需求:自己搭建一个足够小(1M以内)的手部检测的模型。使用目标检测算法和手部的数据集进行实验。
经过自己探索,寻找的资源和实施方法整理如下。
1.直接调用MideaPipe
可以直接调用MediaPipe的API直接实现手部检测及关键点检测,效果挺好,不需要训练,直接跑推理即可。代码来自:https://www.youtube.com/watch?v=x4eeX7WJIuA。如果有需要的可以采用此方案。可以参考:
2022.3.3 Python-opencv-mediapipe – 简书
import cv2
import mediapipe as mp
import time
cap = cv2.VideoCapture(0)
mpHands = mp.solutions.hands
hands = mpHands.Hands(min_detection_confidence=0.5)
mpDraw = mp.solutions.drawing_utils
handLmsStyle = mpDraw.DrawingSpec(color=(0, 0, 255), thickness=5)
handConsStyle = mpDraw.DrawingSpec(color=(0, 255, 0), thickness=10)
pTime = 0
cTime = 0
#https://www.youtube.com/watch?v=x4eeX7WJIuA
while True:
ret, img = cap.read()
if ret:
imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
result = hands.process(imgRGB)
# print(result.multi_hand_landmarks)
imgHeight = img.shape[0]
imgWidth = img.shape[1]
if result.multi_hand_landmarks:
for handLms in result.multi_hand_landmarks:
mpDraw.draw_landmarks(img, handLms, mpHands.HAND_CONNECTIONS, handLmsStyle, handConsStyle)
for i, lm in enumerate(handLms.landmark):
xPos = int(lm.x * imgWidth)
yPos = int(lm.y * imgHeight)
zPos = int(lm.z )
cv2.putText(img, str(i), (xPos - 25, yPos + 5), cv2.FONT_HERSHEY_SIMPLEX, 0.4, (0, 0, 255), 2)
if i == 4:
cv2.circle(img, (xPos, yPos), 20, (0, 0, 255), cv2.FILLED)
print(i, xPos, yPos, zPos)
cTime = time.time()
fps = 1/(cTime - pTime)
pTime = cTime
cv2.putText(img, f"FPS : {int(fps)}", (30, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 3)
cv2.imshow('img', img)
if cv2.waitKey(1) == ord('q'):
break
2.Yolo V3
参考代码链接:
Eric.Lee2021 / yolo_v3 · GitCodexx
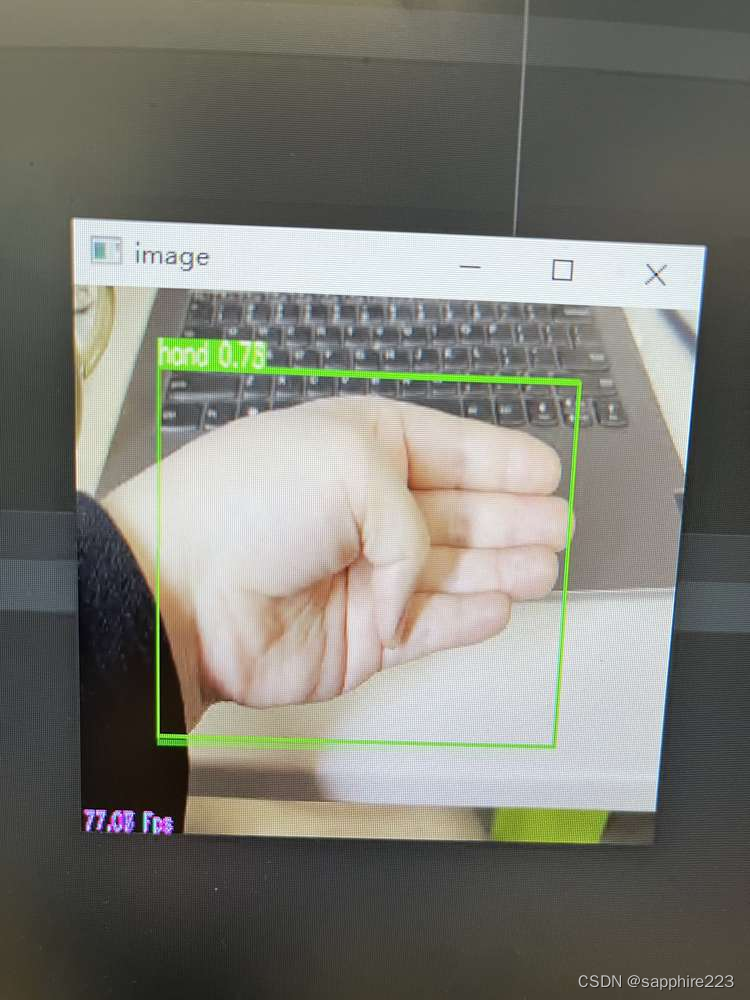
此份资源中有多种类别的目标检测模型及数据集,很容易能够跑通,自己跑了predict.py,初步效果不是特别好,很多帧识别不出手,下面有一个自己跑的效果图。主要模型60多MB,不符合小模型的需求。遂放弃此方案。不过手部数据集留用了。需要相关数据集的可以去看看。
其中除了yolo v3还包含tiny模型。
3.Yolo_FastestV2
作者给了一个相关网络模型的比较,如下图,准确率和模型大小一目了然,可以按需去寻找想要的资源。
| Network | Model Size | mAP(VOC 2007) | FLOPS |
|---|---|---|---|
| Tiny YOLOv2 | 60.5MB | 57.1% | 6.97BFlops |
| Tiny YOLOv3 | 33.4MB | 58.4% | 5.52BFlops |
| YOLO Nano | 4.0MB | 69.1% | 4.51Bflops |
| MobileNetv2-SSD-Lite | 13.8MB | 68.6% | &Bflops |
| MobileNetV2-YOLOv3 | 11.52MB | 70.20% | 2.02Bflos |
| Pelee-SSD | 21.68MB | 70.09% | 2.40Bflos |
|
Yolo Fastest |
1.3MB | 61.02% | 0.23Bflops |
|
Yolo Fastest-XL |
3.5MB | 69.43% | 0.70Bflops |
|
MobileNetv2-Yolo-Lite |
8.0MB | 73.26% | 1.80Bflops |
此资源有比较完整的小模型训练及移动端部署方法,不过它是基于COCO数据集的,没有手部数据集,并需要重新组织数据。本人使用2中的手部数据集,按作者写的文档,重新组织数据,步骤如下:
1)重构train和val数据,按照4:1的数据量来划分整个数据。其实只需要分train.txt和val.txt将图片地址分别填进去,也需要填label地址。具体看作者的文档就可以弄好。
2)组织.data和.names文件
新建这两个文件,先按coco的复制粘贴:
需要按作者写的,生成当前数据集锚点,并填入配置文件。
python3 genanchors.py --traintxt ./train.txt同时在配置文件中填好数据集位置,这些都很清晰。
hand.data
[name]
model_name=hand
[train-configure]
epochs=300
