摘要
在过去的十年中,深度卷积网络已经被广泛应用于医学图像分割,并显示出足够强的性能。然而,由于卷积架构中存在固有的归纳偏差,它们缺乏对于图像中长程相关性的理解。最近提出的利用自注意力机制的基于转换结构编码了长期依赖性。并学习了高度表达的表示。这促使我们探索基于Transformer的解决方案,并研究使用基于Transformer架构的可行性。大多数现有的基于Transformer的网络架构建议用于视觉应用需要大规模数据集来正确训练。然而,用于医学图像成像的数据样本量相对较低,使得难以训练用于医学应用的transformer。为此,我们提出了一个Gated Axial注意力模型,该模型通过在自我注意力模块中引入额外的控制机制来扩展现有的体系结构。此外,为了在医学图像上有效训练模型,我们提出了局部-全局训练策略(LoGo),进一步提高性能,具体来说,我们对整个图像和patch进行操作,分别学习全局和局部特征。在三个分割数据集上效果都不错
代码
.
1.Introduction
开发自动、准确和鲁棒的医学图像分割技术已经成为医学成像中的主要问题之一,因为它对于计算机辅助诊断和图像引导手术系统是必不可少的。从医学扫描中分割器官或病变有助于临床医生做出准确的诊断,规划手术过程,并提出治疗策略。
医学分割的早期方法使用统计形状模型、控制方法和基于机器学习的方法[41,32,9]。随着深度卷积神经网络在计算机视觉[14,8,1,28]中的流行,深度卷积神经网络被迅速用于医学图像分割任务。像U-Net [25]、V-Net [19]、3D U-Net [5]、Res-UNet [40]、DensEnet[17]、Y-Net [18]、U-Net++ [44]、KiU-Net [34,33]和U-Net3+ [11]这样的网络已经被专门提出用于为各种医学成像模式执行图像和体积分割。这些方法在许多困难的数据集上也取得了令人印象深刻的性能,证明了ConvNets在学习辨别特征以从医学扫描中分割器官或病变方面的有效性。
无论是医学成像还是计算机视觉任务,ConvNets都是目前提出的大多数图像分割方法的基本构件。然而,转换网络缺乏对图像中存在的长期相关性建模的能力。更准确地说,在卷积网络中,每个卷积核只处理整个图像中的局部像素子集,并迫使网络关注局部模式,而不是全局上下文。已经有一些工作集中于使用图像金字塔[42],atrous卷积[4]和注意力机制[12]来为ConvNets的远程依赖性建模。然而,可以注意到,由于大多数以前的方法不关注医学图像分割任务的这一方面,所以对于建模长期相关性仍有改进的余地。

图1。体内早产儿脑室的输入超声。通过(b) U-Net,© Res-UNet,(d) MedT和(e)地面实况进行预测。红色方框突出显示了由于缺乏学习到的长期相关性而被基于ConvNet的方法误分类的区域。这里的基本事实是由一位临床专家分割出来的。虽然它显示了心室区域内的一些出血,但它与分割区域不对应。基于变压器的模型可以正确捕获这些信息。
为了首先理解为什么医学图像的长程相关性很重要,我们设想了一个早产儿超声扫描的例子,并根据图1中的扫描对脑室进行了分割预测。对于提供有效分割的网络,它应该能够理解哪些像素对应于掩模,哪些对应于背景。给定单个像素,网络需要了解它是更接近背景的像素还是更接近分割掩模的像素。由于图像的背景是分散的,学习对应于背景的像素之间的长程相关性可以在网络中有助于防止将像素误分类为导致减少真实底片的掩模(考虑0作为背景,1作为分割掩模)。类似地,每当分割掩码很大时,学习对应于掩码的像素之间的长程相关性也有助于做出有效的预测。在图1 (b)和©中,我们可以看到卷积网络将背景误分类为脑室,而提出的基于变压器的方法没有犯这个错误。这发生在我们提出的方法学习像素区域与背景的长期依赖关系时。
像BERT [6]和GPT [23,24,2]这样的transformer模型最近已经彻底改变了大多数自然语言处理(NLP)任务,如机器翻译[21]、问答[26]和文档分类[22]。transformer成功的主要原因是它们能够学习输入令牌之间的长期依赖关系。这是可能的,因为自我关注机制可以发现输入中每个标记之间的依赖性。随着transformer在自然语言处理应用中的普及,它们最近已经被计算机视觉应用所采用。具体来说,视觉转换器(ViT) [7]成功地使用具有位置嵌入的2D图像块作为输入序列,类似于语言转换器模型的输入序列。当在大图像数据集上进行预训练时,它在图像识别方面获得了与卷积网络相当的性能。提出了数据高效的图像转换器(DeiT) [31],展示了如何将转换器用于中型数据集。关于用于分割任务的变压器,轴向深度实验室[37]利用了轴向注意模块[10],该模块将2D自我注意分解为两个1D自我注意,并引入了用于全景分割的位置敏感轴向注意设计。接下来是MaX-Deeplab [36],它使用掩码转换器以端到端的方式解决全景分割问题。在分段转换器(SETR) [43]中,转换器用作编码器,输入一系列图像块,转换网络用作解码器,从而产生强大的分段模型。
