1. 集成学习
Bagging + Decision Tree -> Random Forest
AdaBoost + Decison Tree -> Boosting Decision Tree 提升树
Gradient Boosting + Decison -> Gradient Boosting Decision Tree GBDT梯度提升树
2. 提升树
1>分类问题
分类问题采用二叉分类树作为基分类器,采用指数函数作为损失函数。AdaBoost算法的损失函数也是指数函数,因此将其基分类器限定为二叉分类树,即为提升树算法。
2>回归问题
回归问题采用二叉回归树作为基分类器,采用均方误差作为损失函数:
式中T为当前决策树,f为当前模型,由上式可知,于是损失函数最小,则需使当前决策树逼近r,r称为残差。
具体流程如下:
a. 初始化基函数
b. 计算现有模型的残差:
i=1,2,…n
c. 通过残差拟合新模型,该过程实质为CART回归树的建造过程,该树以残差为回归目标。
d. 更新模型
e. 重复b~d直至m=M+1
f. 得到提升树模型
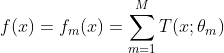
3.GBDT
GDBT是在提升树的基础上,利用最速下降法,用损失函数的负梯度作为残差的近似值,拟合新的模型。步骤如下:
a. 初始化基函数
b. 计算现有模型的负梯度,作为残差:
![]()
c. 通过残差拟合新模型。
d. 更新模型
e. 重复b~d直至m=M+1
f. 得到提升树模型
4. Xgboost
XgBoost(eXtreme Gradient Boosting)是GBDT的改进算法,在模型本身及其计算效率两方面进行了改进。
1> 模型损失函数中加入了L2正则项
![]()
![]()
上式中T为叶子节点数目。该正则化项能够限制基模型的复杂度。
2> 使用二阶倒数拟合残差
![]()
其中:
![]()
![]()
Xgboost在一定程度上可以实现并行化,训练速度快,可以处理稀疏数据,正则化策略较好的防止模型过拟合。
实现代码:
import sklearn
import numpy as np
from sklearn import datasets, model_selection, ensemble
from matplotlib import pyplot as plt
"""
基于梯度提升树的分类与回归问题
"""
"""
回归问题,加载糖尿病病人数据集
"""
def load_dataset_regression():
diabetes = datasets.load_diabetes()
return model_selection.train_test_split(diabetes.data, diabetes.target,
test_size=0.25, random_state=0)
"""
分类问题,加载鸢尾花数据集
"""
def load_dataset_classfication():
diabetes = datasets.load_digits()
return model_selection.train_test_split(diabetes.data, diabetes.target,
test_size=0.25, random_state=0)
"""
梯度提升决策树用作分类
def __init__(self, loss='deviance', learning_rate=0.1, n_estimators=100,
subsample=1.0, criterion='friedman_mse', min_samples_split=2,
min_samples_leaf=1, min_weight_fraction_leaf=0.,
max_depth=3, min_impurity_decrease=0.,
min_impurity_split=None, init=None,
random_state=None, max_features=None, verbose=0,
max_leaf_nodes=None, warm_start=False,
presort='auto', validation_fraction=0.1,
n_iter_no_change=None, tol=1e-4):
loss:损失函数 deviance默认 exponential指数损失函数,
learning_rate 学习率
n_estimators整数,指定基础决策树数量
subsample=1.0浮点数,训练样本子集占原始训练集的大小
warm_start=False,是否使用上一次的训练结果
方法:
stage_predict():返回一个数组,数组元素为每一轮迭代结束时集成分类器的预测值。
"""
def test_GradientBoostingClassifier(*args):
X_train, X_test, y_train, y_test = args
clf = ensemble.GradientBoostingClassifier()
clf.fit(X_train, y_train)
print("training score:%f" %clf.score(X_train, y_train))
print("testing score: %f" %clf.score(X_test, y_test))
def test_GradientBoostingClassifier_maxdepth(*args):
from sklearn.naive_bayes import GaussianNB
X_train, X_test, y_train, y_test = args
max_depth = np.arange(1, 20)
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
test_score = []
train_score = []
for i in max_depth:
clf = ensemble.GradientBoostingClassifier(max_depth=i, max_leaf_nodes=None)
clf.fit(X_train, y_train)
train_score.append(clf.score(X_train, y_train))
test_score.append(clf.score(X_test, y_test))
ax.plot(max_depth, train_score, label="Traning score")
ax.plot(max_depth, test_score, label="Testing score")
ax.set_xlabel("max depth")
ax.set_ylabel("score")
ax.legend(loc="lower right")
ax.set_ylim(0, 1.05)
ax.set_title("Gradient Boosting Classifier")
plt.show()
"""
梯度提升树回归
__init__(self, loss='ls', learning_rate=0.1, n_estimators=100,
subsample=1.0, criterion='friedman_mse', min_samples_split=2,
min_samples_leaf=1, min_weight_fraction_leaf=0.,
max_depth=3, min_impurity_decrease=0.,
min_impurity_split=None, init=None, random_state=None,
max_features=None, alpha=0.9, verbose=0, max_leaf_nodes=None,
warm_start=False, presort='auto', validation_fraction=0.1,
n_iter_no_change=None, tol=1e-4):
loss损失函数,ls平方损失函数, lad绝对值损失函数,huber两者结合
n_estimators整数,基础决策树个数,
max_depth:个体回归树最大深度
subsample:浮点数,单个回归数训练集占原始数据集的大小,小于1.0则为随机梯度提升回归数
max_feature:指定基础决策树的max_feature模型
"""
def test_GradientBoostingRegressor(*args):
X_train, X_test, y_train, y_test = args
regr = ensemble.GradientBoostingRegressor()
regr.fit(X_train, y_train)
print("training score:%f" % regr.score(X_train, y_train))
print("testing score: %f" % regr.score(X_test, y_test))
if __name__ == '__main__':
X_train, X_test, y_train, y_test = load_dataset_classfication()
X_train, X_test, y_train, y_test = load_dataset_regression()
# test_GradientBoostingClassifier(X_train, X_test, y_train, y_test)
# test_GradientBoostingClassifier_maxdepth(X_train, X_test, y_train, y_test)
test_GradientBoostingRegressor(X_train, X_test, y_train, y_test)