steps=150,250
batch_size=128
subdivisions=1
learning_rate=0.001
[model-configure]
pre_weights=None
classes=1
width=352
height=352
anchor_num=3
anchors=5.07,9.50, 8.77,12.67, 18.48,23.87, 32.59,37.93, 54.71,59.43, 90.83,109.99
[data-configure]
train=./train/anno/train.txt
val=./train/anno/val.txt
names=./data/hand.nameshand.names中写个hand即可。
3)开始训练
运行train.py即可。
4)测试
目前初步训练MAP在30%多,用一些图像测试效果还可以,模型1000多kb,基本满足要求,因需求有变动,后续再对模型进行优化。
5)移动端部署
作者写的很清楚,后续自己再补充。
4.基于TF的手部检测
现在又给提出新的需求:使用量化模型,需要tf1.15搭建的网络模型,且模型需要小于1mb。上述都是pytorch的模型,暂不使用上面方案。
查找相关资料,直接使用TensorFlow object detection API即可满足需求。
使用ssdlite+mobilenetv2,算法及网络模型介绍如下:
ssd算法:
SSD算法,其英文全名是Single Shot MultiBox Detector,Single shot指明了SSD算法属于one-stage方法,MultiBox指明了SSD是多框预测。对于Faster R-CNN,其先通过CNN得到候选框,然后再进行分类与回归,而Yolo与SSD可以一步到位完成检测。
相比Yolo,SSD采用CNN来直接进行检测,而不是像Yolo那样在全连接层之后做检测。其实采用卷积直接做检测只是SSD相比Yolo的其中一个不同点,另外还有两个重要的改变,一是SSD提取了不同尺度的特征图来做检测,大尺度特征图(较靠前的特征图)可以用来检测小物体,而小尺度特征图(较靠后的特征图)用来检测大物体;二是SSD采用了不同尺度和长宽比的先验框(Prior boxes, Default boxes,在Faster R-CNN中叫做锚,Anchors)。Yolo算法缺点是难以检测小目标,而且定位不准,以下这几点重要改进使得SSD在一定程度上克服这些缺点:
(1)采用多尺度特征图用于检测
所谓多尺度采用大小不同的特征图,CNN网络一般前面的特征图比较大,后面会逐渐采用stride=2的卷积或者pool来降低特征图大小,即一个比较大的特征图和一个比较小的特征图,它们都用来做检测。这样做的好处是比较大的特征图来用来检测相对较小的目标,而小的特征图负责检测大目标,如下图所示,8×8的特征图可以划分更多的单元,但是其每个单元的先验框尺度比较小。
(2)采用卷积进行检测
与Yolo最后采用全连接层不同,SSD直接采用卷积对不同的特征图来进行提取检测结果。对于形状为 m×n×p 的特征图,只需要采用 3×3×p 这样比较小的卷积核得到检测值。
(3)设置先验框
在Yolo中,每个单元预测多个边界框,但是其都是相对这个单元本身(正方块),但是真实目标的形状是多变的,Yolo需要在训练过程中自适应目标的形状。而SSD借鉴了Faster R-CNN中anchor的理念,每个单元设置尺度或者长宽比不同的先验框,预测的边界框(bounding boxes)是以这些先验框为基准的,在一定程度上减少训练难度。一般情况下,每个单元会设置多个先验框,其尺度和长宽比存在差异,如图2所示,可以看到每个单元使用了4个不同的先验框,图片中猫和狗分别采用最适合它们形状的先验框来进行训练。
SSD的检测值也与Yolo不太一样。对于每个单元的每个先验框,其都输出一套独立的检测值,对应一个边界框,主要分为两个部分。第一部分是各个类别的置信度或者评分,值得注意的是SSD将背景也当做了一个特殊的类别,如果检测目标共有 c 个类别,SSD其实需要预测 c+1 个置信度值,其中第一个置信度指的是不含目标或者属于背景的评分。后面当我们说 c 个类别置信度时,请记住里面包含背景那个特殊的类别,即真实的检测类别只有 c−1 个。在预测过程中,置信度最高的那个类别就是边界框所属的类别,特别地,当第一个置信度值最高时,表示边界框中并不包含目标。第二部分就是边界框的location,包含4个值 (cx,cy,w,h) ,分别表示边界框的中心坐标以及宽高。但是真实预测值其实只是边界框相对于先验框的转换值(paper里面说是offset,但是觉得transformation更合适,参见
R-CNN
)。先验框位置用 d=(dcx,dcy,dw,dh) 表示,其对应边界框用 b=(bcx,bcy,bw,bh) 表示,那么边界框的预测值 l 其实是 b 相对于 d 的转换值:
lcx=(bcx−dcx)/dw, lcy=(bcy−dcy)/dh
lw=log(bw/dw), lh=log(bh/dh)
习惯上,我们称上面这个过程为边界框的编码(encode),预测时,你需要反向这个过程,即进行解码(decode),从预测值 l 中得到边界框的真实位置 b :
bcx=dwlcx+dcx, bcy=dylcy+dcy
bw=dwexp(lw), bh=dhexp(lh)
然而,在SSD的
Caffe源码
实现中还有trick,那就是设置variance超参数来调整检测值,通过bool参数variance_encoded_in_target来控制两种模式,当其为True时,表示variance被包含在预测值中,就是上面那种情况。但是如果是False(大部分采用这种方式,训练更容易?),就需要手动设置超参数variance,用来对 l 的4个值进行放缩,此时边界框需要这样解码:
bcx=dw(variance[0]∗lcx)+dcx, bcy=dy(variance[1]∗lcy)+dcy
bw=dwexp(variance[2]∗lw), bh=dhexp(variance[3]∗lh)
综上所述,对于一个大小 m×n 的特征图,共有 mn 个单元,每个单元设置的先验框数目记为 k ,那么每个单元共需要 (c+4)k 个预测值,所有的单元共需要 (c+4)kmn 个预测值,由于SSD采用卷积做检测,所以就需要 (c+4)k 个卷积核完成这个特征图的检测过程。
