一、什么是hive?
hive是基于hadoop的一个
数据仓库
工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在hadoop、中的大规模数据的机制。hive数据仓库工具能将将结构化的数据文件映射为一张数据库表,并提供
SQL
查询功能,能将SQL语句转变成
MapReduce
任务来执行。
二、架构图
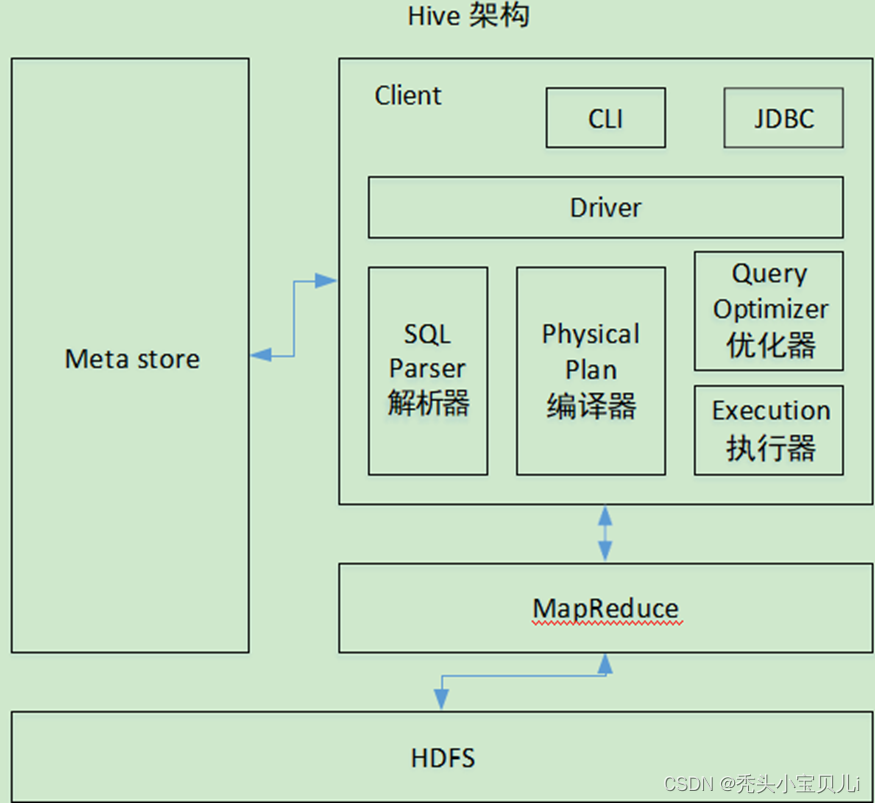
Meta store(元数据存储)
:通常是存储在关系数据库如
mysql/derby
中。hive将元数据存储在数据库中,
hive
中的元数据包括表的名字,表的列和分区,表的属性(内部表、外部表)。
Client(用户接口)
:包括
CLI、JDBC/ODBC、WebGUI
。
CLI
是
shell
命令行;
JDBC/ODBC
是
hive
的
java
实现;
WebGUI
通过浏览器访问
hive
。
解析器、编译器、优化器、执行器
:完成
HQL
查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在
HDFS
中,最后由
MapReduce
调用执行。
详解:
Hive
通过给用户提供一系列交互接口,接收用户的指令(
shell
脚本、
sql
语句),将sql转换成抽象语法树
AST
的解析器,将
AST
编译成逻辑执行计划的编译器,在对逻辑执行计划进行优化,最后将逻辑计划转变成
MapReduce
,提交给
HDFS。