语法分析是编译过程的核心部分,它的主要作用是根据单词找出符合语法规则的句子。语法分析通常分为两类:自上而下分析和自下而上分析。本章介绍前者。
自上而下分析的主旨是,对任何一个输入串,试图用一切可能的办法,从文法的开始符号(根节点)出发,根据文法自上而下地为输入串建立一棵语法树,即为输入串寻找一个最左推导。本质上是一种试探过程,是反复使用不同产生式谋求匹配输入串的过程。
自上而下分析也面临很多问题:
1.文法的左递归问题,会使分析过程陷入无限循环。
2.若匹配不成功,需要回溯。需要把已经做过的一大堆工作(各种表格工作、语义分析等)推倒重来,既费时又费力。
3.虚假匹配的问题。由于虚假现象,我们需要更复杂的回溯技术,一般来说,要消除虚假匹配是很困难的。
4.当最终报告分析不成功时,难于知道输入串中出错的确切位置。
5.由于带回溯,实际上才用了一种穷尽一切可能的试探法,因此,效率很低,代价极高。该方法只有理论意义,在实践上价值不大。
由于自上而下分析方法不允许文法含有任何左递归。为构造不带回溯的自上而下算法,首先要消除文法的左递归性。
直接用用右递归代替左递归:
设有产生式
P→Pα|β (1)
其中β不以P开头,α不为ε。那么,我们可以把P的规则改为如下的非直接左递归形式:
P→βP’
P’→αP’|ε (2)
(1)式和(2)式是等价的
消除间接左递归:
(1)将间接左递归改造为直接左递归
(2)消除直接左递归
P→Pα1|Pα2|…|Pαm|β1| β2|…| βn
消除P的左递归
P→ β1P’| β2P’|…| βnP’
P’→α1 P’| α2 P’|…|αm P’| ε
(3)化简改写后的文法,即去除那些从开始符号出发却永远无法到达的非终结符的产生规则。
最终得到无左递归的文法。
欲构造行之有效的自上而下分析器,必须消除回溯。把一个文法改造成任何非终结符的所有候选首符两两不相交就可以消除回溯。其办法是,提取公共左因子。经过反复的提取左因子,就可达到目的。
不带回溯的自上而下分析的文法条件(LL(1)文法)
(1)文法不含左递归
(2)对于文法中每一个非终结符A的各个产生式的候选式的FIRST集两两不相交。即,若
A→α1|α2|…|αn
则 FIRST(αi)∩FIRST(αj)=Φ (i≠j)
(3)对于文法中的每个非终结符A,若它的某个候选首符集包含ε,则
FIRST(A)∩FOLLOW(A)=Φ