网络结构:
因移动端部署,考虑模型大小,选用mobilenet V2作为基础模型,网络结构如下:

系列讲解参考:
MobileNet系列(万文长字详细讲解,一篇足以) | AI技术聚合
实验流程:
具体实验流程参考:
models/research/object_detection at master · tensorflow/models · GitHub
基本整个操作在此链接中已包括,但是实际中还是遇到了一些其他问题,具体记录如下:
1.安装TensorFlow及API
本次实验需要使用1.x的TensorFlow,注意环境对应。
2.准备pipeline.config文件
在~/models/research/object_detection/samples/configs路径寻找需要的模型的config,因为实验要求模型小于1mb,且使用量化,本次选用ssd_mobilenet_v2_coco.config文件。所有的训练、评估的参数都在此文件中进行配置,数据集路径也填入此文件。
3.准备数据集
数据集来自第二节。TensorFlow代码要求将数据集组织成tfrecord形式。
1)划分训练、测试集
随意写了个读取、copy的代码,将数据按照训练、评估、测试4:1:1来进行划分。
#划分数据集
import os
import shutil
filepath = '~/datasets_TVCOCO_hand_train/anno/images/'
filelist = os.listdir(filepath)
dis = '~/datasets_TVCOCO_hand_train/anno/val/images/'
# if not os.path.isdir(dis):
# os.mkdir(dis)
# l = len(filelist)
# print(filelist)
# c=0
# for i in filelist:
# from_path = filepath + i
# shutil.move(from_path,dis)
# c =c+1
# if c == 5000:
# break
#label要对应图像名称
labelpath = '~/datasets_TVCOCO_hand_train/anno/labels/'
labeldis = '~/datasets_TVCOCO_hand_train/anno/val/labels/'
if not os.path.isdir(labeldis):
os.mkdir(labeldis)
for i in os.listdir(dis):
from_path =labelpath + os.path.splitext(i)[0] +'.txt'
shutil.move(from_path,labeldis)
在增广数据集的时候遇到json格式的label文件,我将json转化为txt,再进行下一步,也可以考虑修改下面的代码;
json2txt.py
import json
import cv2
import os
all_classes={'labels':0} ##类别列表,与训练配置文件中的顺序保持一致
savepath="/home/Downloads/hand_hagird_label/ann_train_val/two_up_txt/" #txt文件存放位置
jsonpath="/home/Downloads/hand_hagird_label/ann_train_val/two_up.json" #json文件位置
#imgpath="./train_img/" #图片位置,因为我的json文件中没有图片size,故需要读取图片得到size
jsonfile = open(jsonpath,'r')
content = jsonfile.read()
a = json.loads(content)
items = a.items()
#print(items)
for key,value in items:
print("img_name",key)
label_int= 0
print("value",value['bboxes'][0])
outfile=open(savepath+key+'.txt','w')
#print("outfile",outfile)
if not value['bboxes']:
continue
x1,y1,x2,y2=value['bboxes'][0]
print(label_int)
print("bboxes",x1,y1,x2,y2)
outfile.write(str(label_int)+" "+str(x1)+" "+str(y1)+" "+str(x2)+" "+str(y2)+'\n')
jsonfile.close()2)组织成tfrecord形式
参考TensorFlow网站
models/using_your_own_dataset.md at master · tensorflow/models · GitHub
及~/models/research/object_detection/dataset_tools处代码,即可组织好代码:
import hashlib
import io
import logging
import os
import random
import re
import cv2
import contextlib2
from lxml import etree
import numpy as np
import PIL.Image
import tensorflow.compat.v1 as tf
from glob import glob
from object_detection.dataset_tools import tf_record_creation_util
from object_detection.utils import dataset_util
from object_detection.utils import label_map_util
flags = tf.app.flags
flags.DEFINE_string('data_dir', '', 'Root directory to raw basketball dataset.')
