引言
Transformer 是 Google 团队在 2017 年提出的一种 NLP 经典模型,现在比较火热的 Bert 也是基于 Transformer。Transformer 模型使用了 Self-Attention 机制,不采用 RNN 的顺序结构,使得模型可以并行化训练,而且能够拥有全局信息。
Transformer+Detection
DETR
Introduction
早在20年5月就有人引用Transformer处理目标检测任务(End-to-End Object Detection with Transformers),首次将Transformer从NLP引入到CV领域,该文章使用Transformer+Detection方式进行目标检测任务,取代了现在的模型需要手工设计的工作,并且取得了不错的结果。其准确率和运行时间上与Faster Rcnn相当。DETR是首次提出使用End to End的方式解决目标检测问题。
DETR architecture
DETR结合CNN和Transformer的结构,并行实现预测。DETR 通过删除编码先验知识的多个手工设计的组件(如空间锚点或非最大抑制)来简化检测流程。与大多数现有检测方法不同,DETR 不需要任何自定义层,可以在包含 CNN 和 Transformer 的任何框架中轻松重现。图1为DETR整体结构。

DETR整体结构主要包含四个部分:Backbone、Transformer encoder、Transformer decoder 和 Prediction feed-forward networks (FFNs),如图2为DETR框架细节图。
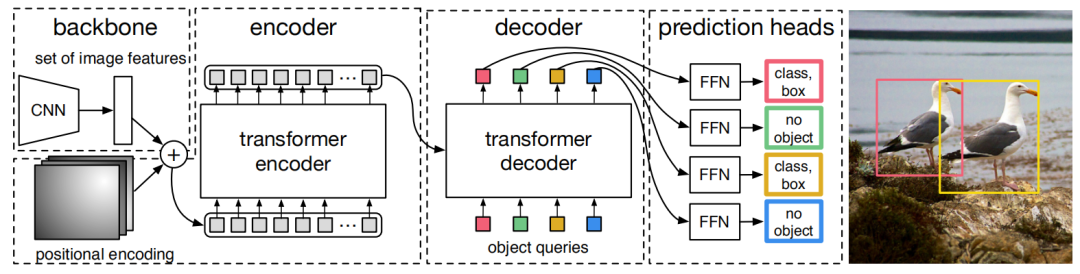
Backbone
CNN backbone处理原始输入图像,把它转换为低分辨率的 feature map 一般
Transformer encoder
encoder 的输入是 的 feature map,使用卷积降低通道维数,从 变为更小的 得到新的feature map 。encoder 需要一个序列输入,将空间维度折叠成维,最后得到的 feature map 尺寸为 。由于 Transformer 架构是置换不变的,使用固定位置编码对其进行补充,这些编码添加到每个注意力层的输入中。
Transformer decoder
