title: Flink系列
一、Flink Window 概述
官网链接:
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/datastream/operators/windows/
摘取一段话:
Windows are at the heart of processing infinite streams. Windows split the stream into “buckets” of finite size, over which we can apply computations. This document focuses on how windowing is performed in Flink and how the programmer can benefit to the maximum from its offered functionality.
聚合事件(比如计数、求和、求最值)在流上的工作方式与批处理不同。比如,对流中的所有元素进行计数是不可能的,因为通常流是无限的(无界的)。所以,流上的聚合需要由 window 来划定范围,比如 “
计算过去的5分钟
” ,或者 “
最后100个元素的和
” 。window 是一种可以把无限数据切割为有限数据块的手段。
-
每隔 1个小时 做一次统计
-
每接收到 500 条数据就做一次计算
窗口可以是 时间驱动的 【Time Window】(比如:每30秒)或者 数据驱动的【Count Window】 (比如:每100个元素)
图片:
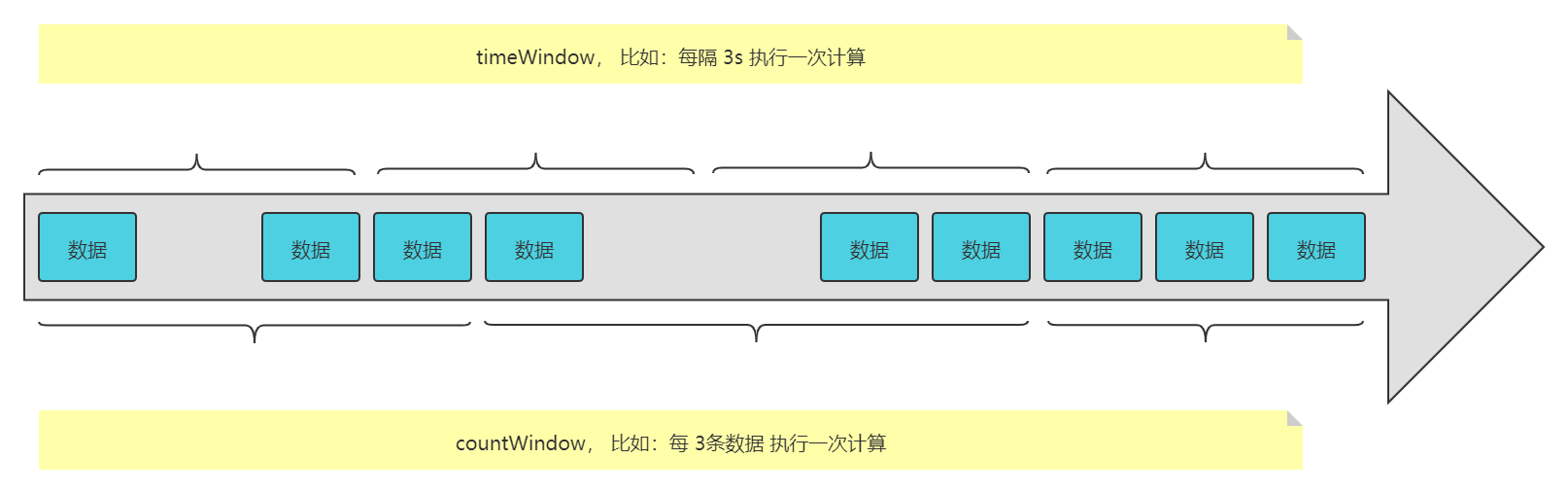
Flink 的 window 分为两种类型的 Window,分别是:Keyed Windows 和 Non-Keyed Windows,他们的使用方式不同:
Keyed Windows:
stream
.keyBy(...) <- keyed versus non-keyed windows
.window(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (else default trigger)
[.evictor(...)] <- optional: "evictor" (else no evictor)
[.allowedLateness(...)] <- optional: "lateness" (else zero)
[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/apply() <- required: "function"
[.getSideOutput(...)] <- optional: "output tag"
Non-Keyed Windows:
stream
.windowAll(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (else default trigger)
[.evictor(...)] <- optional: "evictor" (else no evictor)
[.allowedLateness(...)] <- optional: "lateness" (else zero)
[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/apply() <- required: "function"
[.getSideOutput(...)] <- optional: "output tag"
关于 Window 的生命周期,官网有比较详细的描述,有以下几点:
01、当属于某个窗口的第一个元素到达的时候,就会创建一个窗口