flags.DEFINE_string('output_path', '', 'Path to output TFRecord')
flags.DEFINE_integer('num_shards', 10, 'Number of TFRecord shards')
FLAGS = flags.FLAGS
def create_tf_example(example):
# TODO(user): Populate the following variables from your example.
height = example['height'] # Image height
width = example['width'] # Image width
#print(height,width)
filename = example['filename'].encode('utf8') # Filename of the image. Empty if image is not from file
encoded_image_data = example['image'] # Encoded image bytes
image_format = 'jpeg'.encode('utf8') # b'jpeg' or b'png'
key = example['key'].encode('utf8')
xmins = example['xmins'] # List of normalized left x coordinates in bounding box (1 per box)
xmaxs = example['xmaxs'] # List of normalized right x coordinates in bounding box
# (1 per box)
ymins = example['ymins'] # List of normalized top y coordinates in bounding box (1 per box)
ymaxs = example['ymaxs'] # List of normalized bottom y coordinates in bounding box
# (1 per box)
classes_text = [class_name.encode('utf8') for class_name in example['class_names']] # List of string class name of bounding box (1 per box)
classes = example['classes'] # List of integer class id of bounding box (1 per box)
tf_example = tf.train.Example(features=tf.train.Features(feature={
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(filename),
'image/source_id': dataset_util.bytes_feature(filename),
'image/key/sha256': dataset_util.bytes_feature(key),
'image/encoded': dataset_util.bytes_feature(encoded_image_data),
'image/format': dataset_util.bytes_feature(image_format),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmins),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymins),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
}))
return tf_example
def create_tf_record(output_filename,
num_shards,
data_dir,
data_type='train'):
"""Creates a TFRecord file from examples.
Args:
output_filename: Path to where output file is saved.
annotations_dir: Directory where annotation files are stored.
num_shards: Number of shards for output file.
image_dir: Directory where image files are stored.
"""
with contextlib2.ExitStack() as tf_record_close_stack:
output_tfrecords = tf_record_creation_util.open_sharded_output_tfrecords(
tf_record_close_stack, os.path.join(output_filename, "%s.record"%data_type), num_shards)
image_dir = os.path.join(data_dir, data_type, "images/", "*.jpg")
image_list = glob(image_dir)
skipped = 0
for idx, imagename in enumerate(image_list):
if idx % 100 == 0:
logging.info('On image %d of %d', idx, len(image_list))
label_path = os.path.join(data_dir, data_type, 'labels/', '%s.txt'%os.path.basename(imagename)[:-4])
image_dir = os.path.join(data_dir, data_type,'images/', '%s.jpg'%os.path.basename(imagename)[:-4])
if not os.path.exists(label_path):
logging.warning('Could not find %s, ignoring example.', label_path)
continue
img = cv2.imread(imagename, cv2.IMREAD_COLOR)
with tf.gfile.GFile(imagename, 'rb') as fid:
encoded_jpg = fid.read()
encoded_jpg_io = io.BytesIO(encoded_jpg)
image = PIL.Image.open(encoded_jpg_io)
# if image.format != 'JPEG':
# raise ValueError('Image format not JPEG')
key = hashlib.sha256(encoded_jpg).hexdigest()
with open(label_path) as f:
lines = f.readlines()
xmins = []
xmaxs = []
ymins = []
ymaxs = []
class_names = []
classes = []
height = img.shape[0]
width = img.shape[1]
#print(height,width)
for line in lines:
print(line)
id, x_center, y_center, w, h = list(map(float, line.strip().split(' ')))
classes.append(int(id + 1))
class_names.append("hand")
xmins.append(float(x_center-w/2)/width)
xmaxs.append(float(x_center+w/2)/width)
ymins.append(float(y_center-h/2)/height)
ymaxs.append(float(y_center+h/2)/height)
if (x_center-w/2)/width <0:
error = True
print(f"[WARNING] Error with {line}, xmin {float(x_center-w/2)/width} < 0")
#print(f"\t row.xmin = {row.xmin} ; width = {width}")
print(label_path,height,width)
skipped += 1
continue
if (x_center+w/2)/width>1:
error = True
print(f"[WARNING] Error with {line}, xmax {float(x_center+w/2)/width} > 1")
#print(f"\t row.xmax = {row.xmax} ; width = {width}")
