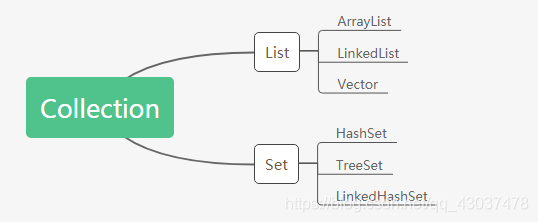
Java中的集合主要分为三类:
- List(列表)
- Set(集合)
- Map(键值对)
Map、List、Set三者关系图
Set集合
Set(集合)特点:存储的数据不保证有序(存在有序情况),不允许重复元素,可以存放空元素,但只允许一个空元素存在。
Set主要有三个实现类
- HashSet:是线程不同步的,HashSet类按照hash算法来存取集合中的对象,存储的数据不保证有序(存在有序情况),存取速度快。存入HashSet的对象必须定义hashCode()。
- TreeSet:是线程不同步的,它基于TreeMap的NavigableSet实现,TreeSet类实现了SortedSet接口,能够对集合中的对象进行排序(默认是升序)。底层数据结构为:二叉树。使用它可以从Set中提取有序的序列。
- LinkedHashSet:哈希表和链表实现的集合接口,具有HashSet的查询速度,且内部使用链表(双向链表)维护元素的顺序(插入的次序),于是在使用迭代器遍历Set时,结果会按元素插入的次序显示。
set集合为什么不能重复?
set的两个主要实现类,TreeSet和HashSet,底层存储结构都是用的map,而且是将set需要存储的值放在map的key里的,present是一个空的object对象。
Set集合在调用add方法的时候,add方法会调用元素的hashCode方法和equals方法,判断元素是否重复。
根据add的数据的HashCode方法计算哈希值,如果集合中不存在的话就保存到集合中,如果存在哈希值(哈希碰撞)就用equals比较,如果为false就保存到集合中,否则就是重复值,
List列表
List的特征是其元素以线性方式存储,集合中可以存放重复对象。 List接口主要实现类包括:(参考文章:
ArrayList与LinkedList的区别
)
- ArrayList() : 底层是数组,代表长度可以改变得数组。可以对元素进行随机的访问,向ArrayList()中插入与删除元素的速度慢。因为要移动数组
默认长度为0,第一次add的时候设置初始容量为10,超过10的话会扩容为原来的1.5倍+1,也就是15.+1
- LinkedList(): 在实现中采用双向链表数据结构。插入和删除速度快,访问速度慢。
- Vector(): 跟ArrayList类似,不同于ArrayList的是,vector是线程安全的(线程同步),实现同步需要花费一些时间,因此效率要低于ArrayList。
默认长度为0,第一次add的时候设置初始容量为10,超过10会扩容为原来的2倍,也就是20.
对于List的随机访问来说,就是只随机来检索位于特定位置的元素。 List 的 get(int index) 方法放回集合中由参数index指定的索引位置的对象,下标从“0” 开始。
排序方法:
Collections.sort,Arrays.sort两种
Collections.sort方法底层就是调用的Arrays.sort方法,而Arrays.sort使用了两种排序方法,快速排序(快)和优化的归并排序(稳定)。
数据量小于47:
使用插入排序,插入排序是稳定的
47-286 的数据量:
根据数据类型选择排序方式。
- 基本类型:使用快速排序(因为基本类型1、2、2都是指向同一个常量池,不需要考虑稳定性)。
- Object类型:使用归并排序(因为归并排序具有稳定性)。
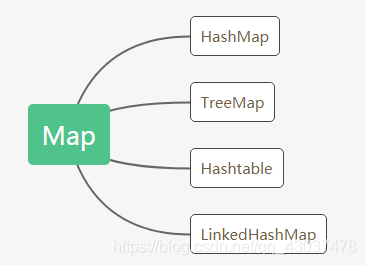
Map(映射)
Map 是一种把键对象和值对象映射的集合,它的每一个元素都包含一对键对象和值对象。 Map没有继承于Collection接口 从Map集合中检索元素时,只要给出键对象,就会返回对应的值对象。
- HashMap:Map基于散列表的实现。插入和查询“键值对”的开销是固定的。可以通过构造器设置容量capacity和负载因子load factor,以调整容器的性能。初始容量16,负载因子为0.75,插入第13个元素时发生扩容,扩容为原来的2倍