02、当时间(event or processing time)超过 window 的结束时间戳加上用户指定的允许延迟(Allowed Lateness)时,窗口将被完全删除。
03、每个 Window 之上,都绑定有一个 Trigger 或者一个 Function(ProcessWindowFunction, ReduceFunction, or AggregateFunction)用来执行窗口内数据的计算。
04、可以给 Window 指定一个 Evictor,它能够在 after the trigger fires 以及 before and/or after the function is applied 从窗口中删除元素。
每隔 2 分钟,执行过去 5 分钟内的数据的计算,是有3分钟的重复的数据的。
20:10:00 【20:05:00 - 20:10:00】
20:12:00 【20:07:00 - 20:12:00】 和上一个窗口的共同部分:20:07:00 - 20:10:00, 删除 【20:07:00 - 20:09:00】
20:14:00 【20:09:00 - 20:14:00】 和上一个窗口的共同部分:20:09:00 - 20:12:00, 删除 【20:09:00 - 20:11:00】
二、Flink Window 类型
窗口通常被区分为不同的类型: 按照计算需求做分类:
tumbling windows:滚动窗口 【没有重叠】
sliding windows:滑动窗口 【有重叠】
session windows:会话窗口
global windows: 全局窗口,没有窗口
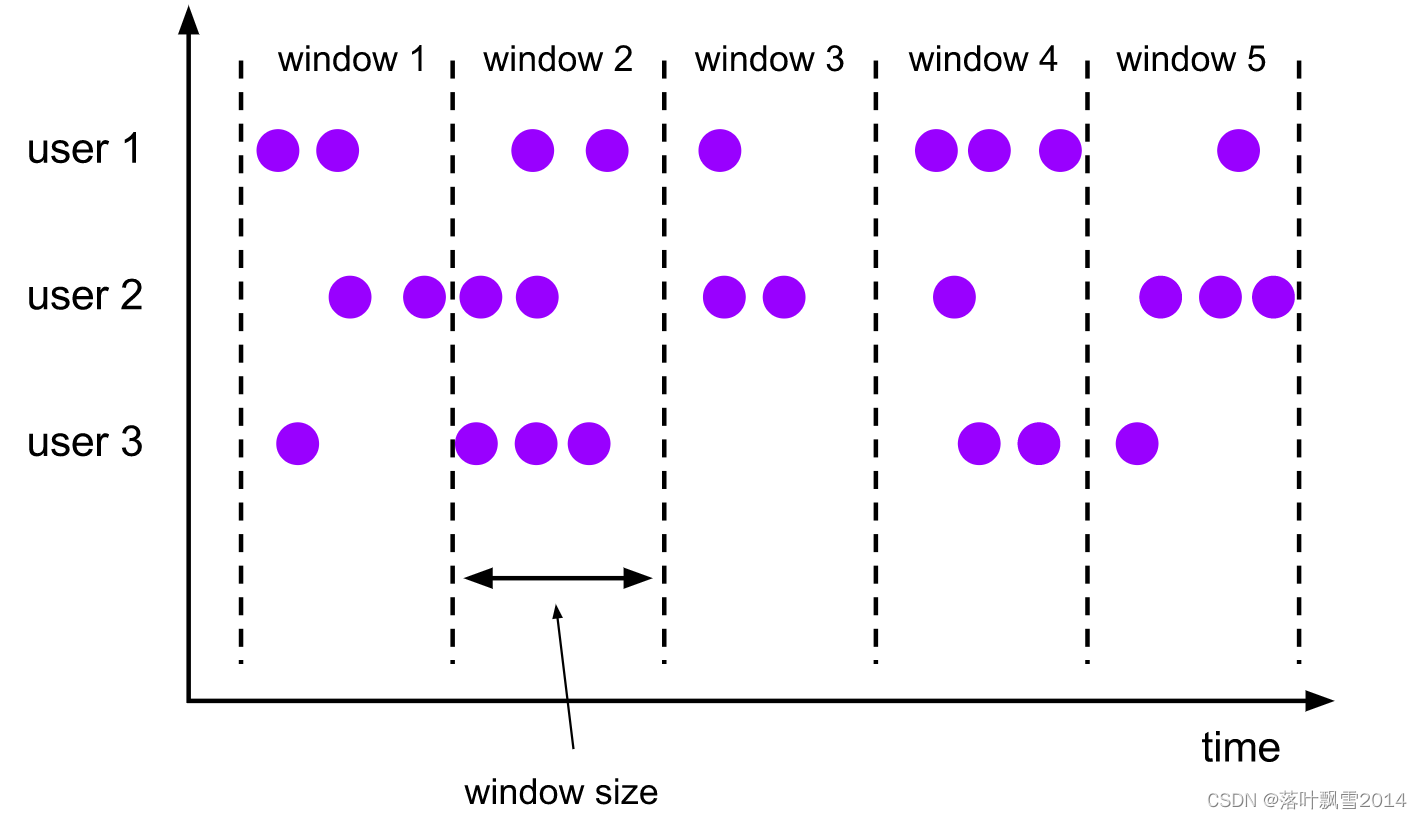
2.1 tumblingwindows:滚动窗口(没有重叠)
A tumbling windows assigner assigns each element to a window of a specified window size. Tumbling windows have a fixed size and do not overlap. For example, if you specify a tumbling window with a size of 5 minutes, the current window will be evaluated and a new window will be started every five minutes as illustrated by the following figure.
{% asset_img tumbling-windows.svg %}
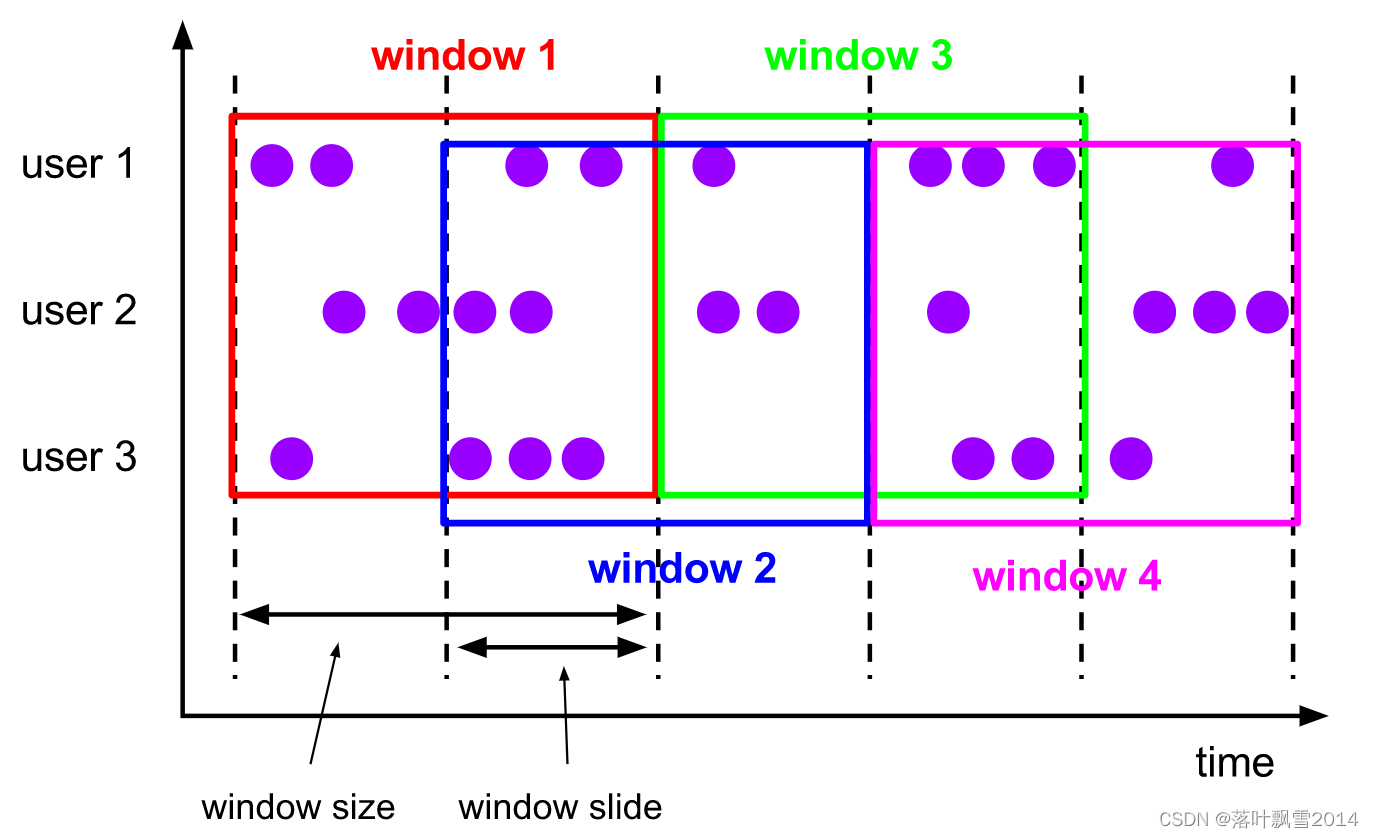
2.2 slidingwindows:滑动窗口(有重叠)
The sliding windows assigner assigns elements to windows of fixed length. Similar to a tumbling windows assigner, the size of the windows is configured by the window size parameter. An additional window slide parameter controls how frequently a sliding window is started. Hence, sliding windows can be overlapping if the slide is smaller than the window size. In this case elements are assigned to multiple windows.