print(label_path,height,width)
skipped += 1
continue
if (y_center-h/2)/height<0:
error = True
print(f"[WARNING] Error with {line}, ymin {float(y_center-h/2)/height} < 0")
#print(f"\t row.ymin = {row.ymin} ; width = {width}")
print(label_path,height,width)
skipped += 1
continue
if (y_center+h/2)/height>1:
error = True
print(f"[WARNING] Error with {line}, ymax {float(y_center+h/2)/height} > 1")
#print(f"\t row.ymax = {row.ymax} ; width = {width}")
print(label_path,height,width)
skipped += 1
continue
print("skipped",skipped)
example = {'height': img.shape[0],
'width': img.shape[1],
'filename': os.path.basename(imagename),
'key': key,
'image': encoded_jpg,
'xmins': xmins,
'xmaxs': xmaxs,
'ymins': ymins,
'ymaxs': ymaxs,
'class_names': class_names,
'classes': classes}
try:
tf_example = create_tf_example(example)
if tf_example:
shard_idx = idx % num_shards
output_tfrecords[shard_idx].write(tf_example.SerializeToString())
except ValueError:
logging.warning('Invalid example: %s, ignoring.', label_path)
def main(_):
data_dir = FLAGS.data_dir
# TODO(user): Write code to read in your dataset to examples variable
logging.info('Reading from Basketball train dataset.')
create_tf_record(FLAGS.output_path, num_shards=8, data_dir=data_dir, data_type='train')
logging.info('train dataset done')
logging.info('Reading from Basketball val dataset.')
create_tf_record(FLAGS.output_path, num_shards=4, data_dir=data_dir, data_type='val')
logging.info('val dataset done')
if __name__ == '__main__':
tf.app.run()
import hashlib
import io
import logging
import os
import random
import re
import cv2
import contextlib2
from lxml import etree
import numpy as np
import PIL.Image
import tensorflow.compat.v1 as tf
from glob import glob
from object_detection.dataset_tools import tf_record_creation_util
from object_detection.utils import dataset_util
from object_detection.utils import label_map_util
flags = tf.app.flags
flags.DEFINE_string('data_dir', '', 'Root directory to raw basketball dataset.')
flags.DEFINE_string('output_path', '', 'Path to output TFRecord')
flags.DEFINE_integer('num_shards', 10, 'Number of TFRecord shards')
FLAGS = flags.FLAGS
def create_tf_example(example):
# TODO(user): Populate the following variables from your example.
height = example['height'] # Image height
width = example['width'] # Image width
filename = example['filename'].encode('utf8') # Filename of the image. Empty if image is not from file
encoded_image_data = example['image'] # Encoded image bytes
image_format = 'jpeg'.encode('utf8') # b'jpeg' or b'png'
key = example['key'].encode('utf8')
xmins = example['xmins'] # List of normalized left x coordinates in bounding box (1 per box)
xmaxs = example['xmaxs'] # List of normalized right x coordinates in bounding box
# (1 per box)
ymins = example['ymins'] # List of normalized top y coordinates in bounding box (1 per box)
ymaxs = example['ymaxs'] # List of normalized bottom y coordinates in bounding box
# (1 per box)
classes_text = [class_name.encode('utf8') for class_name in example['class_names']] # List of string class name of bounding box (1 per box)
classes = example['classes'] # List of integer class id of bounding box (1 per box)
tf_example = tf.train.Example(features=tf.train.Features(feature={
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(filename),
'image/source_id': dataset_util.bytes_feature(filename),
'image/key/sha256': dataset_util.bytes_feature(key),
'image/encoded': dataset_util.bytes_feature(encoded_image_data),
'image/format': dataset_util.bytes_feature(image_format),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmins),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymins),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
}))
return tf_example
def create_tf_record(output_filename,
num_shards,
data_dir,
data_type='train'):
"""Creates a TFRecord file from examples.
Args:
output_filename: Path to where output file is saved.
annotations_dir: Directory where annotation files are stored.
num_shards: Number of shards for output file.
image_dir: Directory where image files are stored.