DETR decoder 使用标准 Transformer decoder 结构,转换为个大小为 的 multi-headed self and encoder-decoder attention 机制,与原始 Transformer 的不同之处在于 DETR 模型在每个解码器层并行解码个对象,一次性输出全部的 predictions。通过使用self- and encoder-decoder attention 覆盖 embeddings,该模型使用它们之间的成对关系对所有对象进行全局推理,同时能够使用整个图像作为上下文。
Prediction feed-forward networks (FFNs)
最终预测由具有 ReLU 激活函数和隐藏维度 的 3 层感知器和线性映射层计算。FFN 预测框的归一化中心坐标、高度和宽度。输入图像,线性层使用 softmax 函数预测类别标签。由于 DETR 预测了一组固定大小的 个边界框,其中 通常远大于对象的实际数量,因此使用额外的特殊类标签 来表示在槽内没有检测到对象。该类与标准对象检测方法中的“背景”类起着类似的作用。
Experiments
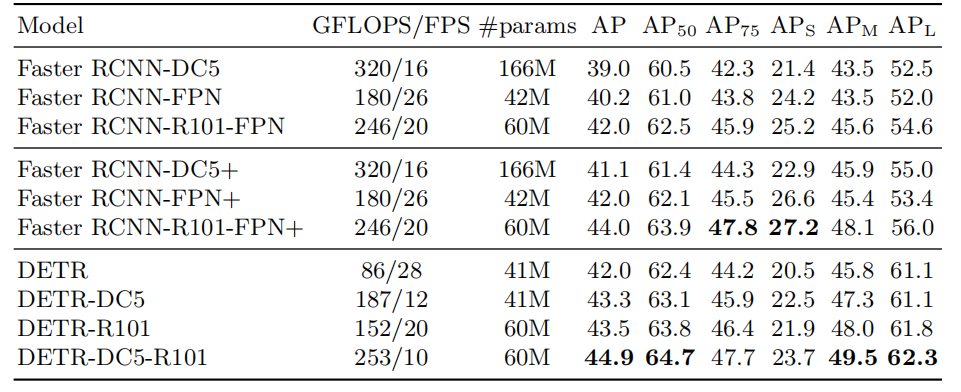
原文章使用COCO数据集与Faster R-CNN进行比较。图3为DETR系列与Faster R-CNN系列模型FLOPs对比。
Transformer+Classification
最开始 DETR 使用 Transformer 解决CV任务时,并没有引起非常大的轰动,真正引起巨大反响的是ViT的提出。Google Brain团队提出使用Transformer去解决CV经典的分类问题,ViT尽最大限度使用NLP下的Transformer,为视觉大模型提供了新的思路与方向。刚刚出来的ViT取得了ImageNet top1的准确率。ViT可以说是引领了 CV Transformer 的潮流,随着ViT的提出,后续引出大量文章都是将Transformer引入各种各样的视觉任务中,并且都能取得非常好的效果。
Vision Transformer
Introduction
Self-attention-based 结构特别是 Transformer 已成为 NLP 模型的标准处理模块。目前主流的方法是从大数据集进行大模型预训练,然后在较小的特定于任务的数据集上进行微调。在视觉任务上,CNN结构还是占主要地位,Transformer 在NLP领域取得非常好的结果,作者尝试直接将标准的Transformer结构直接应用于图像,使用监督学习的方法去训练分类任务。
