系统环境
Linux Ubuntu 16.04
jdk-7u75-linux-x64
hadoop-2.6.0-cdh5.4.5
hadoop-2.6.0-eclipse-cdh5.4.5.jar
eclipse-java-juno-SR2-linux-gtk-x86_64
相关知识
一些复杂的任务难以用一次MapReduce处理完成,需要多次MapReduce才能完成任务。Hadoop2.0开始MapReduce作业支持链式处理,类似于工厂的生产线,每一个阶段都有特定的任务要处理,比如提供原配件——>组装——打印出厂日期,等等。通过这样进一步的分工,从而提高了生成效率,我们Hadoop中的链式MapReduce也是如此,这些Mapper可以像水流一样,一级一级向后处理,有点类似于Linux的管道。前一个Mapper的输出结果直接可以作为下一个Mapper的输入,形成一个流水线。
链式MapReduce的执行规则:整个Job中只能有一个Reducer,在Reducer前面可以有一个或者多个Mapper,在Reducer的后面可以有0个或者多个Mapper。
Hadoop2.0支持的链式处理MapReduce作业有以下三种:
(1)顺序链接MapReduce作业
类似于Unix中的管道:mapreduce-1 | mapreduce-2 | mapreduce-3 …,每一个阶段创建一个job,并将当前输入路径设为前一个的输出。在最后阶段删除链上生成的中间数据。
(2)具有复杂依赖的MapReduce链接
若mapreduce-1处理一个数据集, mapreduce-2 处理另一个数据集,而mapreduce-3对前两个做内部链接。这种情况通过Job和JobControl类管理非线性作业间的依赖。如x.addDependingJob(y)意味着x在y完成前不会启动。
(3)预处理和后处理的链接
一般将预处理和后处理写为Mapper任务。可以自己进行链接或使用ChainMapper和ChainReducer类,生成作业表达式类似于:
MAP+ | REDUCE | MAP*
如以下作业: Map1 | Map2 | Reduce | Map3 | Map4,把Map2和Reduce视为MapReduce作业核心。Map1作为前处理,Map3, Map4作为后处理。ChainMapper使用模式:预处理作业,ChainReducer使用模式:设置Reducer并添加后处理Mapper
本实验中用到的就是第三种作业模式:预处理和后处理的链接,生成作业表达式类似于 Map1 | Map2 | Reduce | Map3
任务内容
练习使用ChainMapReduce处理文件,现有某电商一天商品浏览情况数据goods_0,功能为在第一个Mapper里面过滤掉点击量大于600的商品,在第二个Mapper中过滤掉点击量在100~600之间的商品,Reducer里面进行分类汇总并输出,在Reducer后的Mapper里过滤掉商品名长度大于或等于3的商品
实验数据如下:
表goods_0,包含两个字段(商品名称,点击量),分隔符为”\t”
商品名称 点击量
袜子 189
毛衣 600
裤子 780
鞋子 30
呢子外套 90
牛仔外套 130
羽绒服 7
帽子 21
帽子 6
羽绒服 12
结果数据如下:
商品名称 点击量
帽子 27.0
鞋子 30.0
任务步骤
1,切换到/apps/hadoop/sbin目录下,开启Hadoop。
cd /apps/hadoop/sbin
./start-all.sh
2,在Linux本地新建/data/mapreduce10目录。
mkdir -p /data/mapreduce10
3,在Linux中切换到/data/mapreduce10目录下,用wget命令从http://192.168.1.100:60000/allfiles/mapreduce10/goods_0网址上下载文本文件goods_0。
cd /data/mapreduce10
wget http://192.168.1.100:60000/allfiles/mapreduce10/goods_0
然后在当前目录下用wget命令从http://192.168.1.100:60000/allfiles/mapreduce10/hadoop2lib.tar.gz网址上下载项目用到的依赖包。
wget http://192.168.1.100:60000/allfiles/mapreduce10/hadoop2lib.tar.gz
将hadoop2lib.tar.gz解压到当前目录下。
tar zxvf hadoop2lib.tar.gz
4,首先在HDFS上新建/mymapreduce10/in目录,然后将Linux本地/data/mapreduce10目录下的goods_0文件导入到HDFS的/mymapreduce10/in目录中。
hadoop fs -mkdir -p /mymapreduce10/in
hadoop fs -put /data/mapreduce10/goods_0 /mymapreduce10/in
5,打开Eclipse,新建Java Project项目,项目名为mapreduce10