"""
with contextlib2.ExitStack() as tf_record_close_stack:
output_tfrecords = tf_record_creation_util.open_sharded_output_tfrecords(
tf_record_close_stack, os.path.join(output_filename, data_type), num_shards)
image_dir = os.path.join(data_dir, "images", data_type, "*.jpg")
image_list = glob(image_dir)
for idx, imagename in enumerate(image_list):
if idx % 100 == 0:
logging.info('On image %d of %d', idx, len(image_list))
label_path = os.path.join(data_dir, 'labels', data_type, '%s.txt'%os.path.basename(imagename)[:-4])
if not os.path.exists(label_path):
logging.warning('Could not find %s, ignoring example.', label_path)
continue
img = cv2.imread(imagename, cv2.IMREAD_COLOR)
with tf.gfile.GFile(imagename, 'rb') as fid:
encoded_jpg = fid.read()
encoded_jpg_io = io.BytesIO(encoded_jpg)
image = PIL.Image.open(encoded_jpg_io)
if image.format != 'JPEG':
raise ValueError('Image format not JPEG')
key = hashlib.sha256(encoded_jpg).hexdigest()
with open(label_path) as f:
lines = f.readlines()
xmins = []
xmaxs = []
ymins = []
ymaxs = []
class_names = []
classes = []
for line in lines:
id, x_center, y_center, w, h = list(map(float, line.strip().split(' ')))
classes.append(int(id + 1))
class_names.append("basketball")
xmins.append(x_center-w/2)
xmaxs.append(x_center+w/2)
ymins.append(y_center-h/2)
ymaxs.append(y_center+h/2)
example = {'height': img.shape[0],
'width': img.shape[1],
'filename': os.path.basename(imagename),
'key': key,
'image': encoded_jpg,
'xmins': xmins,
'xmaxs': xmaxs,
'ymins': ymins,
'ymaxs': ymaxs,
'class_names': class_names,
'classes': classes}
try:
tf_example = create_tf_example(example)
if tf_example:
shard_idx = idx % num_shards
output_tfrecords[shard_idx].write(tf_example.SerializeToString())
except ValueError:
logging.warning('Invalid example: %s, ignoring.', label_path)
def main(_):
data_dir = FLAGS.data_dir
# TODO(user): Write code to read in your dataset to examples variable
logging.info('Reading from Basketball train dataset.')
create_tf_record(FLAGS.output_path, num_shards=8, data_dir=data_dir, data_type='train')
logging.info('train dataset done')
logging.info('Reading from Basketball val dataset.')
create_tf_record(FLAGS.output_path, num_shards=4, data_dir=data_dir, data_type='val')
logging.info('val dataset done')
if __name__ == '__main__':
tf.app.run()
3)去除异常数据
因为存在异常数据,即标签的bbox超出了图像尺寸,程序会报错,需要筛掉这部分数据。
问题参考:
https://github.com/tensorflow/models/issues/5474
此部分代码已包含在2)中,再单独拿出来贴在此处:
for line in lines:
print(line)
id, x_center, y_center, w, h = list(map(float, line.strip().split(' ')))
classes.append(int(id + 1))
class_names.append("hand")
if (x_center-w/2) <0:
error = True
print(f"[WARNING] Error with {line}, xmin {float(x_center-w/2)} < 0")
#print(f"\t row.xmin = {row.xmin} ; width = {width}")
print(label_path,height,width)
skipped += 1
continue
if (x_center+w/2)>1:
error = True
print(f"[WARNING] Error with {line}, xmax {float(x_center+w/2)} > 1")
#print(f"\t row.xmax = {row.xmax} ; width = {width}")
print(label_path,height,width)
skipped += 1
continue
if (y_center-h/2)<0:
error = True
print(f"[WARNING] Error with {line}, ymin {float(y_center-h/2)} < 0")
#print(f"\t row.ymin = {row.ymin} ; width = {width}")
print(label_path,height,width)
skipped += 1
continue
if (y_center+h/2)>1:
error = True
print(f"[WARNING] Error with {line}, ymax {float(y_center+h/2)} > 1")
#print(f"\t row.ymax = {row.ymax} ; width = {width}")
print(label_path,height,width)
skipped += 1
continue
xmins.append(float(x_center-w/2))
xmaxs.append(float(x_center+w/2))
ymins.append(float(y_center-h/2))
ymaxs.append(float(y_center+h/2))
flag += 1通过筛查,一共统计出200多异常数据。
4.训练及评估
这部分只需要修改config文件,填入数据集路径和txt路径;
若需要减小模型大小,只需要将config中的depth_multiplier由1改为0-1之间的小数,实测精度减小不大。
python model_main.py –pipeline_config_path=~/models/research/object_detection/hand.config –model_dir=~/models/ –num_train_steps=20000 –sample_1_of_n_eval_examples=1 –alsologtostderr
5.模型转化
首先将ckpt模型转化为pb模型,运行api自带代码即可:
python object_detection/export_tflite_ssd_graph.py –pipeline_config_path=~/research/object_detection/hand.config –trained_checkpoint_prefix=~/models/model.ckpt-10000 –output_directory=~/models/save/ –add_postprocessing_op=true
此处注意不需要修改生成的模型后缀, model.ckpt-10000代表会用到生成的index,meta及data-00000-of-00001。
运行完毕生成pb和pbtxt,还需要转化为tflite以便我们的轻量化移动端使用,代码如下:
import tensorflow as tf
import numpy as np
if __name__ == "__main__":
# convert uint8 model
path_to_frozen_graphdef_pb = 'tflite_graph.pb'
converter = tf.lite.TFLiteConverter.from_frozen_graph(path_to_frozen_graphdef_pb,
["normalized_input_image_tensor"],
[
'BoxPredictor_0/BoxEncodingPredictor/act_quant/FakeQuantWithMinMaxVars',