For example, you could have windows of size 10 minutes that slides by 5 minutes. With this you get every 5 minutes a window that contains the events that arrived during the last 10 minutes as depicted by the following figure.
{% asset_img sliding-windows.svg %}
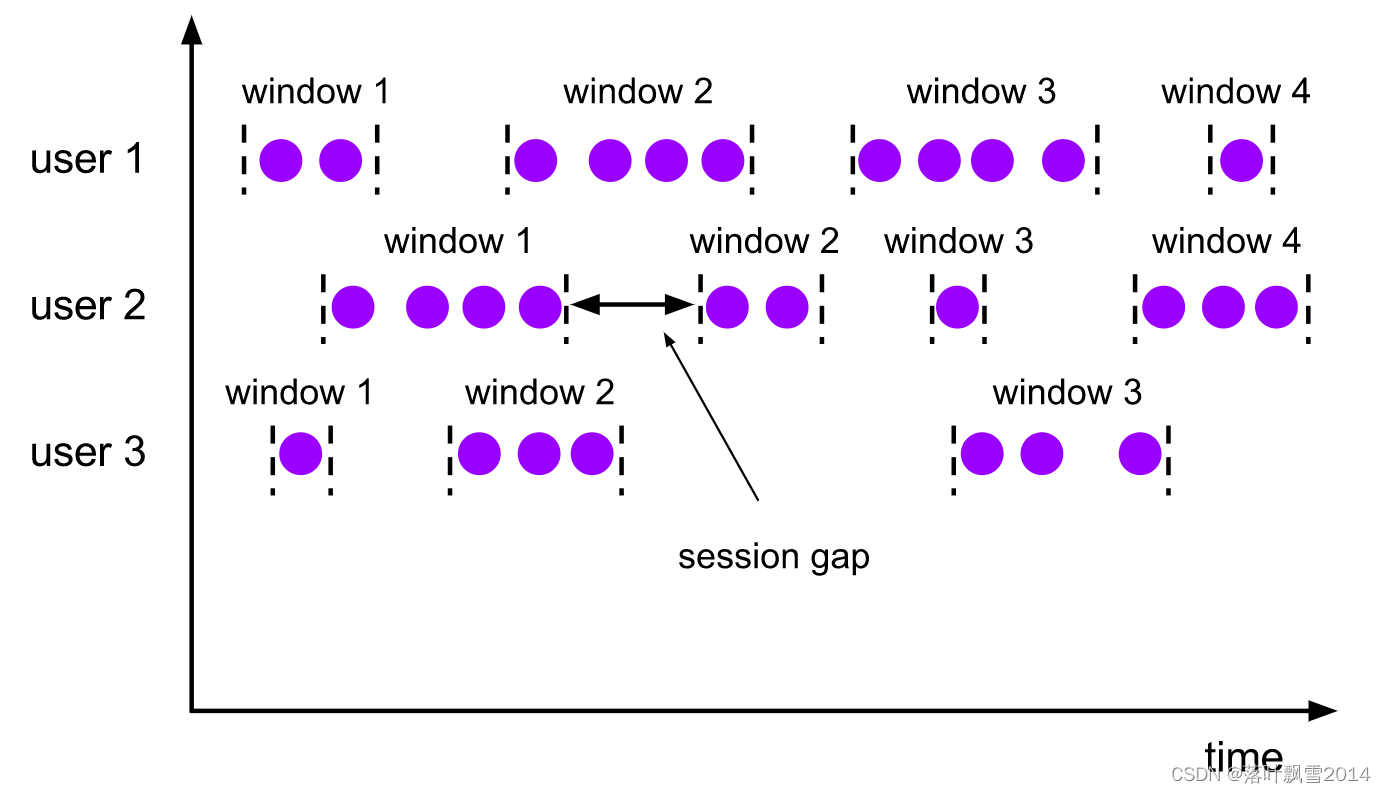
2.3 session windows
The session windows assigner groups elements by sessions of activity. Session windows do not overlap and do not have a fixed start and end time, in contrast to tumbling windows and sliding windows. Instead a session window closes when it does not receive elements for a certain period of time, i.e., when a gap of inactivity occurred. A session window assigner can be configured with either a static session gap or with a session gap extractor function which defines how long the period of inactivity is. When this period expires, the current session closes and subsequent elements are assigned to a new session window.
{% asset_img session-windows.svg %}
2.4 global windows
A global windows assigner assigns all elements with the same key to the same single global window. This windowing scheme is only useful if you also specify a custom trigger. Otherwise, no computation will be performed, as the global window does not have a natural end at which we could process the aggregated elements.