在医学图像分割中,基于变压器的模型还没有得到很好的研究。最接近的作品是那些使用注意力机制来提高性能的作品[29,20,39]。然而,这些网络的编码器和解码器仍然以卷积层作为主要构件。最近,TransUNet [3]被提出,它使用基于变压器的编码器对图像块序列进行操作,并使用具有跳跃连接的卷积解码器进行医学图像分割。由于TransUNet受到ViT的启发,它仍然依赖于通过在大型图像语料库上训练获得的预训练权重。与这些工作不同,我们探索了将仅在自我注意机制上工作的变压器作为医学图像分割编码器的可行性,而不需要任何预训练。
我们观察到,基于变压器的模型只有在大规模数据集上训练时才能很好地工作[7]。当采用用于医学成像任务的变形器时,这变得有问题,因为在任何医学数据集中可用于训练的具有相应标签的图像数量相对稀少。贴标过程也很昂贵,需要专家知识。具体而言,用较少的图像进行训练导致难以学习图像的位置编码。为此,我们提出了一种门控位置敏感轴向注意机制,其中我们引入了四个门来控制位置嵌入提供给键、查询和值的信息量。这些门是可学习的参数,使得所提出的机制适用于任何大小的任何数据集。根据数据集的大小,这些门将了解图像的数量是否足以学习正确的位置嵌入。基于通过位置嵌入学习的信息是否有用,门参数要么收敛到0,要么收敛到某个更高的值。此外,我们提出了一个局部-全局(LoGo)训练策略,其中我们使用一个浅的全局分支和一个深的局部分支来操作医学图像的补丁。这种策略提高了分割性能,因为我们不仅对整个图像进行操作,而且关注局部块中存在的更精细的细节。最后,我们提出了医用变压器(MedT),它使用我们的门控位置敏感轴向注意力作为构建模块,并采用我们的LoGo训练策略。
总之,本文(1)提出了一种门控位置敏感的轴向注意机制,该机制即使在较小的数据集上也能很好地工作,(2)介绍了针对变形器的局部-全局(LoGo)训练方法,该方法是有效的,(3)提出了医学变形器(Medical-Transformer,Medical),该方法是基于上述两个专门为医学图像分割提出的概念构建的,(4)成功地提高了医学图像分割任务在卷积网络和三个不同数据集上的完全注意架构上的性能。
2.Method
2.1 Medical Transformer (MedT)
医用变压器(MedT)使用门控轴向注意层作为基本构件,并使用LoGo策略进行训练。MedT有两个分支机构——全局分支机构和本地分支机构。这两个分支的输入是从初始conv块提取的特征图。该模块有3个conv层,每个层后面都有一个批处理规范化和ReLU激活。在两个分支的编码器中,我们使用我们提出的变换层,而在解码器中,我们使用conv块。编码器瓶颈包含一个1 × 1 conv层,随后是归一化和两层多头关注层,其中一层沿高度轴运行,另一层沿宽度轴运行。每个多头注意块由建议的门控轴向注意层组成。请注意,每个多头注意力模块有8个门控轴向注意力头。来自多头注意力块的输出被连接并通过另一个1×1 conv,该另一个1×1被添加到剩余输入图以产生输出注意力图。图2 (b)给出了建议的编码器块的概述。在每个解码器块中,我们有一个conv层,后跟一个上采样层和ReLU激活。我们还在两个分支中的每个编码器和解码器块之间建立了跳跃连接。
在MedT的全局分支中,我们有2个编码器块和2个解码器块。在本地分支中,我们有5个编码器块和5个解码器块。这些数字是根据实验分析确定的,在评估研究期间没有改变,这可以在补充文件中找到。MedT的整体架构如图2 (a)所示。接下来,我们将详细讨论MedT的每个组件。
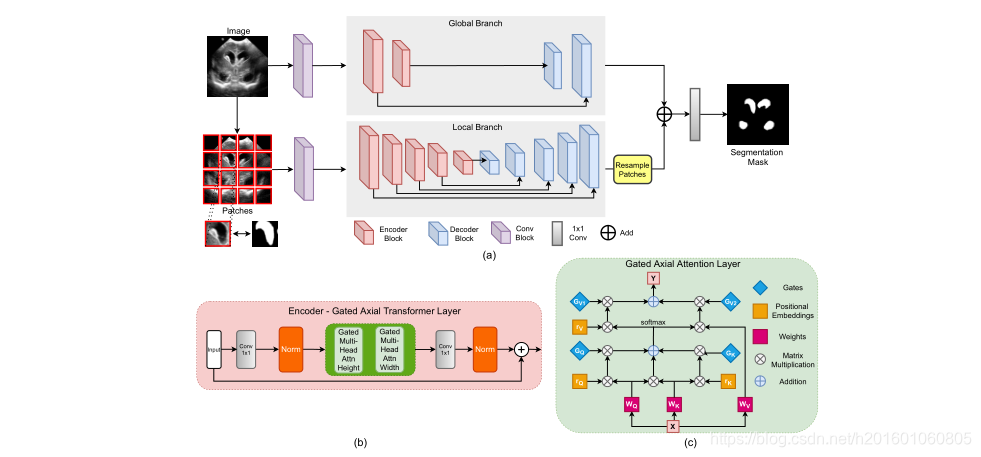
图2。(a)使用LoGo策略进行培训的MedT的主要架构图。(b)用于MedT的门控轴向变压器层。©门控轴向注意层是门控轴向变压器层中的高度和宽度门控多头注意块的基本构建块。
2.2 Self-Attention Overview