如果一个文法G满足以上条件,则称该文法G为LL(1)文法(第1个L代表从左到右扫描输入串,第2个L代表最左推导,1表示分析时每一步只看1个符号)
当一个文法满足LL(1)条件时,我们就可以构造一个不带回溯的自上而下分析程序,这个分析程序由一组(可能的)递归程序组成,每个过程对应文法的一个非终结符。这样一个分析程序称为递归下降分析器。
具体做法:
对文法的每一个非终结符都编一个分析程序,当根据文法和当时的输入符号预测到要用某个非终结符去匹配输入串时,就调用该非终结符的分析程序。
LL-自左向右扫描、自左向右的分析和匹配输入串。分析过程表现为最左推导的性质。该过程由分析表、总控程序、符号栈三部分组成。由于最左推导,进栈过程是逆序的。
最后是关于构造预测分析表:
构造FIRST集:
1.若X终结符,则FIRST(X)={X}
2.若X为非终结符,且有X->a…的产生式,则把a加入到FIRST(X)中;
3.若X->Y…是一个产生式,且Y为非终结符,则把FIRST(Y)-ε加入到FIRST(X)中;
若X->Y1Y2Y3….YK,是产生式, Y1Y2Y3….Yi-1是非终结符,而且ε属于FIRST (Yj)(1<=j<=i-1),则把FIRST (Yj)-ε加入到FIRST(X)中;如果ε属于所有的FIRST (Yj),则ε加入到FIRST(X)中
构造FOLLOW集:
- 对于文法的开始符,置#于FOLLOW(S)中
- 若A->αBβ, 则把FIRST (β)-ε加入到FOLLOW(B)中,
- 若A->αB 是一个产生式,或 A->αBβ是一个产生式,而β-> ε,则把FOLLOW(A)加入到FOLLOW(B)中
构造分析表的算法:
对文法G的每个产生式, A->α,进行下面的处理
- 对每个终结符a,如果a属于FIRST(α),则把该产生式写入到M[A,a]
- 若ε属于FIRST(α),则对任何b属于FOLLOW(A), 把该产生式加入到M[A,b]
- 所有无定义的M[A,a]标上出错标志
应用:
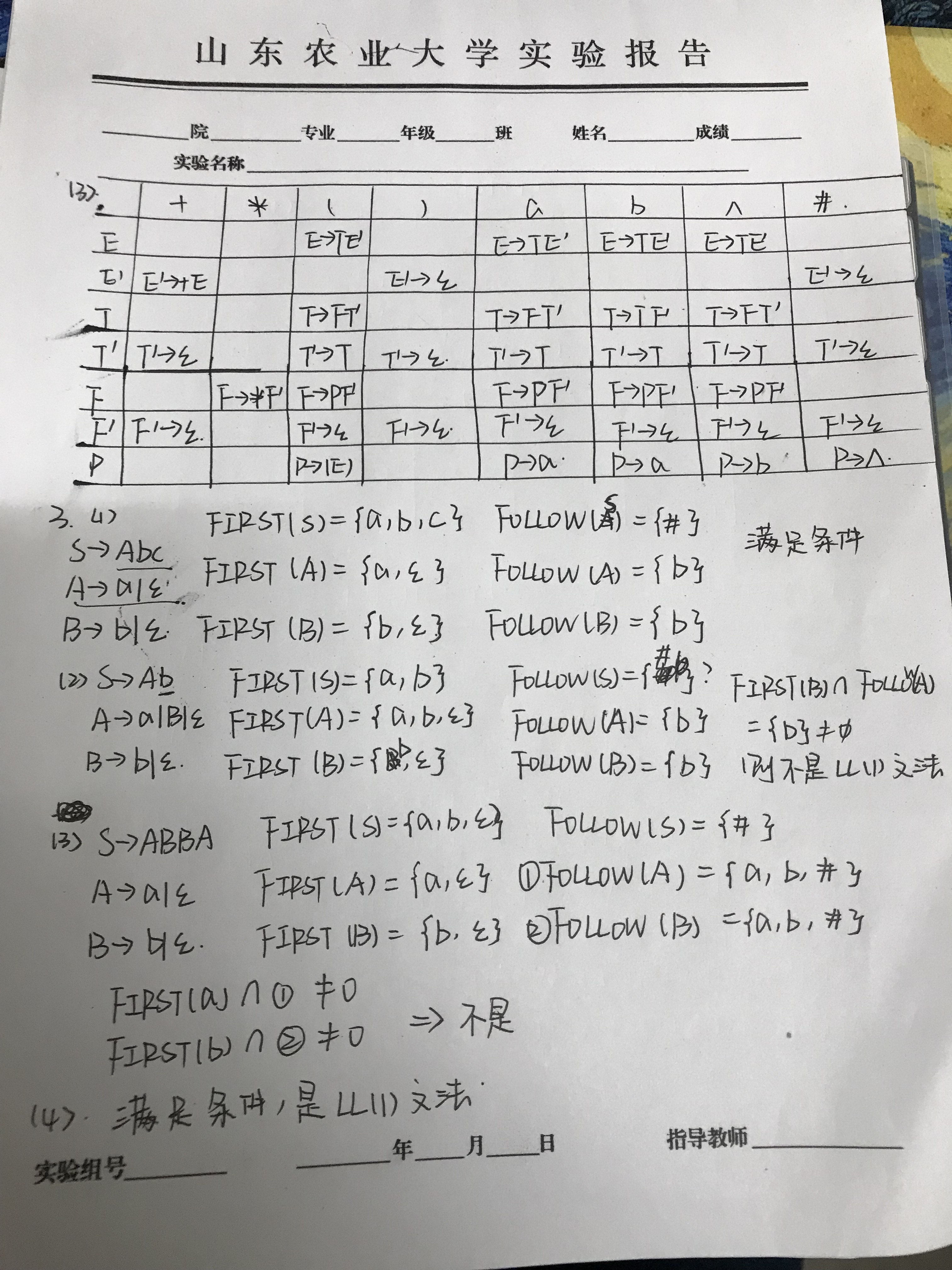

这一章较前面内容复杂,做起题来有些吃力。通过做课后习题,我感觉对于求FIRST集和FOLLOW集很重要。位次查阅了资料,但是网上说的感觉都有点不同,但是照着来做题勉强能做出来,但是对于求FOLLOW集有时还是会有些失误。对于构造分析表也还是需要进一步的钻研。