之前写过一篇《CUDA C Programming Guide》(《CUDA C 编程指南》)导读,整理了一下基础的知识,但没有真正实践过
最近由于工作需要使用到CUDA,因此需要再看一些书和博文,补一些知识。现将这些知识陈列在这里。
参考内容:
CUDA 基础知识博客整理
CUDA错误码打印
char
cuda所有kernel启动都是异步的
cudaMemcpy从设备端拷贝回主机端时,会触发一个隐式同步
cuda函数修饰符:

如果被定义为__global
_
_,则会生成主机端和设备端两段代码
Kernel核函数编写有以下限制
- 只能访问设备内存
- 必须有void返回类型
- 不支持可变数量的参数
- 不支持静态变量
- 显示异步行为
调试时,可以先把kernel配置成单线程执行
MyKernel<<<1,1>>>(参数)
使用nvprof可进行计时
需要sudo权限(当然注意sudo和普通用户路径差异的问题)
cudaMalloc占用的时间很长,显存分配好后尽量重复应用
查询设备信息
nvidia-smi -q // 可以查询所有信息当然也可以用API函数查
一篇绝赞好文章:【CUDA 基础】3.1 CUDA执行模型概述
讲了各个架构的硬件模型,有很多好内容、好图,对理解NVIDIA硬件很有帮助
线程束的一种分类方式
线程束
-
被调度到SM上
-
选定的线程束
- active的线程束(满足分支条件)
- 不active的线程束
- 阻塞的线程束
- ready的线程束(所有资源均已就绪)
-
选定的线程束
- 未被调度到SM上(寄存器、共享内存、程序计数器不够了)
延迟有两种:算数延迟和内存延迟,后者远长于前者;两者均应想办法隐藏
nvprof检测活跃的线程束
nvprof --metrics achieved_occupancy ./program检测出来的是活跃线程束的比例,即每个周期活跃的线程束的平均值与一个sm支持的线程束最大值的比
nvprof检测内存性能
nvprof --metrics gld_throughput ./simple_sum_matrix
nvprof --metrics gld_efficiency ./simple_sum_matrix
动态并行与嵌套执行
等到执行的时候再配置创建多少个网格,多少个块,这样就可以动态的利用GPU硬件调度器和加载平衡器了,通过动态调整,来适应负载。
嵌套执行是内核调内核,涉及到一些隐式同步的问题,比较麻烦
父网格(父内核)调用子网格(子内核)的一种比较好的方式是:
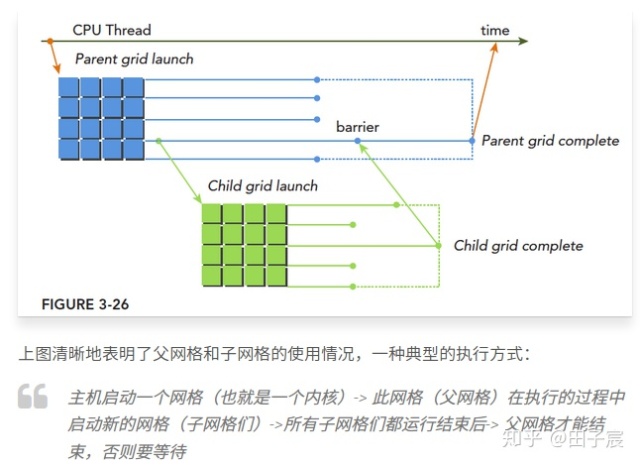
CUDA Kernel中定长数组也是放在寄存器里的
本地内存(Local Memory)
编译器可能将如下三种数据放在本地内存:
- 使用未知索引引用的本地数组
- 可能会占用大量寄存器空间的较大本地数组或者结构体
- 任何不满足核函数寄存器限定条件的变量
对于2.0以上的设备,本地内存存储在每个SM的一级缓存,或者设备的二级缓存上。而不再是全局内存上。
设置共享内存和L1 Cache的比例
cudaError_t cudaFuncSetCacheConfig(const void * func,enum cudaFuncCache);
cudaFuncCachePreferNone//无参考值,默认设置
cudaFuncCachePreferShared//48k共享内存,16k一级缓存
cudaFuncCachePreferL1// 48k一级缓存,16k共享内存
cudaFuncCachePreferEqual// 32k一级缓存,32k共享内存
常量内存
每个SM都有自己专属的常量内存cache,大小为64KB
常量内存有广播的特性,即可以将一块内存的数据一次性给一个线程束;因此类似于多项式系数等变量最好放到常量内存里
常量内存的最优访问方式是所有线程访问同一个数据
__constant__ // 全局可见,生命周期为整个程序运行期间,所有线程网格的所有线程均可见
cudaError_t cudaMemcpyToSymbol(const void* symbol,const void *src,size_t count); // 只有主机端可以修改,同步
全局内存
动态声明:cudaMalloc,用cudaMemcpy拷贝
静态声明:__device__,可以放到kernel内部,也可以放到外部声明为全局的
可以在设备端直接赋值;但由于主机端不能直接访问全局内存,需要使用cudaMemcpyToSymbol/cudaMemcpyFromSymbol来操作,这点和动态声明不同
与CPU不同的是,CPU读写过程都有可能被缓存,但是GPU写的过程不被缓存,只有加载会被缓存!
CUDA变量总结