使用 ImageNet-21k 数据集或Google未开源的内部 JFT-300M 数据集上进行预训练,ViT 在多个图像识别基准上接近或击败SOTA。模型测试结果在 ImageNet 上的准确率达到 88.55%,在 ImageNet-RealL 上达到 90.72%,在 CIFAR-100 上达到 94.55%,在 19 个任务的 VTAB 测试上达到 77.63%。
Method
将原始图像分割成固定大小的patch,线性 embedding 每个patch,同时添加位置 embedding,并将结果向量序列提供给标准的 Transformer encoder。为了结解决分类任务,使用标准方法向序列添加额外的可学习 classification token。Vision Transformer的整体结构如图4所示。
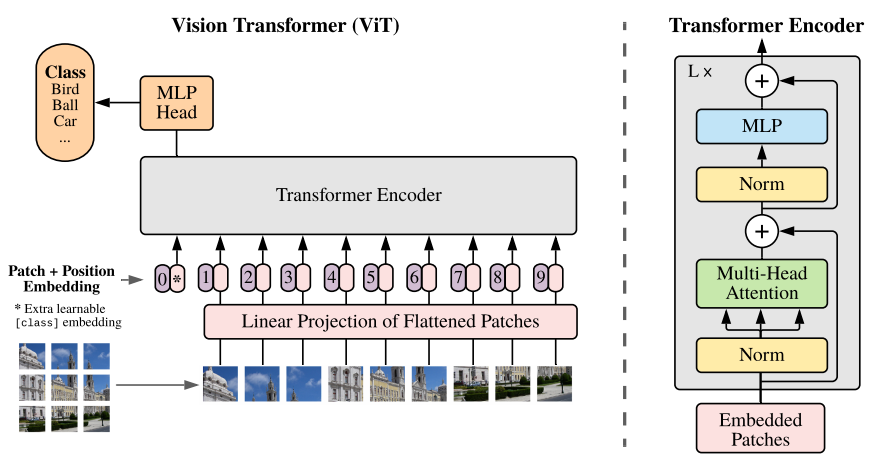
标准的Transformer结构输入为1维的token embeddings,为了处理2维的图像,需要将图像 reshape 成 flattened 二维 patches ,其中表示原始图像的分辨率,表示图像通道数,表示每个patch图像的分辨率,其中表示patch的数量。
Position embedding 为了获得每个patch 的相对位置关系,ViT使用标准可学习的1维位置embedding。
Experiments
主要对比ResNet,ViT以及ResNet与ViT的混合体三种框架。同时使用大数据集进行模型训练,然后对模型进行benchmark测试。作者分别使用ImageNet-1K、ImageNet-21K和JFT-300M三种数据集进行训练。
原文中测试了3种ViT模型,分别是ViT-Base、ViT-Large和ViT-Huge,三种模型的参数如图5所示。

实验结果如图6所示,整体模型比较大,经过大数据集进行预训练之后,性能超过了当前CNN的一些SOTA结果,其中对比的CNN模型主要有:Big Transfer模型,该模型使用大的ResNet进行有监督迁移学习获得的;Noisy Student模型,该模型在ImageNet和JFT-300M数据集上使用半监督学习进行训练的大型高效网络。所有的模型使用TPUv3进行训练。
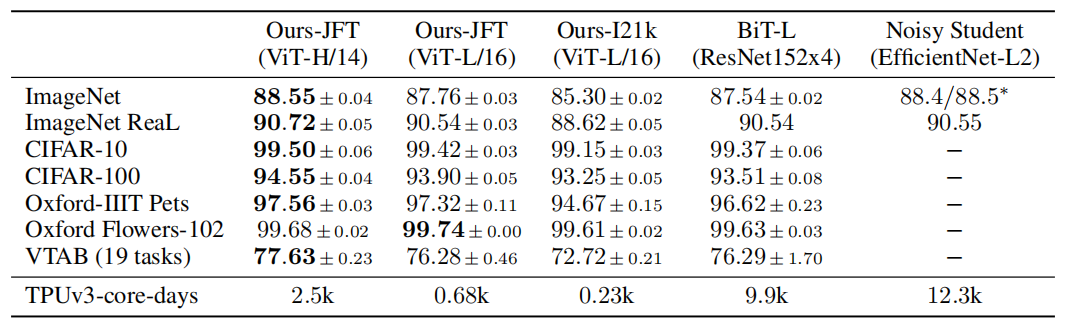