{% asset_img non-windowed.svg %}

2.5 Flink Window 类型总结
2.5.1 图片对比
图片对比:
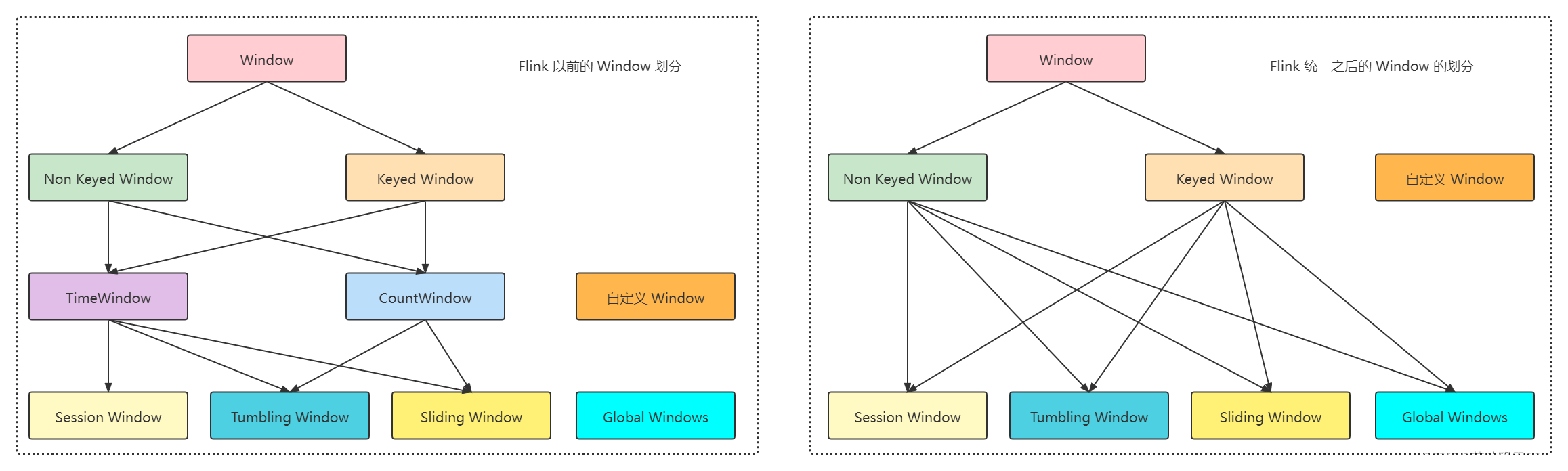
一般来说,绝大部分需求,使用 countWindow 和 timeWindow 就能解决需求了,稍微偏一点的需求才需要自定义 Window
// 老版本的使用方式
dataStream.timeWindow()
dataStream.countWindow()
// 新版本的使用方式,WindowAssigner 有常用的四个子类
dataStream.Window(WindowAssigner)
2.5.2 代码样例
1、Flink01_Old_CountWindow
package com.aa.flinkjava.window2;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @Author AA
* @Project bigdatapre
* @Package com.aa.flinkjava.window2
* 需求: 单词每出现三次统计一次
*
* CountWindow 的示例
*/
public class Flink01_Old_CountWindow {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> dataTextStream = executionEnvironment.socketTextStream("hadoop12", 9999);
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = dataTextStream.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] words = value.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1));
}
}
});
wordAndOne.keyBy(0)
//本案例的核心逻辑点。 每过来三条数据统计一次。
.countWindow(3)
.sum(1)
.print();
executionEnvironment.execute("Flink01_Old_CountWindow");
}
}
2、Flink02_Old_TimeWindow
package com.aa.flinkjava.window2;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
/**
* @Author AA
* @Project bigdatapre
* @Package com.aa.flinkjava.window2
* 需求:每3秒统计一次。
*/
public class Flink02_Old_TimeWindow {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
//老版本的这个必须设置一下,否则报错。
executionEnvironment.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
DataStreamSource<String> dataTextStream = executionEnvironment.socketTextStream("hadoop12", 9999);
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = dataTextStream.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] words = value.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1));
}
}
});
wordAndOne.keyBy(0)
//本案例的核心逻辑点。 每3秒钟统计一次。
.timeWindow(Time.seconds(3))
.sum(1)
.print();
executionEnvironment.execute("Flink02_Old_TimeWindow");
}
}
三、Flink Window 操作使用
3.1 Keyed Windows 和 Non-Keyed Windows
Keyed Windows 语法:
stream
.keyBy(...) <- keyed versus non-keyed windows
.window(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (else default trigger)
[.evictor(...)] <- optional: "evictor" (else no evictor)
[.allowedLateness(...)] <- optional: "lateness" (else zero)
[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/apply() <- required: "function"
[.getSideOutput(...)] <- optional: "output tag"
Non-Keyed Windows 语法:
stream
.windowAll(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (else default trigger)
[.evictor(...)] <- optional: "evictor" (else no evictor)
[.allowedLateness(...)] <- optional: "lateness" (else zero)
[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/apply() <- required: "function"
[.getSideOutput(...)] <- optional: "output tag"
3.2 Fink Window Function
3.2.1 Tumbling window 和 sliding window
演示程序:
wordAndOne.keyBy(0)
//基于 EventTime 每隔5s 做一次计算
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.sum(1)
.print();
wordAndOne.keyBy(0)
// 每间隔 2 秒 ,计算过去4秒的数据
.window(SlidingProcessingTimeWindows.of(Time.seconds(4),Time.seconds(2)))
.sum(1)
.print();
3.2.2 Session Window
1、小需求
一个需求
实时计算单词出现的次数,但是并不是每次接受到单词以后就输出单词出现的次数,而是当过了 5秒 以后没收到这个单词,就输出这个单词的次数
扩展:
思考一下,假设没有 session window ,有什么方式可以实现呢?Flink State 编程 + 定时器
解决问题的思路:
01、利用 state 存储 key,count 和 key 到达的时间, 定义一个 POJO 实体对象来保存这三个信息,然后通过一个 ValueState 来维护这个状态。
02、每接收到一个单词,更新状态中的数据。
03、对于每个 key 都注册一个【定时器】,如果过了 5秒 没接收到这个 key 的话,那么就触发这个定时器,这个定时器就判断当前的 time 是否等于这个 key 的最后修改时间 + 5s,如果等于则输出 key 以及对应的 count 。
2、SessionWindow实现
发现如果使用这样的方式来实现这个需求,还挺复杂的,其实Flink 给我们提供了专门的 window API 可以非常快速方便的进行求解
package com.aa.flinkjava.window2;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.ProcessingTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
/**
* @Author AA
* @Project bigdatapre
* @Package com.aa.flinkjava.window2
*/
public class Flink04_WordCount_SessionWindow {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> dataTextStream = executionEnvironment.socketTextStream("hadoop12", 9999);
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = dataTextStream.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] words = value.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1));
}
}
});
wordAndOne.keyBy(0)
//wordAndOne.keyBy(tuple -> tuple.f0)
//本案例的核心逻辑点。 使用 SessionWindow 。5秒没有再次接受到数据的话,就执行计算。
.window(ProcessingTimeSessionWindows.withGap(Time.seconds(5)))
.sum(1)
.print();
executionEnvironment.execute("Flink04_WordCount_SessionWindow");
}
}
3.2.3 Global window
Global window + Trigger 一起配合才能使用
需求:单词每出现三次统计一次
package com.aa.flinkjava.window2;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.GlobalWindows;
import org.apache.flink.streaming.api.windowing.assigners.ProcessingTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.triggers.CountTrigger;
import org.apache.flink.streaming.api.windowing.triggers.EventTimeTrigger;
import org.apache.flink.util.Collector;
/**
* @Author AA
* @Project bigdatapre
* @Package com.aa.flinkjava.window2
* GlobalWindow 的测试
*/
public class Flink05_WordCount_GlobalWindow {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> dataTextStream = executionEnvironment.socketTextStream("hadoop12", 9999);
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = dataTextStream.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] words = value.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1));
}
}
});
wordAndOne.keyBy(0)
//wordAndOne.keyBy(tuple -> tuple.f0)
//本案例的核心逻辑点。 指定使用
.window(GlobalWindows.create())
//调用定义的trigger。每间隔3条元素执行一次计算。CountTrigger 是flink提供的常用实现
.trigger(CountTrigger.of(3))
.sum(1)
.print();
executionEnvironment.execute("Flink05_WordCount_GlobalWindow");
}
}
总结:效果跟 CountWindow(3)很像,但又有点不像,因为如果是 CountWindow(3),单词每次出现的都是 3 次,不会包含之前的次数,而我们刚刚的这个每次都包含了之前的次数。
3.3 Flink Window Trigger
需求:自定义一个 CountWindow:使用 Trigger 自己实现一个类似 CountWindow 的效果
CountWindow:Count 的滚动窗口: 每隔多少条数据执行一次计算。
package com.aa.flinkjava.window2;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.common.state.ReducingState;
import org.apache.flink.api.common.state.ReducingStateDescriptor;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.GlobalWindows;
import org.apache.flink.streaming.api.windowing.triggers.CountTrigger;
import org.apache.flink.streaming.api.windowing.triggers.Trigger;
import org.apache.flink.streaming.api.windowing.triggers.TriggerResult;
import org.apache.flink.streaming.api.windowing.windows.GlobalWindow;
import org.apache.flink.util.Collector;
/**
* @Author AA
* @Project bigdatapre
* @Package com.aa.flinkjava.window2
*
* 需求: 通过自定义的Trigger的方式,实现CountWindow的效果。
*/
public class Flink06_WordCount_ByUDTrigger {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> dataTextStream = executionEnvironment.socketTextStream("hadoop12", 9999);
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = dataTextStream.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] words = value.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1));
}
}
});
wordAndOne.keyBy(0)
//wordAndOne.keyBy(tuple -> tuple.f0)
//本案例的核心逻辑点。 指定使用 GlobalWindows
.window(GlobalWindows.create())
//Trigger是一个抽象类 。 CountTrigger 是flink提供的常用实现 。
//自己自定义的trigger 。比如说还是实现 计算逻辑是:每间隔 3 条元素执行一次计算 。 只不过这个计算逻辑是自己写的代码。
.trigger(new MyCountTrigger(3))
.sum(1)
.print();
executionEnvironment.execute("Flink06_WordCount_ByUDTrigger");
}
/**
* 自定义触发器,每3个元素触发一次
* Tuple2<String,Integer> 输入数据的类型
* GlobalWindow 窗口的数据类型
* 里面有四个抽象的方法,需要去实现: 其中 onElement 表示每次接收到这个window的输入,就调用一次。
*/
static class MyCountTrigger extends Trigger<Tuple2<String, Integer>, GlobalWindow> {
//表示指定的元素的最大的数量
private long maxCount;
//用于存储每个key所对应的count的值
//一般情况下,当遇到复杂的需求的时候,一般都是使用 mapstate 和 liststate
private ReducingStateDescriptor<Long> stateDescriptor = new ReducingStateDescriptor<Long>("count",
new ReduceFunction<Long>() {
@Override
public Long reduce(Long v1, Long v2) throws Exception {
return v1 + v2;
}
}, Long.class
);
//定义一个有参构造器
public MyCountTrigger(long maxCount) {
this.maxCount = maxCount;
}
/**
* 当一个元素进入到window的时候就会调用这个方法
* @param element 元素
* @param timestamp 进来的时间点
* @param window 元素所属的窗口
* @param ctx 上下文对象
* @return TriggerResult 有四种结果: 点击到源码中,可以看到有四种
* TriggerResult.CONTINUE: 表示对的window不做任何处理
* TriggerResult.FIRE_AND_PURGE: 先触发window计算,然后删除window中的数据
* TriggerResult.FIRE: 表示触发window的计算
* TriggerResult.PURGE: 表示清空window中的数据
*
* @throws Exception
*/
@Override
public TriggerResult onElement(Tuple2<String, Integer> element, long timestamp, GlobalWindow window, TriggerContext ctx) throws Exception {
//拿到当前的key对应的count的状态的值, 并累加
ReducingState<Long> count = ctx.getPartitionedState(stateDescriptor);
count.add(1L);
//下面是业务逻辑判断了,当单词的个数到了3个的时候输出
if (count.get() == maxCount){
//清空状态个数
count.clear();
//先触发计算,然后删除窗口内的数据
return TriggerResult.FIRE_AND_PURGE;
}else {
return TriggerResult.CONTINUE;
}
}
//一般也不用定时器,这个方法里面不用写逻辑了。
@Override
public TriggerResult onProcessingTime(long time, GlobalWindow window, TriggerContext ctx) throws Exception {
return null;
}
//一般也不用定时器,这个方法里面不用写逻辑了。
@Override
public TriggerResult onEventTime(long time, GlobalWindow window, TriggerContext ctx) throws Exception {
return null;
}
//这个里面清楚状态的值。
@Override
public void clear(GlobalWindow window, TriggerContext ctx) throws Exception {
ctx.getPartitionedState(stateDescriptor).clear();
}
}
}
经过测试,其实最终的效果和 CountWindow 是一样的。
3.4 Flink Window Evictor
需求:实现每隔 2 个单词,计算最近 3 个单词。类似于使用 Evictor 自己实现一个类似 CountWindow(3,2) 的效果
直接看代码: com.aa.flinkjava.window2.Flink07_WordCount_ByUDEvictor
3.5 Flink Window 增量聚合
Flink Window 增量聚合:窗口中每进入一条数据,就进行一次计算,等窗口结束时间到了,就输出最后的结果
常用的聚合算子:
1、reduce(ReduceFunction) 其实ReduceFunction 是 AggregateFunction 的一个特例
2、aggregate(AggregateFunction) AggregateFunction 是一个通用实现,代表聚合
3、sum(),min(),max() 其实sum(),min(),max() 是 reduce 的特例
下图的聚合逻辑:求和
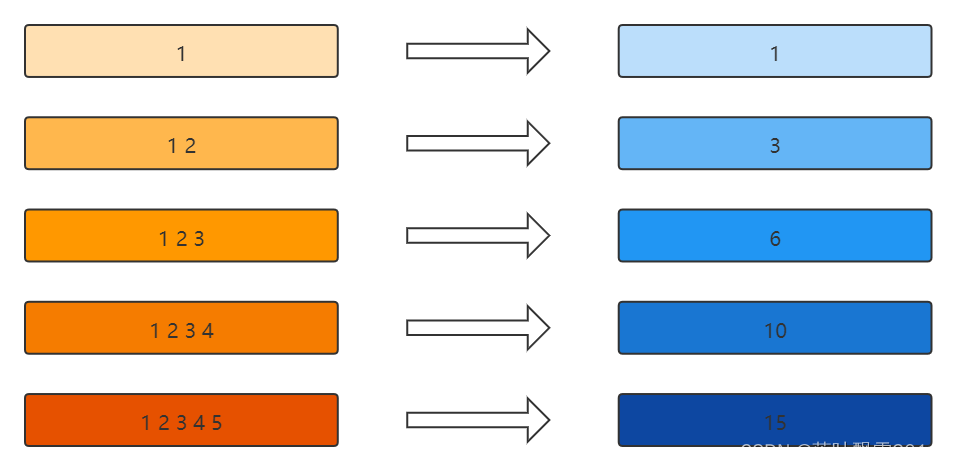
3.5.1 增量案例1
增量代码演示实现:
package com.aa.flinkjava.window2;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.AllWindowedStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
/**
* @Author AA
* @Date 2022/3/16 14:17
* @Project bigdatapre
* @Package com.aa.flinkjava.window2
*
* 增量聚合演示案例
*/
public class Flink08_ReduceFunction_Incremental {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> dataTextStream = executionEnvironment.socketTextStream("hadoop12", 9999);
//给传递的数据转化成为整数
SingleOutputStreamOperator<Integer> data1 = dataTextStream.map(number -> Integer.valueOf(number));
/**
* data2是一个元素是整型的数据流 。
*
* 统计的都是这一个窗口内的数据,可以给窗口 改 多点进行测试。
*/
AllWindowedStream<Integer, TimeWindow> data2 = data1.windowAll(TumblingProcessingTimeWindows.of(Time.seconds(3)));
/**
* ReduceFunction的参数泛型 就是输入的数据流的 数据的类型
* 增量聚合逻辑,窗口中每次进入一个元素,就调用reduce执行一次聚合
*/
SingleOutputStreamOperator<Integer> result = data2.reduce(new ReduceFunction<Integer>() {
/**
* @param value1 临时的累加的值
* @param value2 新过来的一条新值
* @return
* @throws Exception
*/
@Override
public Integer reduce(Integer value1, Integer value2) throws Exception {
System.out.println("value1: " + value1);
System.out.println("value2: " + value2);
return value1 + value2;
}
});
result.print();
executionEnvironment.execute(Flink08_ReduceFunction_Incremental.class.getSimpleName());
}
}
3.5.2 增量案例2
需求:求每隔窗口里面的数据的平均值
package com.aa.flinkjava.window2;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.AllWindowedStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
/**
* @Author AA
* @Date 2022/3/16 14:29
* @Project bigdatapre
* @Package com.aa.flinkjava.window2
*
* 需求: 自定义的 MyAggregateFunction 实现平均值
*/
public class Flink09_AggregateFunction_WindowAvg {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> dataTextStream = executionEnvironment.socketTextStream("hadoop12", 9999);
//给传递的数据转化成为整数
SingleOutputStreamOperator<Integer> data1 = dataTextStream.map(number -> Integer.valueOf(number));
/**
* data2是一个元素是整型的数据流 。
*/
AllWindowedStream<Integer, TimeWindow> data2 = data1.windowAll(TumblingProcessingTimeWindows.of(Time.seconds(5)));
/**
* 调用自定义的 MyAggregateFunction 实现平均值
*/
SingleOutputStreamOperator<Double> result = data2.aggregate(new MyAggregateFunction());
result.print();
executionEnvironment.execute(Flink09_AggregateFunction_WindowAvg.class.getSimpleName());
}
/**
* AggregateFunction<IN, ACC, OUT>
* Type parameters:
* <IN> – The type of the values that are aggregated (input values) 输入数据类型
* <ACC> – The type of the accumulator (intermediate aggregate state). 自定义的中间状态类型
* <OUT> – The type of the aggregated result 输出的数据类型
*/
static class MyAggregateFunction implements AggregateFunction<Integer, Tuple2<Integer,Integer>, Double>{
/**
* 初始化的累加器, 辅助变量
* @return
*/
@Override
public Tuple2<Integer, Integer> createAccumulator() {
return new Tuple2<>(0,0);
}
/**
* 针对于数据的计算
* 也就是聚合 临时的结果 + 新的一条数据
* @param value 新的数据
* @param accumulator 临时的中间的状态结果 泛型Tuple2<Integer, Integer> 中的第一个参数是元素个数,第二个是累加的结果值
* @return
*/
@Override
public Tuple2<Integer, Integer> add(Integer value, Tuple2<Integer, Integer> accumulator) {
return new Tuple2<>(accumulator.f0 + 1, accumulator.f1 + value);
}
/**
* 返回结果,获取最终的值
* @param accumulator
* @return
*/
@Override
public Double getResult(Tuple2<Integer, Integer> accumulator) {
return (double) accumulator.f1 / accumulator.f0;
}
/**
* 临时的结果进行合并
* @param a
* @param b
* @return
*/
@Override
public Tuple2<Integer, Integer> merge(Tuple2<Integer, Integer> a, Tuple2<Integer, Integer> b) {
return Tuple2.of(a.f0 + b.f0 ,a.f1 + b.f1);
}
}
}
3.6 Flink Window 全量聚合
Flink Window 全量聚合:等属于窗口的数据到齐,才开始进行聚合计算【可以实现对窗口内的数据进行排序等需求】
常用的聚合算子:
apply(WindowFunction)
process(ProcessWindowFunction)
ProcessWindowFunction 比 WindowFunction提供了更多的上下文信息。类似于 map 和 RichMap 的关系
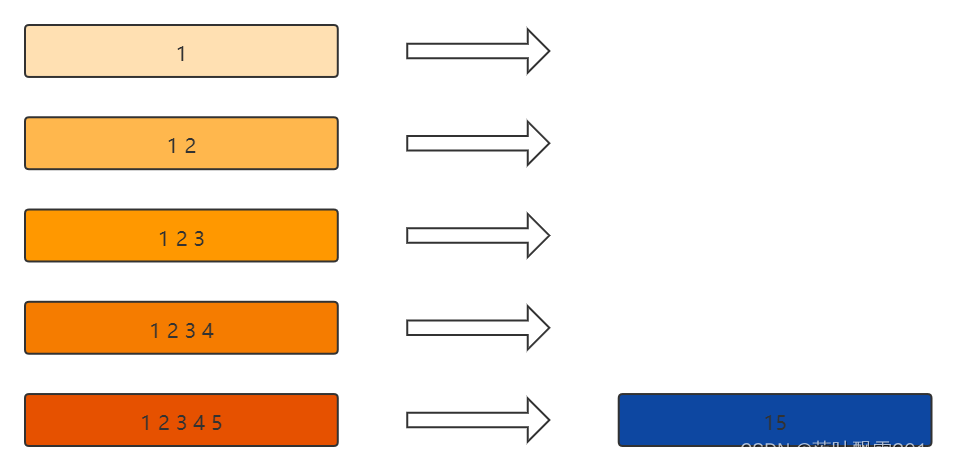
3.6.1 全量案例1
代码如下:
com.aa.flinkjava.window2.Flink10_AggregateFunction_Full
3.7 Flink Window Join
3.7.0 官网链接
官网链接:
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/dev/datastream/operators/joining/
两个 window 之间可以进行 join,join 操作只支持三种类型的 window:滚动窗口,滑动窗口,会话窗口
具体使用方式:
select a.*, b.* from a join b on a.id = b.id;
1、指定两张表
2、指定这两张表的链接字段
具体使用方式:
// 在 Flink 中对两个 DataStream 做 Join
// 1、指定两个流
// 2、指定这两个流的链接字段
stream.join(otherStream) //两个流进行关联
.where(<KeySelector>) //选择第一个流的key作为关联字段
.equalTo(<KeySelector>) //选择第二个流的key作为关联字段
.window(<WindowAssigner>) //设置窗口的类型
.apply(<JoinFunction>) //对结果做操作 process处理 apply 类似于 foreach
重点理解清楚这个语法即可!