'BoxPredictor_1/BoxEncodingPredictor/act_quant/FakeQuantWithMinMaxVars',
'BoxPredictor_2/BoxEncodingPredictor/act_quant/FakeQuantWithMinMaxVars',
'BoxPredictor_3/BoxEncodingPredictor/act_quant/FakeQuantWithMinMaxVars',
'BoxPredictor_4/BoxEncodingPredictor/act_quant/FakeQuantWithMinMaxVars',
'BoxPredictor_5/BoxEncodingPredictor/act_quant/FakeQuantWithMinMaxVars',
'BoxPredictor_0/ClassPredictor/act_quant/FakeQuantWithMinMaxVars',
'BoxPredictor_1/ClassPredictor/act_quant/FakeQuantWithMinMaxVars',
'BoxPredictor_2/ClassPredictor/act_quant/FakeQuantWithMinMaxVars',
'BoxPredictor_3/ClassPredictor/act_quant/FakeQuantWithMinMaxVars',
'BoxPredictor_4/ClassPredictor/act_quant/FakeQuantWithMinMaxVars',
'BoxPredictor_5/ClassPredictor/act_quant/FakeQuantWithMinMaxVars'
# 'hand_landmark/handness_identity',
],
input_shapes={"normalized_input_image_tensor":[1, 300, 300, 3]})
converter.inference_type = tf.lite.constants.QUANTIZED_UINT8
converter.optimizations = ['DEFAULT']
converter.quantized_input_stats = {"normalized_input_image_tensor": (128, 128)}
converter.allow_custom_ops = True
converter.default_ranges_stats = (0, 255)
converter.change_concat_input_ranges = False
# # converter.post_training_quantize = True
# # converter.representative_dataset = representative_dataset
#
tflite_model = converter.convert()
open("ssd.tflite", 'wb').write(tflite_model)运行完毕,生成tflite模型,模型大小仅为600余kb,整个满足需求。
后续发现此代码生成的模型的输出维度不对,无法完成检测,使用tensorflow自带代码进行pb到tflite的转化,能够得到正常的检测结果:
tflite_convert
–enable_v1_converter
–graph_def_file=
~/models/save
/tflite_graph.pb
–output_file=
~/models/save
/detect.tflite
–input_shapes=1,300,300,3
–input_arrays=normalized_input_image_tensor
–output_arrays=’TFLite_Detection_PostProcess’,’TFLite_Detection_PostProcess:1′,’TFLite_Detection_PostProcess:2′,’TFLite_Detection_PostProcess:3′
–inference_type=QUANTIZED_UINT8
–mean_values=128
–std_dev_values=128
–change_concat_input_ranges=false
–allow_custom_ops
注意,转换模型都使用tf2.x版本进行运行,1.x版本会报错。
另外,使用上述数据集模型MAP始终不高,不超过20%。
更改新的数据集进行训练:
https://fouheylab.eecs.umich.edu/~dandans/projects/100DOH/downloads/README_100K.md
该数据集可以达到20%以上(尚未精调),目前IOU为0.5时map可以达到58.7%,还在持续训练中。期间换了好几次数据集==,数据集的调研工作非常重要。
6.测试
此处测试用tflite模型推理,生成单张图的目标检测框,代码如下:
# -*- coding: gbk -*-
#经coco模型检验,本测试代码无误
import tensorflow as tf
import numpy as np
import cv2
network_w = 300
network_h = 300
det_score = 0.0
inference_type = 'fp16'
#inference_type = 'uint8'
image = r'/home/Yolo-FastestV2-main/img/hand1.jpg' #dog #staff
labels_path = r'/home/models/research/object_detection/data/mscoco_label_map.pbtxt'
if inference_type == 'int8' or inference_type == 'uint8':
#intput_tflite_file = r"F:\model\tflite\ssd-mobilenet\ssd-mobilenetv1-0.75-quant-uint8.tflite"
#intput_tflite_file = r"F:\model\tflite\ssd-mobilenet\ssd-mobilenetv1-1.0-quant-uint8.tflite"
intput_tflite_file = r"/home/models/save/test/detect.tflite"
#intput_tflite_file = r"F:\android\git\tf-examples\lite\examples\object_detection\android\app\src\main\assets\lite-model_ssd_mobilenet_v1_1_metadata_2.tflite"
elif inference_type == 'fp16' or inference_type == 'float16':
#intput_tflite_file = r'F:\model\tflite\ssd-mobilenet\ssd-mobilenetv1-0.75-quant-fp16.tflite'
#intput_tflite_file = r'F:\model\tflite\ssd-mobilenet\ssd-mobilenetv1-1.0-quant-fp16.tflite'
#intput_tflite_file = r'/home/models/save/float/0.25/detect.tflite'
intput_tflite_file = r'/home/models/save/float/egohand/detect.tflite'
def test_tflite(input_test_tflite_file, new_img, inference_type):
interpreter = tf.lite.Interpreter(model_path=input_test_tflite_file)
tensor_details = interpreter.get_tensor_details()
for i in range(0, len(tensor_details)):
# print("tensor:", i, tensor_details[i])
interpreter.allocate_tensors()
input_details = interpreter.get_input_details()
print("=======================================")
print("input :", str(input_details))
output_details = interpreter.get_output_details()
print("ouput :", str(output_details))
print("=======================================")
# new_img = np.expand_dims(new_img, axis=0)#提升维度
if inference_type == 'int8' or inference_type == 'uint8':
new_img = new_img.astype('uint8') # 类型也要满足要求
elif inference_type == 'fp16' or inference_type == 'float16':
new_img = new_img.astype('float32')
interpreter.set_tensor(input_details[0]['index'], new_img)
# 注意注意,我要调用模型了
interpreter.invoke()
detection_boxes = interpreter.get_tensor(output_details[0]['index'])
detection_classes = interpreter.get_tensor(output_details[1]['index'])
detection_scores = interpreter.get_tensor(output_details[2]['index'])
num_detections = interpreter.get_tensor(output_details[3]['index'])
print("test_tflite finish!")
