FPN for Object Detection
参考
图像金字塔,通常用高斯金字塔

图像中存在不同尺寸的目标,而不同的目标具有不同的特征,利用浅层的特征就可以将简单的目标的区分开来;利用深层的特征可以将复杂的目标区分开来。
在第1层(请看绿色标注)输出
较大目标
的实例分割结果,在第2层输出
次大目标
的实例检测结果,在第3层输出
较小
目标的实例分割结果

在这个图中,特征图用蓝色的轮廓表示,较粗的轮廓表示语义上更强的特征。
(a)
使用图像金字塔来构建特征金字塔。在图像金字塔的每一层提出不同的特征,然后进行相应的预测(BB的位置),计算缓慢的,精度较好
(b)
最近的检测系统选择只使用单一尺度的特征来进行更快的检测。进行
卷积池化
获得不同尺寸的feature map,类似于在图像的特征空间中构造金字塔。浅层的网络更关注于细节信息,高层的网络更关注于语义信息,而高层的语义信息能够帮助我们准确的检测出目标,因此我们可以
利用最后一个卷积层上的feature map来进行预测
,但却忽略了其它层的特征
(c)
另一种方法是重用由ConvNet计算的金字塔特征层次结构,分别在
不同的特征层上面进行预测
,
优点
是在不同的层上面输出对应的目标,
不需要经过所有的层
才输出对应的目标,
缺点
是获得的
特征不鲁棒
,都是一些弱特征(因为很多的特征都是从较浅的层获得的)
(d)
我们提出的特征金字塔网络(FPN)很快,就像(b)和©一样,但更准确。
然后对
Layer2
上面的特征进行
降维操作
(即添加一层1×1的卷积层)。layer4是layer3进过1×1卷积降维的结果。对Layer4
上面
的特征就行
上采样
操作,使得2和处理后的4具有
相应的尺寸
,然后对处理后的
Layer2
和处理后的
Layer4
执行
加法
操作(对应元素相加),将获得的结果
输入到Layer5
中去。
456三层后面跟上分类器和回归。
具体解析:
从底向上:
先输入的图像送入特征网络,如ResNets,计算一个由多个尺度上的特征映射组成的特征层次结构(其实就是不同尺度的图像,提取特征后构成的特征金字塔),每层尺度步骤为2。我们选择每个阶段的
最后一层
的输出作为我们的参考的 feature maps。也就是使用最后一个残差块的特征输出,当做conv2, conv3, conv4, and conv5,它们相对于输入图像的步长为{4、8、16、32}像素
自上而下的路径和横向连接。
从顶向下的路径通过上采样更高金字塔水平的特征图。
每个横向连接都合并了来自自下而上路径和自上而下路径的相同空间大小的特征图。
第二版:
来源

1)Backbone生成特征阶段
计算机视觉任务一般都是基于常用预训练的Backbone,生成抽象的语义特征,再进行特定任务微调。物体检测也是如此。
Backbone生成的特征,一般按stage划分,分别记作C1、C2、C3、C4、C5、C6、C7等,其中的数字与stage的编号相同,代表的是分辨率减半的次数,如C2代表stage2输出的特征图,分辨率为输入图片的1/4,C5代表,stage5输出的特征图,分辨率为输入图片的1/32。
2)特征融合阶段
这个是FPN特有的阶段,FPN一般将上一步生成的不同分辨率特征作为输入,输出经过融合后的特征。输出的特征一般以P作为编号标记。如FPN的输入是,C2、C3、C4、C5、C6,经过融合后,输出为P2、P3、P4、P5、P6。这个过程可以用数学公式表达:
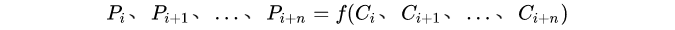
3)检测头输出bounding box
FPN输出融合后的特征后,就可以输入到检测头做具体的物体检测。

插眼Recursive-FPN(递归FPN)
使用递归FPN的DetectoRS是目前物体检测(COCO mAP 54.7)、实体分割和全景分割的SOTA
https://arxiv.org/abs/2006.02334
个人学习记录,侵删