在JFT-300M上预先训练的较小的ViT-L/16模型在所有任务上都优于BiT-L(在同一数据集上预先训练的),同时训练所需的计算资源要少得多。更大的模型ViT-H/14进一步提高了性能,特别是在更具挑战性的数据集上—ImageNet, CIFAR-100和VTAB数据集。与现有技术相比,该模型预训练所需的计算量仍然要少得多。
图7为VTAB数据集在Natural, Specialized, 和Structured子任务与CNN模型相比的性能,ViT模型仍然可以取得最优。
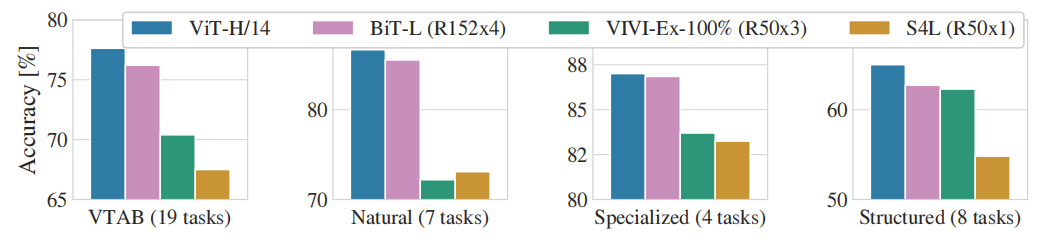
另外还对ViT预训练数据大小进行了测试,分别在ImageNet-1K、ImageNet-21K和JFT-300M数据集进行测试,测试结果如图8所示。
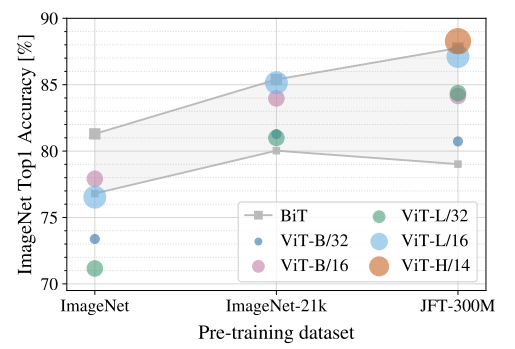
当在最小数据集ImageNet上进行预训练时,尽管进行了大量的正则化等操作,但ViT-大模型的性能不如ViT-Base模型。但是有了稍微大一点的ImageNet-21k预训练,它们的表现也差不多。只有到了JFT-300M,我们才能看到更大的ViT模型全部优势。图8还显示了不同大小的BiT模型跨越的性能区域。BiT CNNs在ImageNet上的表现优于ViT(尽管进行了正则化优化),但在更大的数据集上,ViT超过了所有的模型,取得了SOTA。
另外还进行了一个实验:在9M、30M和90M的随机子集以及完整的JFT-300M数据集上训练模型,结果如图9所示。ViT在较小数据集上的计算成本比ResNet高,ViT-B/32比ResNet50稍快;它在9M子集上表现更差,但在90M+子集上表现更好。ResNet152x2和ViT-L/16也是如此。这个结果强化了一种直觉,即:残差对于较小的数据集是有用的,但是对于较大的数据集,像attention一样学习相关性就足够了,甚至是更好的选择。
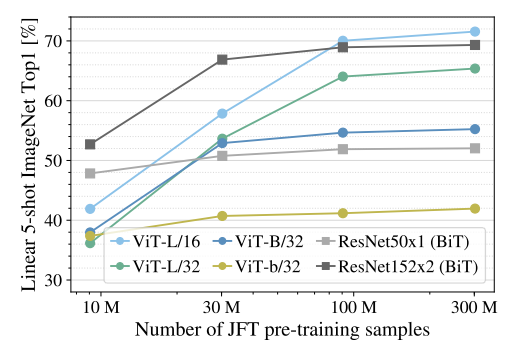
Scaling ViT
Introduction
基于注意力机制的 Transformer 架构已经席卷了 CV 领域,并成为研究和实践中日益流行的选择。此前,Transformer 被广泛用于 NLP 领域。有研究者仔细研究了自然语言处理中 Transformer 最优扩展,主要结论是大型模型不仅性能更好,而且更有效地使用了大量计算预算。然而,目前尚不清楚这些发现在多大程度上能够迁移到视觉领域。例如,视觉中最成功的预训练方案是有监督的,而 NLP 领域是无监督预训练。