在mapreduce10项目下新建mapreduce包,在mapreduce包下新建ChainMapReduce类。
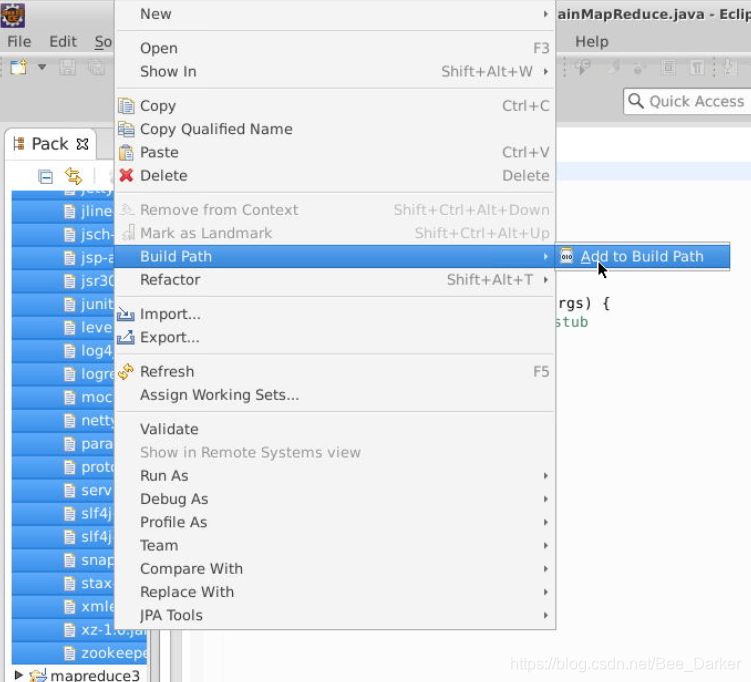
6,添加项目所需依赖的jar包右键项目,新建一个文件夹,用于存放项目所需的jar包。

将/data/mapreduce10目录下,hadoop2lib目录中的jar包,拷贝到eclipse中mapreduce10项目的hadoop2lib目录下,选中所有项目hadoop2lib目录下所有jar包,单击右键选择Build Path=>Add to Build Path。
7,编写程序代码,并描述其设计思路。
mapreduce执行的大体流程如下图所示:

由上图可知,ChainMapReduce的执行流程为:①首先将文本文件中的数据通过InputFormat实例切割成多个小数据集InputSplit,然后通过RecordReader实例将小数据集InputSplit解析为<key,value>的键值对并提交给Mapper1;②Mapper1里的map函数将输入的value进行切割,把商品名字段作为key值,点击数量字段作为value值,筛选出value值小于等于600的<key,value>,将<key,value>输出给Mapper2,③Mapper2里的map函数再筛选出value值小于100的<key,value>,并将<key,value>输出;④Mapper2输出的<key,value>键值对先经过shuffle,将key值相同的所有value放到一个集合,形成<key,value-list>,然后将所有的<key,value-list>输入给Reducer;⑤Reducer里的reduce函数将value-list集合中的元素进行累加求和作为新的value,并将<key,value>输出给Mapper3,⑥Mapper3里的map函数筛选出key值小于3个字符的<key,value>,并将<key,value>以文本的格式输出到hdfs上。该ChainMapReduce的Java代码主要分为四个部分,分别为:FilterMapper1,FilterMapper2,SumReducer,FilterMapper3。
FilterMapper1代码
public static class FilterMapper1 extends Mapper<LongWritable, Text, Text, DoubleWritable> {
private Text outKey = new Text(); //声明对象outKey
private DoubleWritable outValue = new DoubleWritable(); //声明对象outValue
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, DoubleWritable>.Context context)
throws IOException,InterruptedException {
String line = value.toString();
if (line.length() > 0) {
String[] splits = line.split("\t"); //按行对内容进行切分
double visit = Double.parseDouble(splits[1].trim());
if (visit <= 600) {
//if循环,判断visit是否小于等于600
outKey.set(splits