3.7.1 Tumbling Window Join
When performing a tumbling window join, all elements with a common key and a common tumbling window are joined as pairwise combinations and passed on to a JoinFunction or FlatJoinFunction. Because this behaves like an inner join, elements of one stream that do not have elements from another stream in their tumbling window are not emitted!
{% asset_img tumbling-window-join.svg %}
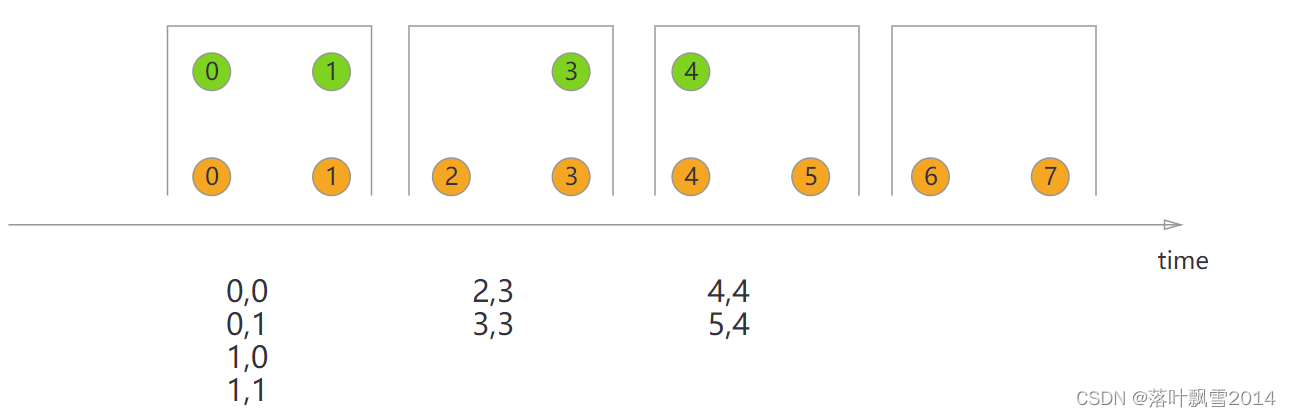
核心代码:
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
...
DataStream<Integer> orangeStream = ...
DataStream<Integer> greenStream = ...
orangeStream.join(greenStream)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(TumblingEventTimeWindows.of(Time.milliseconds(2)))
.apply (new JoinFunction<Integer, Integer, String> (){
@Override
public String join(Integer first, Integer second) {
return first + "," + second;
}
});
3.7.2 Sliding Window Join
When performing a sliding window join, all elements with a common key and common sliding window are joined as pairwise combinations and passed on to the JoinFunction or FlatJoinFunction. Elements of one stream that do not have elements from the other stream in the current sliding window are not emitted! Note that some elements might be joined in one sliding window but not in another!
{% asset_img sliding-window-join.svg %}
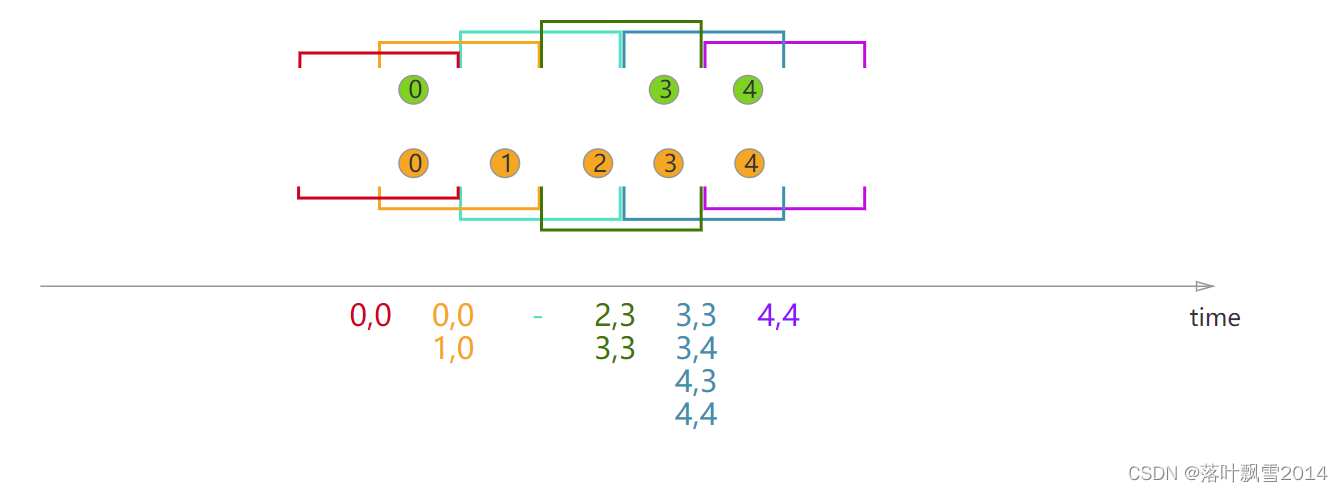
核心代码:
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
...
DataStream<Integer> orangeStream = ...
DataStream<Integer> greenStream = ...
orangeStream.join(greenStream)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(SlidingEventTimeWindows.of(Time.milliseconds(2) /* size */, Time.milliseconds(1) /* slide */))
.apply (new JoinFunction<Integer, Integer, String> (){
@Override
public String join(Integer first, Integer second) {
return first + "," + second;
}
});
3.7.3 Session Window Join
When performing a session window join, all elements with the same key that when “combined” fulfill the session criteria are joined in pairwise combinations and passed on to the JoinFunction or FlatJoinFunction. Again this performs an inner join, so if there is a session window that only contains elements from one stream, no output will be emitted!