return detection_boxes, detection_classes, detection_scores, num_detections
if __name__ == "__main__":
labels_name = 'hand'
frame = cv2.imread(image)
image_w = frame.shape[1]
image_h = frame.shape[0]
if inference_type == 'int8' or inference_type == 'uint8':
input = cv2.dnn.blobFromImage(frame, 1, (network_w, network_h), [0, 0, 0], 1)
elif inference_type == 'fp16' or inference_type == 'float16':
input = cv2.dnn.blobFromImage(frame, 2.0 / 255.0, (network_w, network_h), [127.5, 127.5, 127.5], 1)
input = input.transpose((0,2,3,1))#维度互换
detection_boxes, detection_classes, detection_scores, num_detections = test_tflite(intput_tflite_file, input, inference_type)
print(detection_scores)
#idx = np.argmax(scores[0])
for i in range(int(num_detections[0])):
ymin, xmin, ymax, xmax = detection_boxes[0][i]
the_score = detection_scores[0][i]
the_label = detection_classes[0][i]
if the_score > det_score:
# print(the_score)
# continue
cv2.rectangle(frame, (int(image_w*xmin),int(image_h*ymin)), (int(image_w*xmax),int(image_h*ymax)), (0,255,0), 2)
cv2.putText(frame, str(int(the_score*100)) + "%", (int(image_w*xmin),int(image_h*ymin) - 5), 0, 0.75, (255, 0, 0), 1)
cv2.putText(frame, labels_name, (int(image_w*xmin) + 50,int(image_h*ymin) - 5), 0, 0.7, (0, 255, 0), 2)
cv2.imwrite("/home/models/save/float/egohand/result.jpg", frame)7.移动端部署
参照tensor官方教程即可。
8.踩坑记录
配环境就非常多坑,记录一下我还记得的几个:
1)找不到object_detection
在research目录下运行sudo python setup.py install
2)需要确认环境是否是GPU版本
如何安装并查看tensorflow-gpu版本及可否使用_fighting_!的博客-CSDN博客_tensorflow查看gpu
tf.test.is_gpu_available()
我一开始是装的GPU版本,最后跑的时候却不是,一言难尽。
3)机器cudn和cudnn版本不一致
运行过程中并无报错,训练第一步loss全部nan,找了非常多的原因,最后我认为是机器的cudn和cudnn版本不一致,最终也并没有解决该问题,更换机器就完事。。。
5.基于y通道的TF的手部检测
因硬件camera采集nv12格式数据流,为了减少nv12转RGB的时间,使用y通道进行训练,此处了解nv12格式:
NV12等常用YUV数据格式_泠山的博客-CSDN博客_nv12
直接在生成tfrecord的代码中修改几行的偷懒行为是不ok的,将数据转化为三通道y图像再生成tfrecord就没问题了,这个代码很简单,就是等待转化的时间比较久:
#coding=gbk
import os
import cv2
def getFileList(dir,Filelist, ext=None):
newDir = dir
if os.path.isfile(dir):
if ext is None:
Filelist.append(dir)
else:
if ext in dir[-3:]:
Filelist.append(dir)
elif os.path.isdir(dir):
for s in os.listdir(dir):
newDir=os.path.join(dir,s)
getFileList(newDir, Filelist, ext)
return Filelist
org_img_folder='/100DOH-original/images/train/'
save_folder = '/100DOH-original/images_yyy/train/'
imglist = getFileList(org_img_folder, [], 'jpg')
print('本次执行检索到 '+str(len(imglist))+' 张图像\n')
i=1
for imgpath in imglist:
imgname= os.path.splitext(os.path.basename(imgpath))[0]
print("进行到第几张",i)
img = cv2.imread(imgpath, cv2.IMREAD_COLOR)
img_yuv = cv2.cvtColor(img, cv2.COLOR_BGR2YUV)
(img_y,img_u,img_v) = cv2.split(img_yuv)
img_yyy = cv2.merge([img_y,img_y,img_y])
cv2.imwrite(save_folder+"/"+imgname + ".jpg", img_yyy)
i = i+1
相比RGB图像的效果会差一些,但是也可以接受,正在持续优化中。
6.相关学习资料
评价指标:
目标检测评价指标 – 知乎
算法介绍:
你一定从未看过如此通俗易懂的YOLO系列(从v1到v5)模型解读 (上) – 知乎
GitHub – luanshiyinyang/YOLO: YOLO目标检测算法的介绍。
极市开发者平台-计算机视觉算法开发落地平台
ShowMeAI知识社区
【深度学习】目标检测算法 YOLO 最耐心细致的讲解_frank909的博客-CSDN博客_yolo检测
其他: