前面介绍了JMeter入门使用,本文我们来讲讲JMeter的正则表达式
在使用Jmeter过程中,会经常使用到正则表达式提取器提取器,哪些地方用到正则表达式呢?答案是:下一个接口的请求需要用到上个接口返回结果中的某一个数据或者多个数据
举例:用户登录APP后,修改用户的登录密码。因为每个用户的userid都不一样,并且每次登录token也是变化的,所以这个时候需要找到userid和token后,在修改用户密码。

按照接口文档手写脚本
-
打开Jmeter
-
在测试计划中添加线程组(选中测试计划右键:添加–>线程(用户)–>线程组)
-
在线程组中添加HTTP请求(选中线程组右键:添加–>取样器–>HTTP请求)
-
在HTTP请求中添加HTTP请求默认值(选中HTTP请求右键:添加–>配置元素–>HTTP信息头管理器)
-
按照接口文档成功的编写好接口的数据(PS:录制脚本也可以)
录制脚本
-
打开Jmeter
-
添加线程组(选中测试计划右键:添加–>线程(用户)–>线程组)
-
添加HTTP代理服务器(选中测试计划右键:添加–>非测试元件–>HTTP代理服务器)我个人的喜好是下图的配置
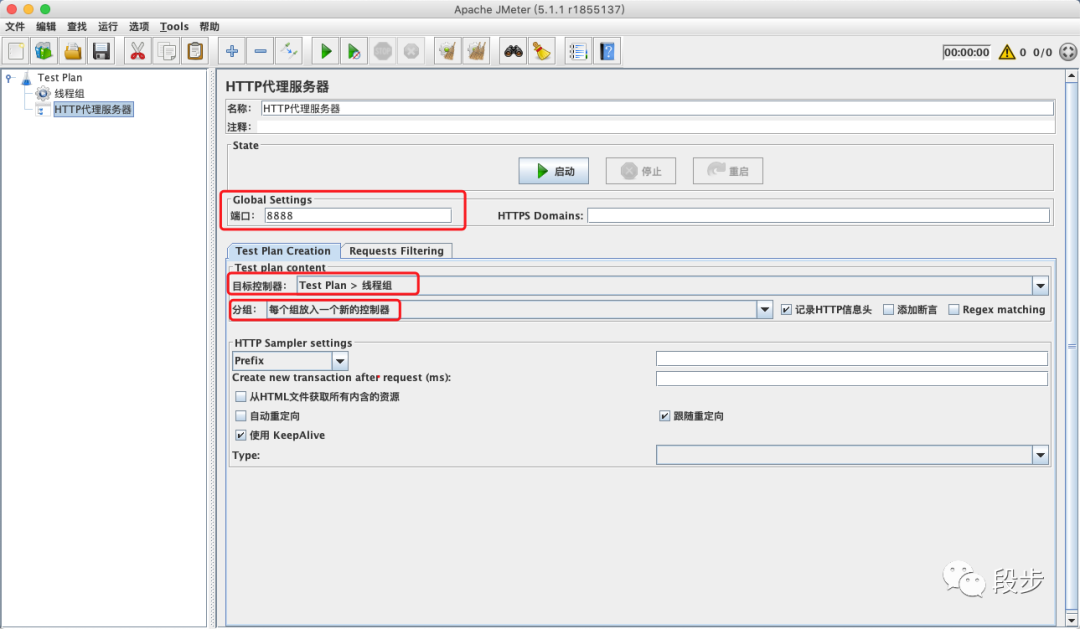
-
点击启动
手机端录制:
端口号:8888(一点要和JMeter的HTTP代理服务器中的端口号保持一致)
-
打开手机的wifi,
手机连接wifi和你PC是同一个wifi或者同一个局域网
,点击手机连接的wifi详情,找到【http代理】这一栏 -
配置http代理
服务器地址:PC的IP地址
PC端WEB录制(以火狐浏览器举例):
-
打开火狐浏览器,点击菜单–>首选项
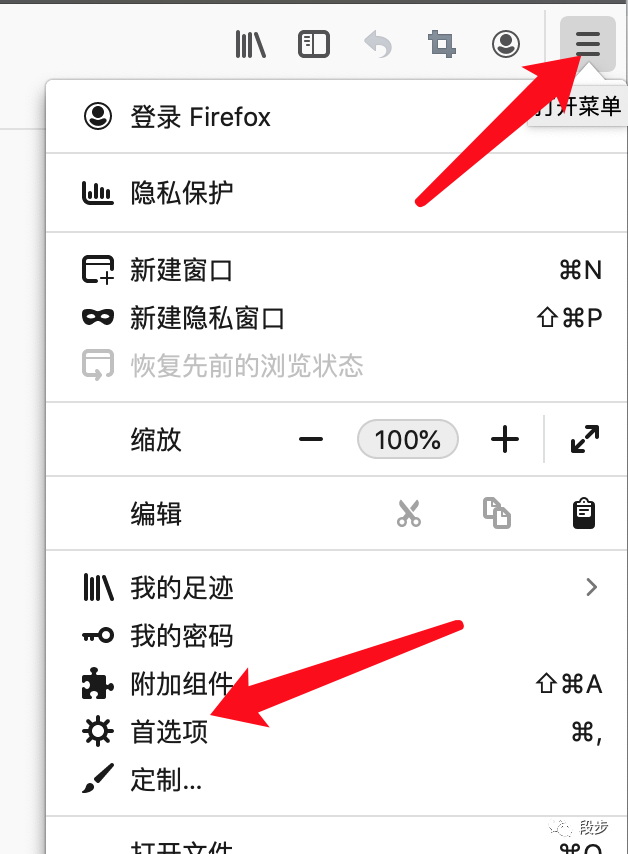
-
找到“网络设置”点击设置
-
按照下图设置接口

用户操作:
用户在手机端打开APP,输入账号密码,点击登录,然后在设置页面,修改用户的密码。JMeter会录制用户操作APP的所有请求的接口,由于例子中只涉及到修改登录接口和修改密码接口,那么就需要在JMeter中将多余的接口删除。最后整理后的接口如下图:
