残差网络学习心得
残差网络介绍
ResNets是由残差块构建的,首先先解释一下什么是残差块。
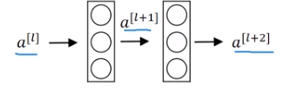
这是一个两层神经网络在L层进行激活。计算过程是从a[l]开始,首先进行线性激活 。
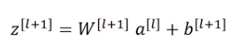
根据这个等式,通过a[l]算出z[l+1]即a[l]乘以权重矩阵再加上偏差因子,然后通过非线性Relu激活得到a[l+1]。
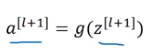
随后我们再进行线性激活,从下面等式可以得出z[l+2]。
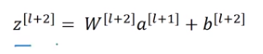
最后根据这个等式再进行Relu非线性激活

这里的g指的是Relu非线性函数

换句话说,信息流从a[l]到a[l+2],需要经历上述所有步骤即这组网络层的主路径。在残差网络中有一点变化:我们将a[l]直接向后拷贝到神经网络的深层,在Relu非线性激活前加上a[l],这是一条捷径将a[l]的信息直接传达到神经网络的深层(不再沿着主路经传递)

这就意味着最后这个等式去掉了
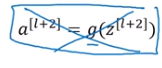
取而代之的是另一个Relu非线性函数,仍然对z[l+2]进行g函数处理,但这次要加上a[l],也就是加上的这个a[l]产生了一个残差块。
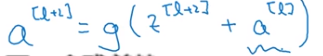
我们也可以画一条捷径直达第二层,实际上这条捷径是在进行Relu非线性激活之前加上的。而这里的每一个节点都执行了线性函数和Relu激活函数,所以a[l]插入的时机是在线性激活之后Relu激活之前

除了捷径,你还听到另一个术语“跳远连接”,就是指a[l]跳过一层或者好几层,从而将信息传递到神经网络的更深层。
使用残差块能够训练更深的神经网络,构建一个Resnet网络就是通过将很多这样的残差块堆积在一起,形成一个深度神经网络。

我们来看看这样一个网络,这并不是一个残差网络,而是一个普通网络,把它变成ResNet的方法就是加上所有的跳远连接。

正如前面所看到的每两层增加一个捷径,构成一个残差块,所以这个图就有5个残差块,构成一个残差网络。
如果我们使用标准优化算法训练一个普通网络,比如梯度下降或者其他优化算法,如果没有残差,没有这些捷径。凭经验,你会发现随着网络深度的加深,训练错误会先减少然后增多。

而理论上随着网络深度的加深,应该训练得越来越好才对。也就是说,理论上网络深度越深越好,但实际上,如果没有残差网络,对于一个普通网络来说,深度越深意味着用优化算法越难训练。
但有了ResNets就不一样了,即使网络再深,训练的表现却不错,错误会减少。
为什么残差网络有如此好的表现?
先来看一个例子,上面我们说到一个网络深度越深,它在训练集上训练网络的效率会有所减弱,这也是有时我们不愿加深层数的原因。但在训练ResNets网络时并不完全如此。
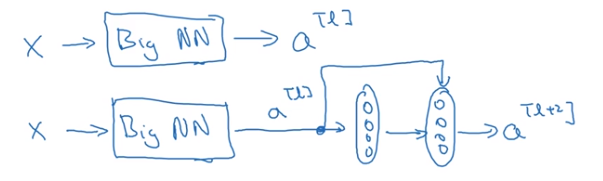
假设有一个大型神经网络,其输入为x,输出激活值为a[l],如果你想增加这个神经网络的深度,就再给这个网络额外添加两层,最后输出为a[l+2],可以把这两层看作ResNet块,即具有近路连接的残差块。假设我们在整个网络中使用Relu激活函数,所以激活值都大于等于0。a[l+2]=g(z[l+2]+a[l]),添加项a[l]是刚添加的跳远连接的输入。

如果z[l+2]=0,那么a[l+2]=a[l]。因为我们假定使用Relu激活函数,并且所有激活值都是负的。结果表明,残差块学习这个恒等式函数残差块并不难。加入残差块后,我们可以得出a[l+2]=a[l],这说明即使增加两层它的效率也不逊色与简单的神经网络。所以给大型神经网络增加两层,不论是把残差块添加到神经网络的中间还是末端位置都不会影响网络的实现。当然我们不仅要保持效率还要提升。想象一下,如果这些隐层单元学到一些有用信息,那么它可能比学习恒等函数变现的更好。而哪些不含有残差的普通网络情况就不一样了,当层数越来越深时,就算选择学习恒等函数的参数都很困难。所以很多层最后的表现不但没有更好反而更糟。残差网络起作用的主要原因就是这些残差块学习恒等函数非常容易。你能确定网络性能不会受到影响,很多时候甚至会提高效率。另一点值得去说的是,假设z[l+2]与a[l]具有相同维度,所以Resnet使用了许多相同卷积,这个a[l]的维度等于这个输出层的维度。

我们只需要在普通网络中加入如图残差块就能变为残差网络。