原 ViT 团队成员、谷歌大脑的几位研究者集中研究了预训练 ViT 模型用于图像分类任务的迁移性能的扩展规则(scaling law)。特别是,研究者试验了从 500 万到 20 亿个参数不等的模型、从 3000 万到 30 亿个训练图像不等的数据集以及从低于 1 个 TPUv3 核每天(core-day)到超过 10000 个核每天的计算预算。其主要贡献是描述 ViT 模型的性能计算边界。
作者创建了一个改进的大规模训练方案,探索了训练超参数以及发现微妙的选择,大幅改善小样本迁移性能。具体来说,研究者发现非常强的 L2 正则化,仅应用于最终的线性预测层,导致学习到的视觉表征具有很强的小样本学习能力。该研究训练了一个具有 20 亿个参数的模型,在 ImageNet 数据集上达到了新的 SOTA 性能 90.45% 的准确率。
Method details
作者对 ViT 模型和训练进行了一些改进。这些改进大多易于实现,并且可以显着提高内存利用率和模型质量。优化后可以单独使用数据并行来训练 ViT-G/14,整个模型加载在单个 TPUv3 硬件上。
head 的解耦权重衰减
权重衰减对低数据情况下的模型自适应具有重大影响。作者在中等规模程度上研究了这一现象,并发现可以从模型中最终线性层(head)和剩余权重(body)的权重衰减强度解耦中获益。在 JFT-300M 上训练了一个 ViT-B/32 模型,每个单元格对应不同 head/body 权重衰减值的性能。观察到的有趣的一点是:尽管提升了迁移性能,但 head 中高权重衰减却降低了预训练(上游)任务的性能。图10为测试结果。
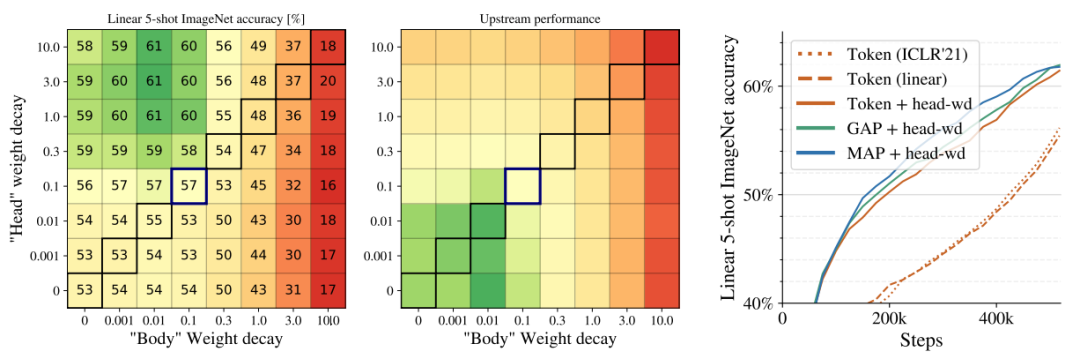
通过移除 [class] token 节省内存
对于 ViT 模型,当前的 TPU 硬件将 token 维数填充为 128 的倍数,这可能导致高度 50% 的内存开销。为了解决这一问题,作者尝试探索「使用额外[class] token」的替代方法。具体地,他们对全局平均池化( GAP)和多头注意力池化(MAP)进行评估以聚合来自所有 patch token 的表示,并将 MAP 中 head 的数量与模型其他部分中注意力 head 的数量设为相同。为了进一步简化 head 设计,研究者原始 ViT 论文中出现的、最终预测层之前的最终非线性映射。为了选择最佳 head,研究者对[class] token 和 GAP/MAP head 进行了并排比较,另外发现所有 head 的表现类似,同时 GAP 和 MAP 由于进行了填充(padding)考虑,因而具备更高的内存效率。此外,非线性映射还可以安全地进行移除。作者选择了 MAP head,这是因为其表现力最强,并且能够生成最统一的架构。
