

图源:pixabay
原文来源:towardsdatascience
作者:Alvira Swalin
「雷克世界」编译:EVA
我最近参加了Kaggle竞赛(WIDS Datathon),在那里我通过使用各种各样的Boosting算法而进入前10名。从那时起,我一直对每个模型精细的工作,包括参数调优、优缺点,都非常好奇,因此决定写下这篇文章。尽管最近神经网络重新出现并流行,我还是着重关注Boosting算法,因为它们在训练数据有限、训练时间少、专业知识少的参数调优体系中仍然能够发挥很大的作用。
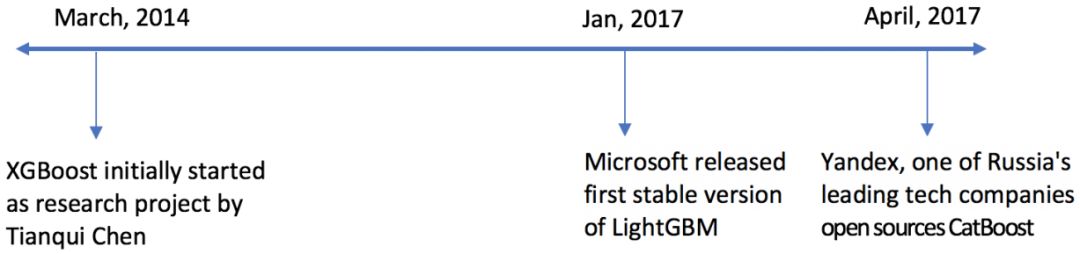
XGBoost最初是由陈天奇于2014年3月发起的一个研究项目。2017年1月,微软发布了第一个稳定的LightGBM版本。2017年4月,俄罗斯的一个领先的科技公司—Yandex,发布开源CatBoost
XGBoost(通常被称为GBM杀手)已经在机器学习领域里盛行很长一段时间了,现在有很多专门阐述该技术的文章。因此,本文将更多地聚焦于CatBoost和LGBM。我们将要讨论的话题涵盖以下几点:
•结构的差异
•每个算法对分类变量的处理
•参数的理解
•数据集的实现
•每个算法的性能
LightGBM和XGBoost的结构差异
LightGBM使用一种全新的基于梯度的单侧采样(GOSS)技术来过滤数据实例,以寻找分割值。而XGBoost则是使用预分类算法(presorted algorithm)和基于直方图的算法来计算最佳分割。这里,实例意味着观察值/样本。
首先,让我们来了解一下预分类的分割是如何进行的:
•对于每个节点,列举所有的特征
•对于每个特征,按特征值对实例进行分类
•使用线性扫描根据该特征基础信息增益的程度确定最佳分割
•以最佳的分割解决方案来处理所有的特征
简单地说,基于直方图的算法将一个特征的所有数据点分割到离散的容器中,并使用这些容器来寻找直方图的分割值。尽管它在训练速度方面比预分类算法效率高,因为预分类算法列举了预分类特征值所有可能的分割点的,但它在速度方面仍然落后于GOSS。
那么,是什么让GOSS方法更高效呢?
在AdaBoost中,样本权重可以作为样本重要性的一个很好的指标。然而,在梯度提升决策树(GBDT)中没有原始的样本权重,因此针对AdaBoost的采样方法不能直接应用到其中。这里就需要基于梯度的采样。
梯度代表了损失函数的切线斜率。所以从逻辑上说,如果数据点的梯度在某种意义上是很大的,那么这些点对于找到最优的分割点来说是很重要的,因为它们有更高的误差。
GOSS保留所有具有大梯度的实例,并在具有小梯度的实例上执行随机采样。例如,假设我有50万行数据,1万行有更高的梯度。所以我的算法会选择(更高梯度的1万行+剩余49万行随机选择的x%)。假设x是10%,那么在发现的分割值的基础上,选择的全部行数是50万中的5万9千。
这里的基本假设是,具有小梯度训练实例的样本训练误差较小,并且已经训练得很好。
为了保持相同的数据分布,当计算信息增益时,GOSS为小梯度的数据实例引入了一个常数乘数。因此,GOSS在减少数据实例的数量和保持学习决策树的精确性之间取得了良好的平衡。

