分布式深度学习
.深度学习的问题:数据量大,网络模型大,训练时间太长。
解决办法:
| 1.采用高性能硬件,图形处理单元(graphics processing unit)和张量处理器(TPU)加速模型训练 |
|---|
|
2. 分布式训练:在多个节点上并行训练深度神经网络也是行之有效的加速方法。每个节点仅仅执行整体计算任务的一部分,这样可以大幅缩短深度神经网络的训练时间 |
1.分布式学习基本概念
1.1 并行化训练任务的哪一部分?
| 分布式种类 | 问题 | 原因 |
|---|---|---|
| 数据并行 (主流) | 节点间的通信开销 | 网络模型训练过程的迭代性,不同的计算节点之间往往需要频繁地进行通信以交换大量的数据,这就导致节点间的通信成为分布式训练中的关键瓶颈。并且随着规模扩大,通信开销也会变大 |
| 模型并行 | 不常用 | 现阶段很少用到超大型的网络下,不过偶尔会和数据并行方法并用 |
结论
:
- 随着集群规模的扩大通信开销变大,弱化了分布式的好处。
- 若使用高性能的硬件,计算开销变小,通信开销不变,最后导致通信开销占总的时间开销比例变大。

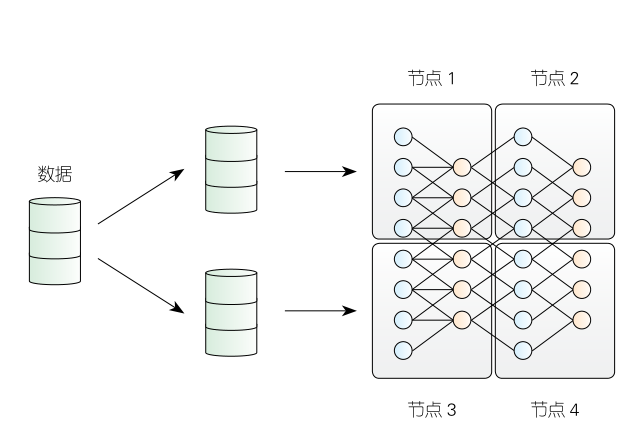
1.2 以何种结构组织计算节点?
- 架构影响训练过程中数据的传输方式和模型更新方式,进而影响训练时间。
- 参数服务器和同级节点接受的梯度,按层计算平均梯度。
1.2.1 中心化架构

-
参数服务器是最常见的中心化架构,如图。
- 通信方式是推送和拉取
特点:
-
工作节点间不进行任何通信,每个节点通过推送 / 拉取操作和参数服务器进行通信。
-
参数服务器上面存放全局共享的模型参数。
-
参数服务器的过程
:
- step1:节点读取数据,然后基于这些数据计算本地模型的梯度
- step2:节点将其本地梯度推送到参数服务器。
- step3:服务器接收所有工作节点发送的梯度首先聚合这些梯度,然后更新全局模型
- step4:最后工作节点再从服务器拉取最新的模型权重,并使用它进行下一次的迭代。

1.2.2 去中心化架构
-
特点
:节点与节点之间处于平等地位,对等体系结构使用归约和广播等集合通信操作。
步骤:
- 每个对等方首先从其他对等方接收梯度,然后对这些梯度求平均,这就是归约步。
-
然后,对等方将其本地梯度广播给所有其他对
等方。 - 节点从其他对等节点收到所有梯度后,立即更新其本地模型,然后执行下一个迭代。
1.3 将训练任务并行化到多个节点上时,如何协调这些节点?
1.3.1 同步更新,异步更新,延迟异步更新
| 同步更新 | 异步更新 | 延迟异步更新 | |
|---|---|---|---|
| 特点 | 会产生“掉队者”的问题,会等计算慢的节点 | 数据的陈旧性,模型收敛缓慢且没有收敛性保证 | 采用异步,但对数据的陈旧性进行限制 |
2.分布式深度学习通信优化(重点)
| 涉及的技术: | 四种 |
|---|---|
| 异构并行计算 | 深度神经网络 |
| 分布式系统 | 计算机网络 |
本文优化角度:
从网络协议栈层次角度出发,从
通信流量调度层
和
网络通信执行层
的角度,通信优化技术进行初步分类。
| 通信流量调度层 | 网络通信执行层 |
|---|---|
|
方案 :通过降低通信发生的频次,来降低通信数据量(梯度压缩)以及计算通信重叠等技术优化分布式训练的通信过程 |
不同的参数通信架构、不同的消息传递库以及不同的网络协议都会对通信产生影响 |