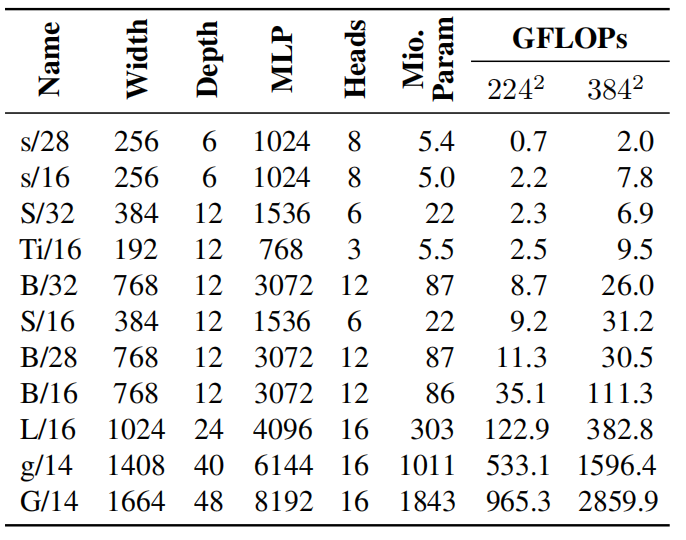
作者选择了 ViT 模型,模型参数从 500 万到 20 亿,训练数据量从 3000 万到 30 亿。下图 11 为具体的模型架构细节。
Experiments
训练了一个大型的视觉 Transformer,ViT-G/14,它包含近 20 亿个参数。实验评估了 ViT-G/14 模型在一系列下游任务中的应用,并将其与 SOTA 结果进行了比较。在 ImaegNet 上进行微调,并报告 ImageNet、ImageNet-v2、ReaL和 ObjectNet的准确率。此外,该研究还报告了在 VTAB-1k 基准上的迁移学习效果,该基准包括 19 个不同的任务。
图12展示了在ImageNet 小样本学习结果。结果显示,ViT-G/14 比以前最好的 ViT-H/14 模型表现优异(超过 5%),每类 10 个例子,模型准确率可达 84.86%。
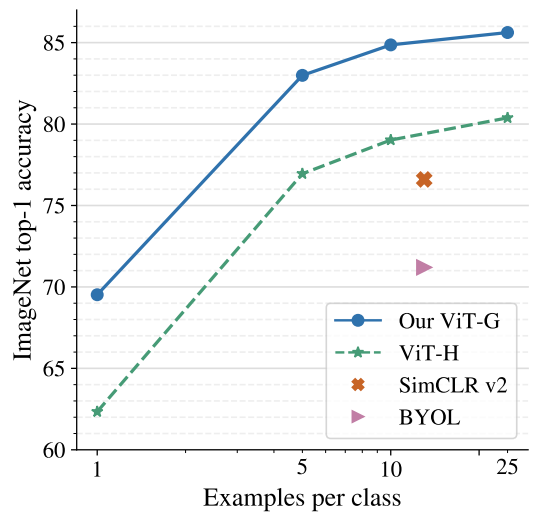
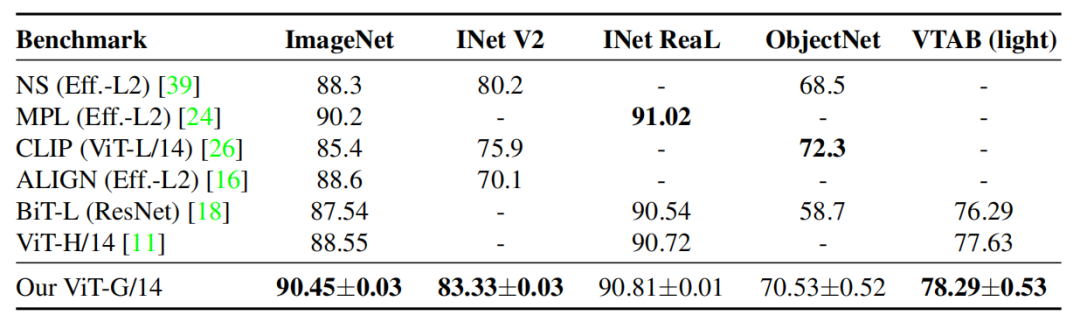
图13表示了其他benchmark结果。ViT-G/14 在 ImageNet 数据集上实现了 90.45% 的 Top-1 准确率,成为新的 SOTA。此外,在 ImageNet-v2 上,ViT-G/14 比基于 EfficientNet-L2 的 Noisy Student 模型提升了 3%。在 ReaL 数据集上,ViT-G/14 略微优于 ViT-H 和 BiT-L,再次表明 ImageNet 分类任务性能可能达到了饱和点。在 ObjectNet 数据集上,ViT-G/14 大幅度优于 BiT-L,较 Noisy Student 模型提升 2%,比 CLIP 落后约 2%。
Conclusion
研究表明视觉大模型在大数据集下会有更好的表现,训练出通用的视觉大模型,搭载迁移学习、知识蒸馏等技术,不仅能提高下游任务精度,还能节省人力。随着大数据、大计算力时代的到来,基于 Transformer 的视觉大模型会优于基于 CNN 的视觉模型。完成大模型训练还有很多的挑战,比如:单节点无法加载百亿级视觉模型,需要跨节点才能加载模型;大数据集有一部分是缺少标签,需要采用半监督方式进行训练。完成大模型训练还有更多地方需要探索。