{% asset_img session-window-join.svg %}
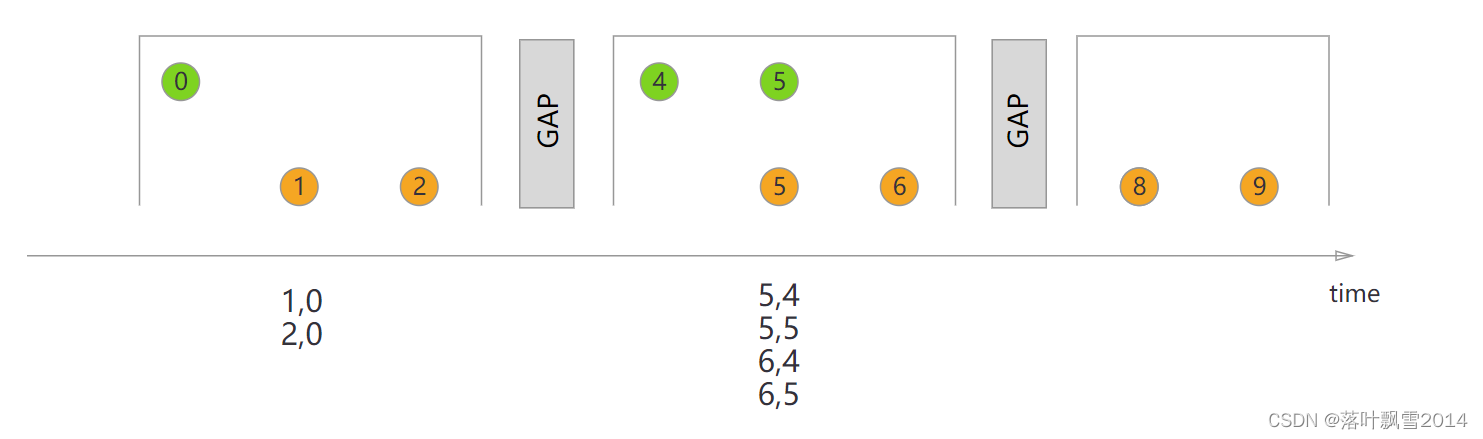
核心代码:
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.windowing.assigners.EventTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
...
DataStream<Integer> orangeStream = ...
DataStream<Integer> greenStream = ...
orangeStream.join(greenStream)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(EventTimeSessionWindows.withGap(Time.milliseconds(1)))
.apply (new JoinFunction<Integer, Integer, String> (){
@Override
public String join(Integer first, Integer second) {
return first + "," + second;
}
});
3.7.4 Interval Join
{% asset_img interval-join.svg %}
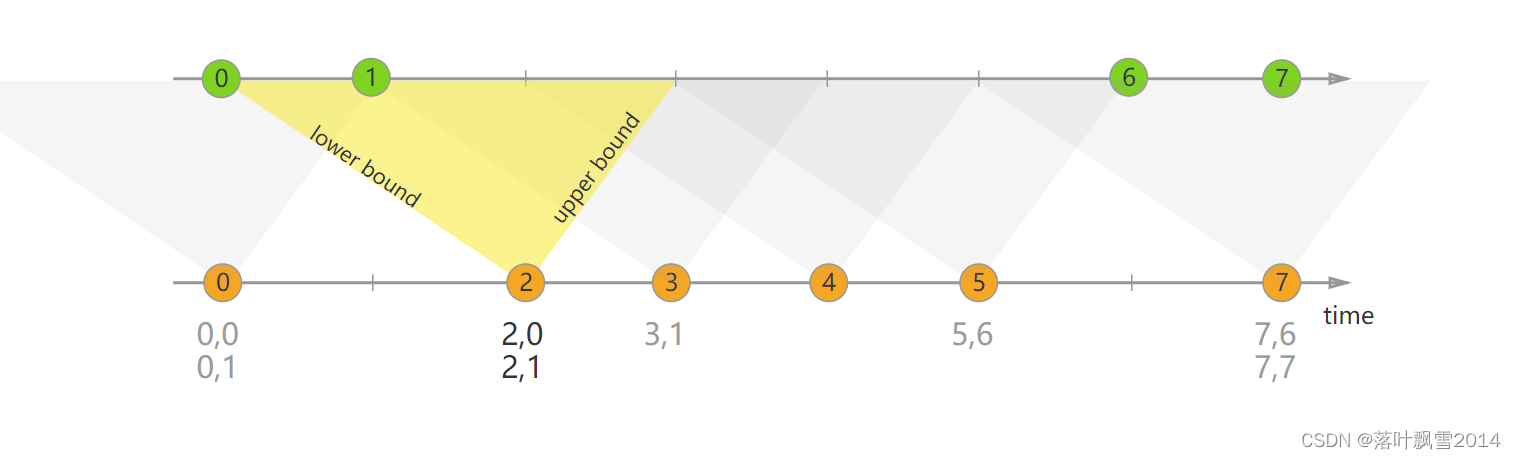
核心代码:
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.functions.co.ProcessJoinFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
...
DataStream<Integer> orangeStream = ...
DataStream<Integer> greenStream = ...
orangeStream
.keyBy(<KeySelector>)
.intervalJoin(greenStream.keyBy(<KeySelector>))
.between(Time.milliseconds(-2), Time.milliseconds(1))
.process (new ProcessJoinFunction<Integer, Integer, String(){
@Override
public void processElement(Integer left, Integer right, Context ctx, Collector<String> out) {
out.collect(first + "," + second);
}
});
小总结:
Flink 的容错: state checkpoint savepoint statebackend restartStrategy failoverstartergy
Flink 处理乱序数据:Window + Time + Watermark
Flink Window 详细使用:定义window(WindowAssigner + Trigger + Evictor) + 定义window的计算逻辑:reduce / aggregate / process / apply
在企业环境中,一般情况下,使用 Flink 实现需求,就是要通过以上这些技能来完成就行了。其实还差一个技能:部署 Application 的时候,需要指定资源。需要搞清楚 Task 运行的时候内存使用。其实也就是Flink 的内存模型。
声明:
文章中代码及相关语句为自己根据相应理解编写,文章中出现的相关图片为自己实践中的截图和相关技术对应的图片,若有相关异议,请联系删除。感谢。转载请注明出处,感谢。
By luoyepiaoxue2014
B站: https://space.bilibili.com/1523287361
点击打开链接
微博地址: http://weibo.com/luoyepiaoxue2014
点击打开链接