高梯度/误差的叶子在LGBM中进一步使用
每个模型如何处理分类变量?
· CatBoost
CatBoost具有提供分类列索引的灵活性,这样就可以使用one_hot_max_size将其编码为独热编码(对于所有具有小于或等于给定参数值的 特征使用独热编码进行编码)。
如果你在cat_features引数中传递任何内容,那么CatBoost将把所有的列都视为数值变量。
注意:如果没有在cat_features中提供具有字符串值的列,CatBoost会显示错误。另外,默认整型的列会被默认当作数值处理,因此必须在cat_features中对它进行详细说明以使算法将其视为分类。

对于剩下的那些具有罕见的比one_hot_max_size更大的若干类别的分类列,CatBoost使用一种有效的编码方法,它与平均数编码相似,但减少了过度拟合。过程是这样的:
1.对输入的观察值的集合进行随机排列,生成多个随机排列。
2.将标签值从浮点或类别转换为整数
3. 使用如下公式将所有的分类特征值转换为数值:

其中,CountInClass是指,对于那些具有当前分类特征值的对象来说,其标签值等于”1″的次数。
Prior是分子的初始值。它由起始参数决定。
TotalCount是对象的总数(直到当前的一个),它具有与当前的对象相匹配的分类特征值。
从数学上讲,这可以用以下公式来表示:

· LightGBM
与CatBoost类似,LightGBM还可以通过输入特征名称来处理分类特征。它不转换为独热编码,而且比独热编码快得多。LGBM使用一种特殊的算法来寻找分类特性的分割值。

注意:在为LGBM构造数据集之前,你应该将你的分类特征转换为整型。即使你通过categorical_feature传递参数,它也不接受字符串值。
· XGBoost
与CatBoost或LGBM不同,XGBoost不能独自处理分类特征,它只接受与随机森林类似的数值。因此,在向XGBoost提供分类数据之前,必须执行各种编码,比如标签编码、平均数编码或独热编码。
超参数的相似性
所有这些模型都有很多参数需要调优,但我们只讨论重要的参数。下面是根据这些参数的功能和它们在不同模型中的对应而给出的的列表。