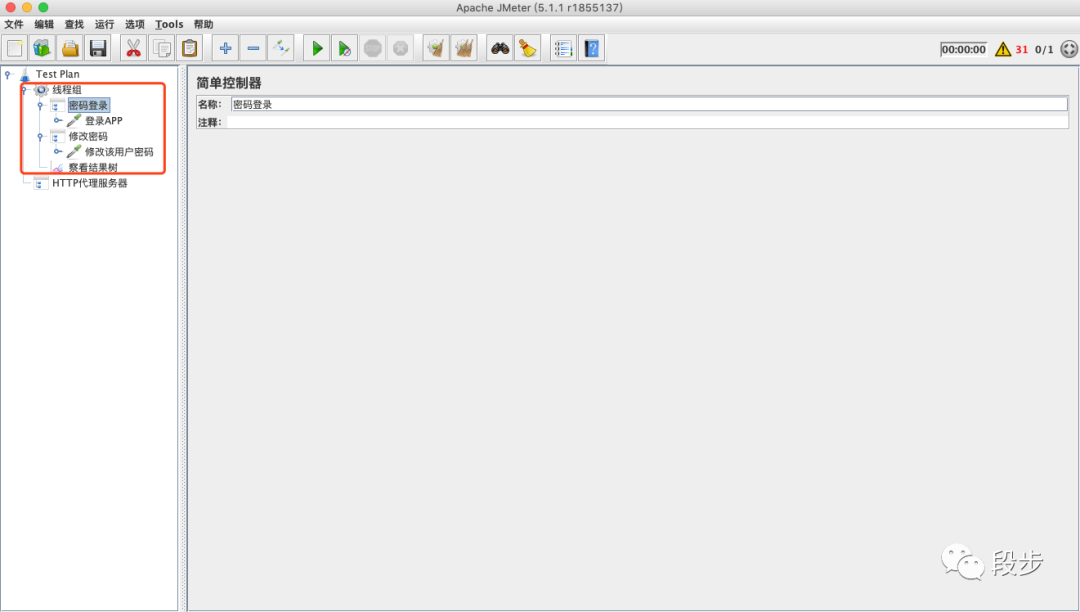
-
添加查看结果树
-
点击启动

,回放一下录制的脚本
-
毫无疑问,用户修改密码的接口会失败
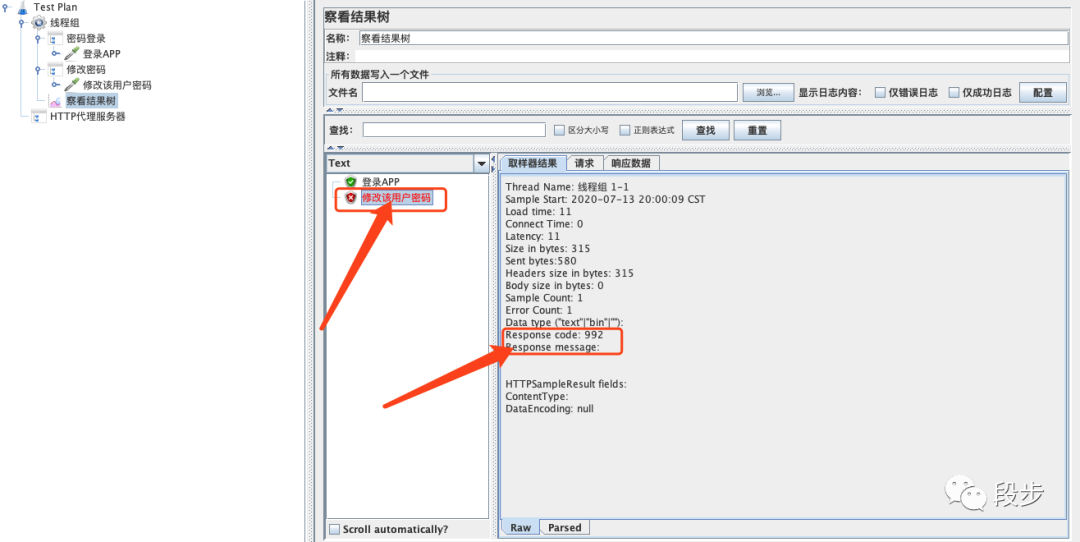
-
这个时候就需要在登录接口的下面添加上两个正则表达式提取器:一个提取用户的userid、一个提取用户的token(选中登录APP接口右键:添加–>后置处理器–>正则表达式提取器)

JMeter正则表达式提取器–面板介绍

-
注释不多说,随便自己喜欢
-
Apply to:应用范围(一般情况下默认即可)
-
要检查的字段:样本数据源(一般我们选择主体,即服务器返回给我们的页面主体信息)
-
引用名称:其他地方引用时的变量名称,引用方法:${引用名称}
-
正则表达式:数据提取器。提取内容的正则表达式
