchronized并不比ReentrantLock差,在粗粒度加锁中ReentrantLock可能通过Condition来控制各个低粒度的边界,更加的灵活,而在低粒度中,Condition的优势就没有了
- JVM的开发团队从来都没有放弃synchronized,而且基于JVM的synchronized优化空间更大,使用内嵌的关键字比使用API更加自然
- 在大量的数据操作下,对于JVM的内存压力,基于API的ReentrantLock会开销更多的内存,虽然不是瓶颈,但是也是一个选择依据