数据集的实现
我使用2015年的航班延误数据集,因为它具有分类特征和数值特征。它大约有500万行,对于使用每种Boosting算法类型进行调优的模型,这个数据集都能够很好地在速度和精确度两个方面来判断其性能。我将使用这个数据10%的子集——50万行。
下面是用于建模的特征:
MONTH, DAY, DAY_OF_WEEK: 整型数据
AIRLINE and FLIGHT_NUMBER: 整型数据
ORIGIN_AIRPORT and DESTINATION_AIRPORT: 字符型数据
DEPARTURE_TIME: 浮点型数据
ARRIVAL_DELAY: 这将是目标,并被转换为布尔变量,表明延迟超过10分钟
DISTANCE and AIR_TIME: 浮点型数据
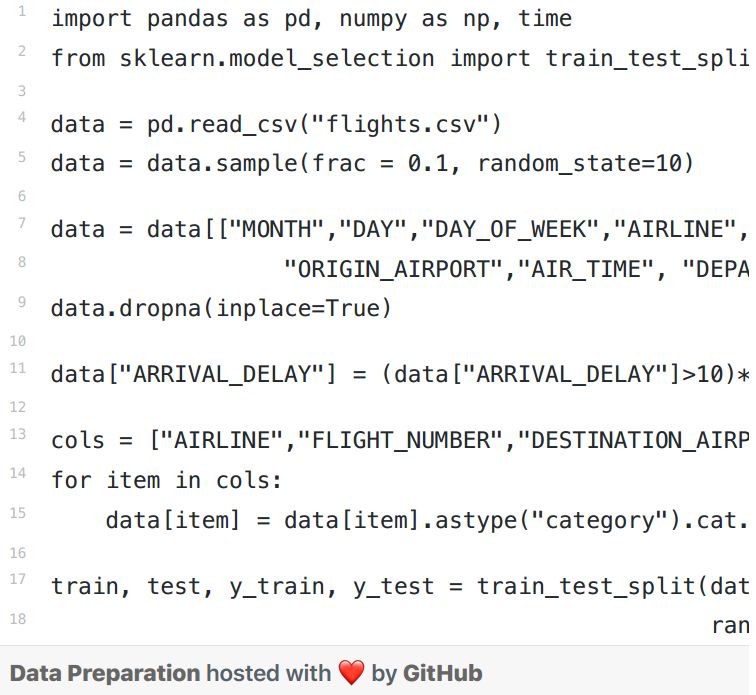
· XGBoost
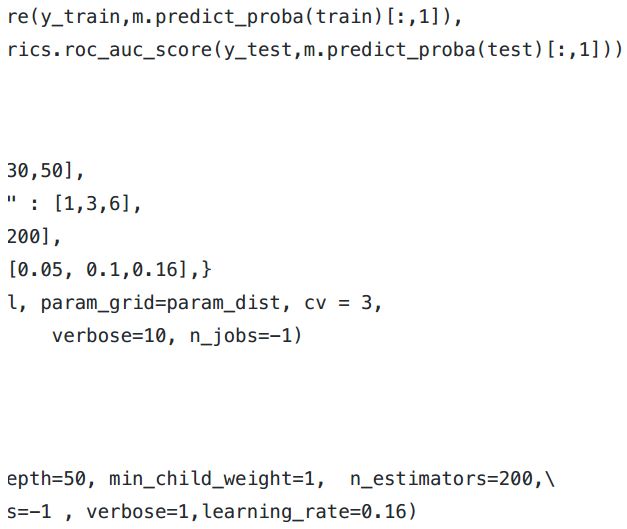
· LightGBM

· CatBoost
在对CatBoost进行调参时,很难传递分类特征的指数。因此,我在没有传递分类特征的情况下进行了调参,并对两个模型进行了评估——一个有分类特征而另一个没有。我已经单独调优了one_hot_max_size,因为它不会影响其他参数。

结果

总结说明
对于模型的评价,我们应该从速度和精确度两方面来考虑模型的性能。
记住这一点,CatBoost因在测试集中获得最大精确度(0.816)、最小过度拟合(训练和测试精度都很接近)和最小预测时间和调优时间,从而胜出。但这只是因为我们考虑了分类变量并调优了one_hot_max_size。如果我们不利用CatBoost的这些特征,那么它就会是最差的,只有0.752的精确度。因此,我们了解到,只有当我们在数据中有明确的分类变量并对它们进行正确的调优时,CatBoost才会表现得很好。
下一个是XGBoost,它整体运行良好。它的精确度非常接近于CatBoost,即使忽略这样一个事实:我们在数据中存在分类变量,且出于消耗成本的考虑,已将其转换为数值。然而,XGBoost唯一的问题是它太慢了。调优参数令人非常沮丧(花了6个小时来运行GridSearchCV)更好的方法是分别对参数参数进行调优,而不是使用GridSearchCV。
最后是Light GBM。这里需要注意的一点是,在使用cat_features时,它在速度和精确度方面都表现不佳。我认为它之所以表现不佳是因为它对分类数据使用了一种改良的平均值编码,从而导致了过度拟合(训练的精确度很高——0.999,比测试的准确度高)。但是,如果我们像XGBoost一样使用它,它可以用更快的速度获得与XGBoost(LGBM-0.785,XGBoost-0.789)类似的精确度(如果不是更高)。
最后,需要说明的是,这些观察结果对于这个特定的数据集来说是正确的,但对其他数据集是否依然有效,要视具体情况而定。然而,有一点是可以肯定的,那就是XGBoost比其他两种算法都要慢。
END