【特别注意:()表示提取,对于你要提前的内容需要用小括号括起来】
-
模板:$1$代表只取第一个值,$2$代表只取第二个值········
-
匹配数字:0代表随机取值,1代表全部取值,通常情况下填0
-
缺省值:正则匹配失败时,取的值

我们通过查看结果树中的“登录APP”的接口返回值,可以看到返回的数据中包含有用户userid和token信息
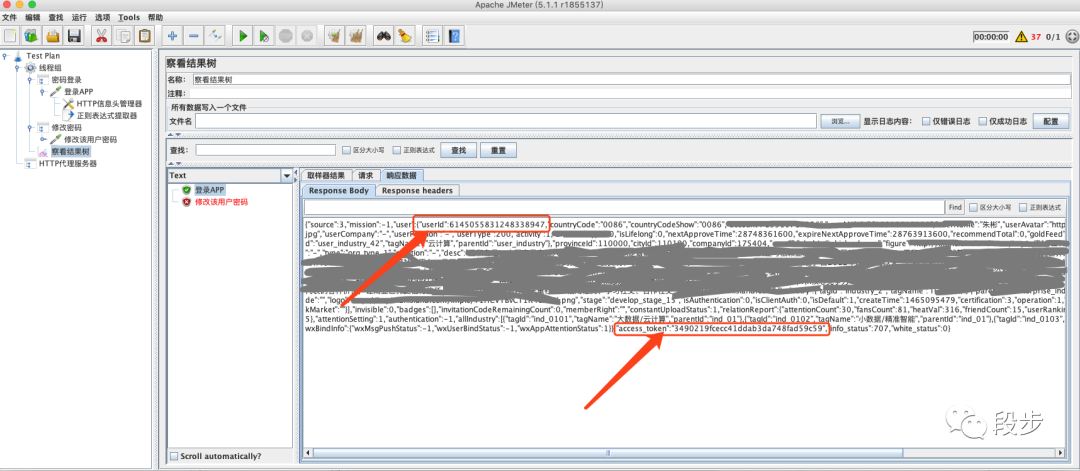
这个时候我们所要做的事情就是将他们提取出来,放到“修改该用户密码”接口的HTTP信息头管理器里面
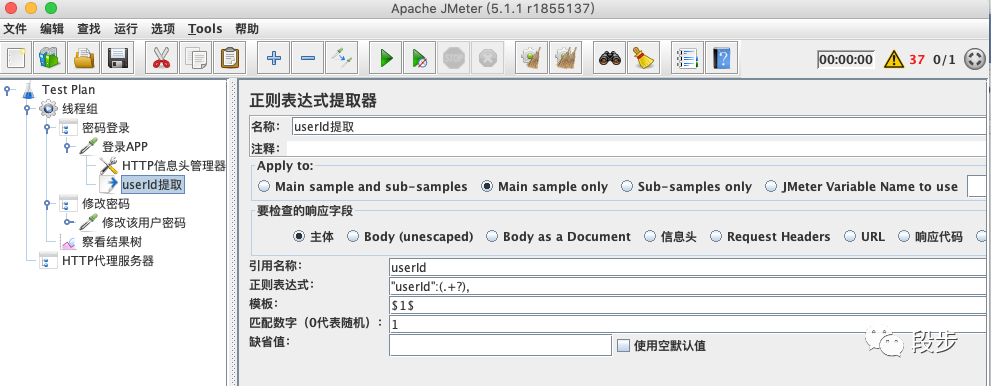
提取userid
-
其中【”userId”: 】为左边界,【,】为右边界
-
左右边界的作用是定位出来你需要找的字符串的位置,左右边界一定要明确,不能出现模糊的情况,这样才能找成功定位
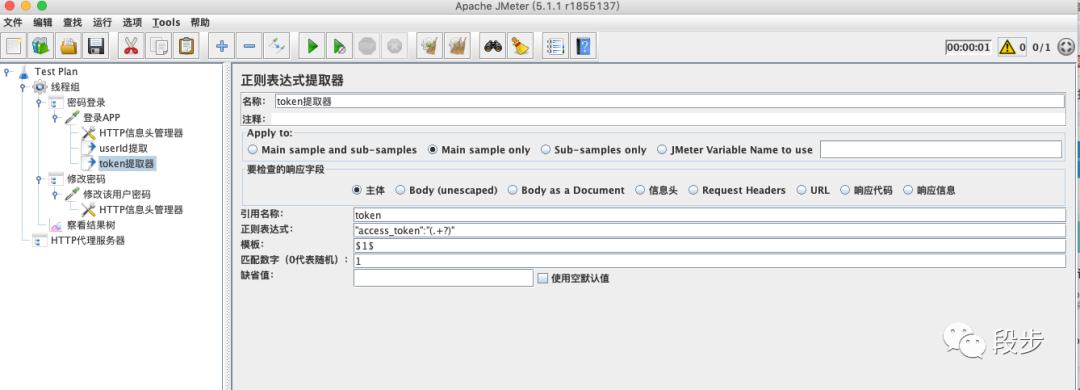
提取token
-