2.1 降低通信发生的频次
实现方法:以下两种方法都可以减少数据交换次数。
| 较大的批量 | 较长的通信周期 |
|---|---|
| 提高每个batch的大小,然后减少迭代次数 | 节点本身设置一轮的小范围的迭代 |
2.2 降低通信过程中传输的数据量
解决的问题:
当梯度和参数量很大时,由于交换大量 32 位浮点变量而导致的通信瓶颈,削弱了并行化带来的优势。
| 梯度量化 | 梯度稀疏化 |
|---|---|
|
使用 低精度数字 (即 8 位、4 位甚至 1位)替换 32 位浮点数,以此来减少传输的梯度量 |
选择了梯度向量中的一些 重要元素来更新模型参数 ,以避免不必要的传输开销 |
|
1:梯度 量化函数 量化为低精度值进行传输;2:接受的节点接受到以后, 反量化函数 从量化值重构原始梯度 |
1:稀疏化方法的核心是如从梯度向量中选择有效值,即如何将稠密更新转换为稀疏更新, T op- K 压缩方法 ;2. 涉及的方法:T,平衡模型精度与数据压缩比率是一个严峻的挑战。 误差补偿方法 解决这个问题 |
2.3 计算与通信重叠
特点:
计算梯度和传递梯度同时进行。
策略1
:
2.3.1 先进先出(FIFO)
反向传播最先计算最后一层梯度,最后计算输出等的梯度,最后一层梯度也是最先被发送过去的
Step
:
- 输出层那些计算好梯度要等待.
- 等所有层的梯度都计算完,从输出层梯度开始上传,等输入层的下一次迭代才能开始
策略2
:
2.3.2 无等待反向传播调度算法
定义:
一旦反向传播计算出某一层的梯度,后端引擎就开始传
输该层的梯度数据。但是,不同层的参数量可能并不相同,因此具有不同的计算和通信时间
- 结论:不一定某些特定网络模型上的 FIFO 调度表现更好
策略3
:
(Priority-base Parameter Propagation)
2.3.3 结合优先级无等待反向传播。
step:
- 越靠近输入层的优先级越高。
- 优先级高的层的梯度,最先被传播。
- 目的:让输入层的梯度尽早被传播,好开始下一次迭代。
- 采用了张量分割技术将各层的参数向量分解为适当的小块,根据他所在的层分配优先级,实现实现更细粒度的流水线化。
策略4:
2.3.4 :单步延迟 SGD(OD-SGD) 算法
- 下一次迭代计算对上一次迭代中通信过程的依赖。(怎么打破的?)
- 计算过程和通信过程高度重叠。
- 同步SGD和异步SGD两种更新算法的优势
| 总结:以上大部分调度算法都是启发式的,这就意味着调度算法并不是最优解 。贝叶斯优化算法和强化学习应用在算子调度 |
|---|
2.4 参数通信架构
2.4.1 Allreduce算法
- 在去中心化架构下,分布式深度学习的训练过程符合全局规约操作的语义:
- 每个节点独立计算局部梯度。
- 全局规约运算来计算梯度总和并将其发送给所有对等节点。
- 上述的过程可以看做是Allreduce运算。
- Allreduce在高性能领域研究很成熟。这两年引入到深度学习中,代表作:百度17年引入,Ring-Allreduce。
2.4.2 Ring-Allreduce算法
Ring-Allreduce算法下面两部分构成
| Reduce-Scatter | Allgather |
|---|---|
2.5 网络消息库
| 去中心化架构 | 中心化架构 |
|---|---|
| NVIDIA的集合通信库 | TensorFlow 中的 gRPC |
| Facabook 的 Gloo | MXNet 中默认使用的 ZMQ 消息库 |
| 百度的 Allreduce | |
| MPI |
MPI简介:
- Massage Passing Interface:是消息传递函数库的标准规范
- 一种新的库描述,不是一种语言。共有上百个函数调用接口,提供与C和Fortran语言的绑定。
- MPI是一种标准或规范的代表,而不是特指某一个对它的具体实现
-
MPI是一种消息传递编程模型,并成为这种编程模型的代表和事实上的标准
reference:
https://blog.csdn.net/qq_40765537/article/details/106425355
2.6 网络协议优化
2.6.1 早期分布式训练框架通信协议
原理:
- 基于传输控制协议(TCP)/ 互联网协议(IP),先将参数数据复制到内核态的网络协议栈。
- 通过网络络接口发出去,这些复制操作增加了分布式训练的通信延迟
2.6.2 目前的分布式框架通信协议
原理:
-
远程直接内存访问(RDMA)允许用户态进程直
接读取和写入远端进程的地址空间。 - 用这个协议直接替换了TCP/IP 协议,幅降低分布式训练的同步开销,提升训练速度,扩大训练规模。
refercence:
[1]董德尊,欧阳硕.分布式深度学习系统网络通信优化技术[J].中兴通讯技术,2020,26(05):2-8.
[2]https://blog.csdn.net/qq_40765537/article/details/106425355