- LinkedHashMap: 类似于HashMap,但是迭代遍历它时,取得“键值对”的顺序是其插入次序,或者是最近最少使用(LRU)的次序。只比HashMap慢一点。而在迭代访问时发而更快,因为它使用链表维护内部次序。
-
TreeMap : 基于红黑树数据结构的实现。查看“键”或“键值对”时,它们会被排序(次序优先由Comparabel或Comparator决定,如果没有传入
Comparator
默认按照key升序排序)。TreeMap的特点在 于,你得到的结果是经过排序的。TreeMap是唯一的带有subMap()方法的Map,它可以返回一个子树。
Map各个子类详解
↓↓↓
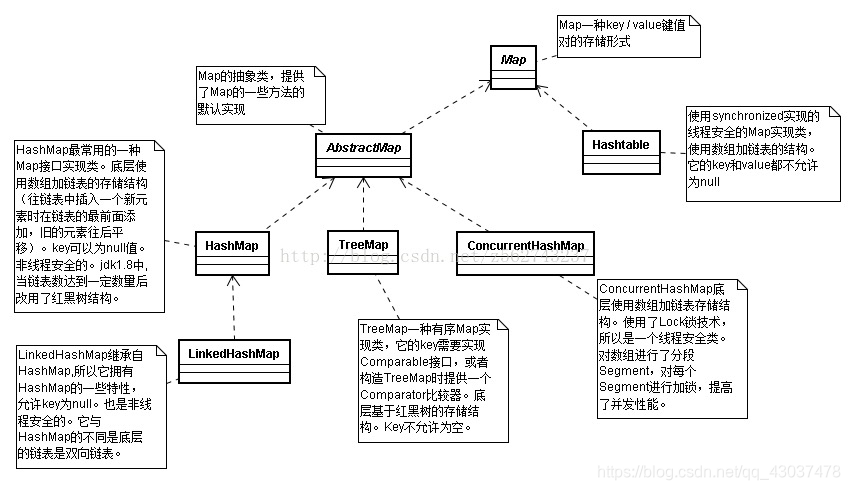
HashMap是不是线程安全的?
线程不安全,
在jdk1.7中,在多线程环境下,扩容时会造成环形链(发生在扩容的时候)或者数据丢失(多线程修改数据的时候,因为HashMap底层是一个Entry数组,当发生hash冲突的时候,hashmap是采用链表的方式来解决的,在对应的数组位置存放链表的
头结点
。对链表而言,新加入的节点会从头结点加入。如果多个线程同时访问一个哈希映射,而其中至少一个线程从结构上修改了该映射,导致数据被覆盖)。
在jdk1.8中,在多线程环境下,会发生数据覆盖的情况。
ConcurrentHashMap跟HashMap、HashTable区别?
具体看:
ConcurrentHashMap在jdk1.7和jdk1.8中的不同;_卓立苍穹的博客-CSDN博客_concurrenthashmap1.7和1.8的区别
线程安全方面:
hashMap是线程不安全的,
hashTable是线程安全的,实现线程安全的机制是使用Synchronized关键字修饰方法。
<JDK1.7>,
分段锁 对整个桶数组进行了分割分段(Segment),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。
<JDK1.8>
使用的是优化的synchronized 关键字同步代码块 和 cas操作了维护并发
底层数据结构:
hashMap同hashTable;都是使用数组 + 链表结构
ConcurrentHashMap
<JDK1.7> :使用 Segment数组 + HashEntry数组 + 链表
<JDK1.8> :使用 Node数组+链表+ 红黑树
效率:
hashMap只能单线程操作,效率低下
hashTable使用的是synchronized方法锁,若一个线程抢夺了锁,其他线程只能等到持锁线程操作完成之后才能抢锁操作
《1.7》ConcurrentHashMap 使用的分段锁,如果一个线程占用一段,别的线程可以操作别的部分,
《1.8》简化结构,put和get不用二次哈希,一把锁只锁住一个链表或者一棵树,并发效率更加提升。
LinkedHashMap为什么能实现有序?
排序原理:LinkedHashMap复写了HashMap的newNode(hash, key, value, null) 方法,

由源码可知,put第一次的时候 tail 和 head 都赋值为第一次put的数据,从第二个开始每次都将 tail(尾) 设置 为当前值,同时记录before(前一个数据)是谁并通知前一个数据记录它的后一个数据为自己,以此类推。。。我们只需要知道head(头)是谁,就能知道下一个是谁,tail(尾)为最后一个数据。
举例
:我们依次插入A、B、C三个数据
1、插入 A 用户,设置 tail 和 head 为 A。
2、插入 B 用户,设置 tail 为 B,记录B的Before(前一个)数据为 A,通知前一个数据 A,叫 A 记录它的 After(后一个)数据为 B。
3、以此类推 。。。
当我们查看数据的时候可以根据他们的链式关系知道先后顺序:A -> B -> C
区别
容器内每个为之所存储的元素个数不同。
Collection类型者,每个位置只有一个元素。
Map类型者,持有 key-value pair,像个小型数据库。