其中【”access_token”: “】为左边界,【”】为右边界
-
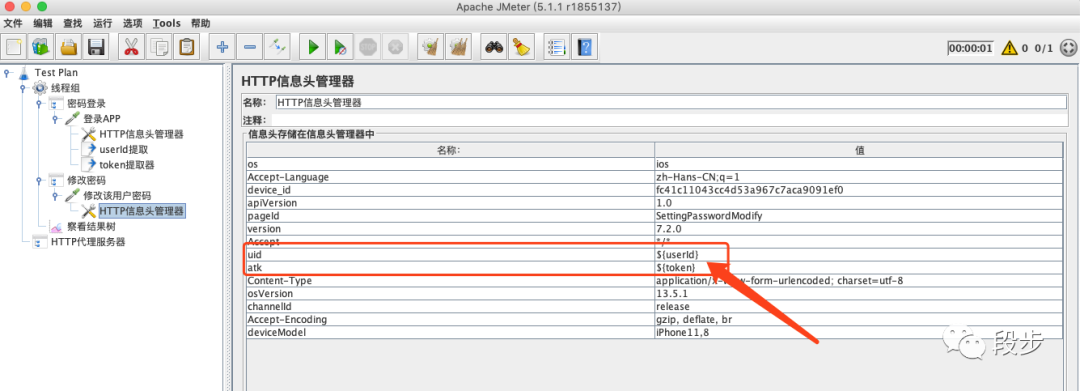
修改“修改该用户密码”接口的HTTP信息头管理器里的uid和Accept
-
再次点击
,修改密码接口通了
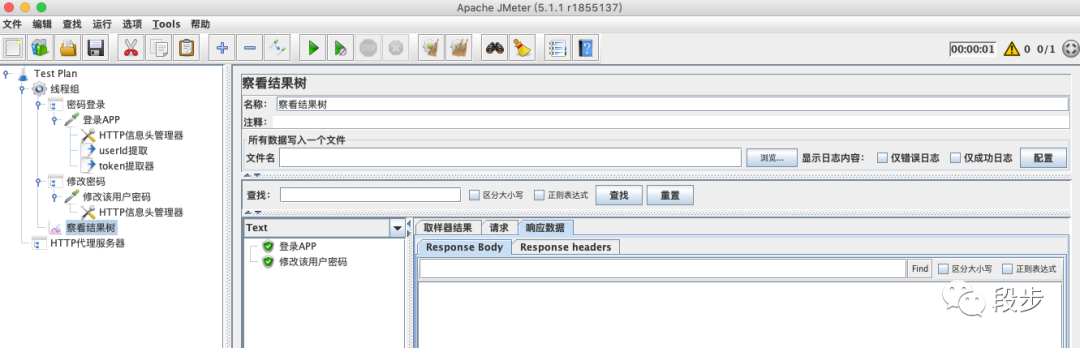
分享一个笨方法:
-
在提取正则表达式的时候,想看看提取后的内容是不是你想提取的内容咋办呢,我的笨方法是:创建一个HTTP请求,将提取的内容放到请求中去:
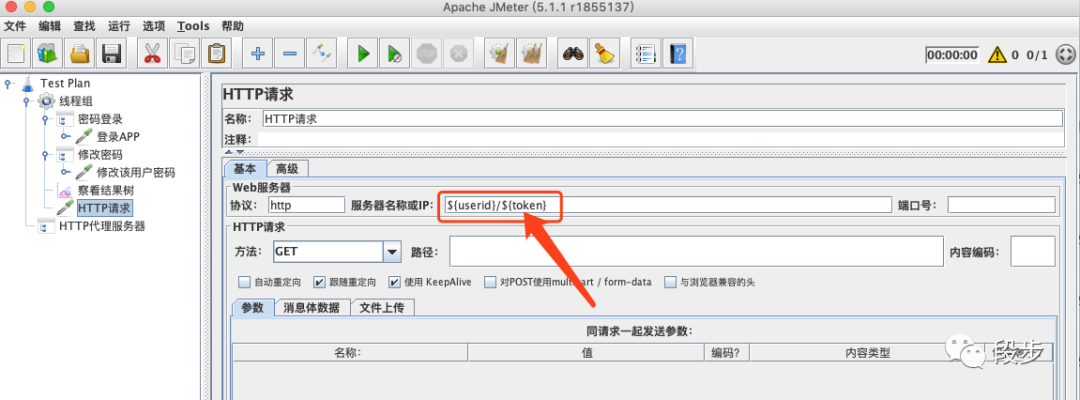
-
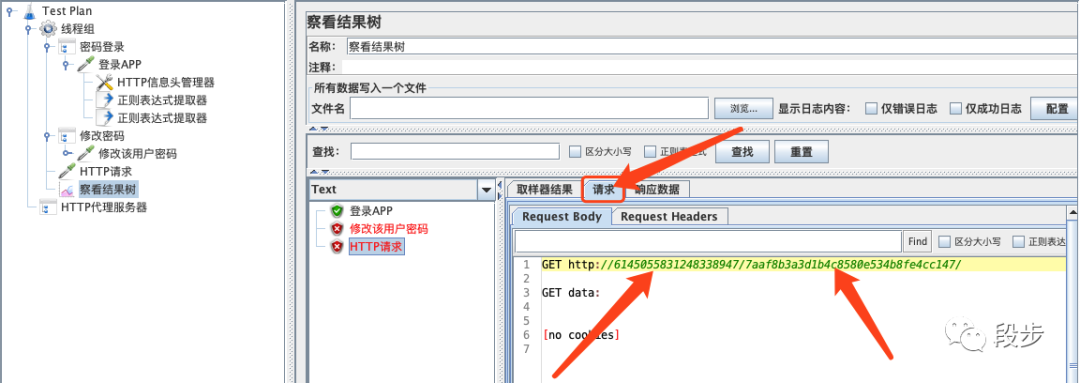
再回放脚本后,通过查看结果树中HTTP请求中的请求就能看到提取的内容:

(.+?)
-
():封装了待返回的匹配字符串
-
.:匹配任何单个字符串
-
+:一次或多次
-
?:不要太贪婪,在找到第一个匹配项后停止
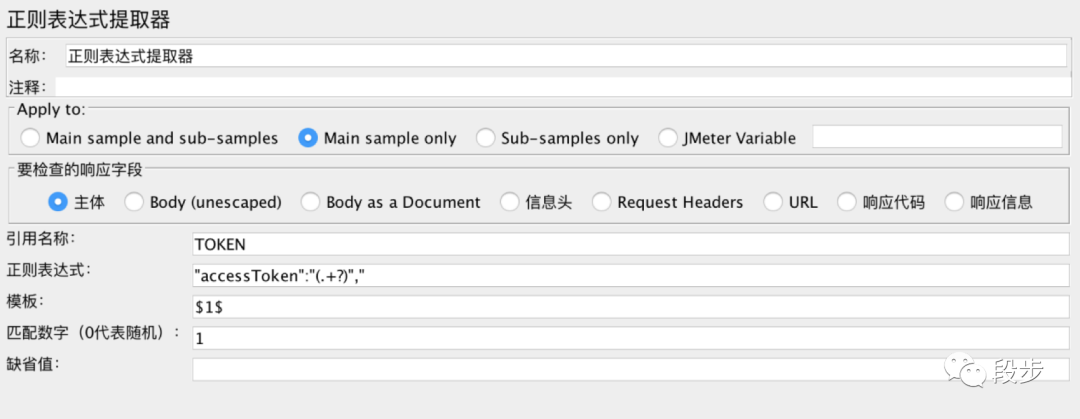
举例1:提取红圈“”中的字符串

-
正则表达式为:
-
其中”accessToken”:”为左边界,”,”为右边界
举例2:提取红圈“”中的字符串

-
正则表达式:

-
TOKEN:这个时候的TOKEN的值是图中两个标记处的值合并在一起的值c4fc8fb1c0f64d5190362b12b7e8c06bbd8237614db743e1b7455caae7c2b046
-
TKOKEN_g0: [“accessToken”:”c4fc8fb1c0f64d5190362b12b7e8c06b”,”refreshToken”:”bd8237614db743e1b7455caae7c2b046″,”]
-
TOKEN_g1: c4fc8fb1c0f64d5190362b12b7e8c06b
-
TOKEN_g2: bd8237614db743e1b7455caae7c2b046
-
需要引用前一个标记框(accessToken)中的值:${TOKEN_g1}
-
需要引用后一个标记框中(refreshToken)的值:${TOKEN_g2}
\n\b([^ abc]+?)\b
-
“\n”:换行
-
“\b”:不会消耗任何字符只匹配一个位置,常用于匹配单词边界如:我想从字符串中”This is Regex”匹配单独的单词 “is” 正则就要写成 “\bis\b”
注:\b就是过滤掉空格。\b 不会匹配is 两边的字符,但它会识别is 两边是否为单词的边界
-
“^” :会匹配行或者字符串的起始位置,有时还会匹配整个文档的起始 位置。
注:^ 就是非的意思
-
“[ abc]”: 字符组 匹配包含括号内元素的字符
-
“[^abc]” 匹配除了abc以外的任意字符
举例:提取红圈中验证码
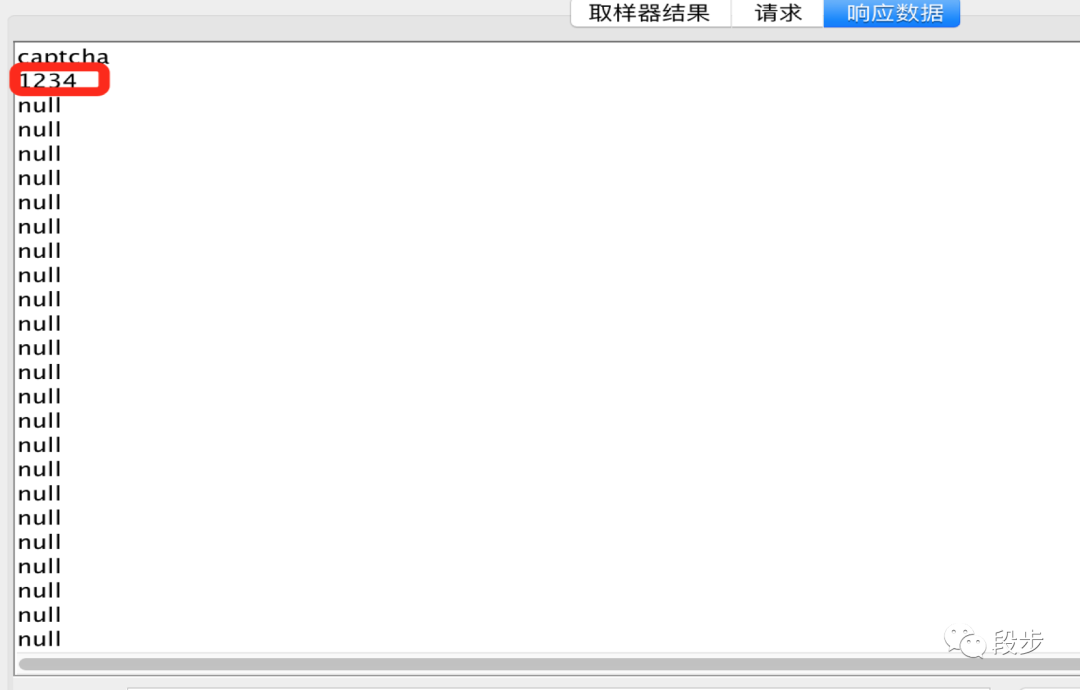
-
正则表达式:captcha\n\b([^ ]+?)\b
-
其中captcha\n为左边界,没有右边界就不用写