Focal Loss for Dense Object Detection
##目录
文章目录
1. 动机
1.1 单级结构识别度低的分析
- 作者认为单级结构识别度低是由于类别失衡(class imbalance)造成的,如SSD,YOLO这种单级网络识别都是根据区域采样的方式实现(像SSD300,8732个采样框),这些框大部分对应着背景,也就是negative,只有少部分是positive(与GT重合度高的),因而这就导致两个问题:
- negative examples过多,使得其对loss贡献很大,以至于把positive的loss都淹没掉了,从而不利于目标的收敛。
- 虽然negative 贡献的loss大,但是由于negative很多,所以每个negative examples对于loss的贡献较小(因为negative中有很多easy negative),因而反向计算时梯度小。梯度小造成easy negative example对参数的收敛作用很有限,我们更需要loss大的对参数收敛影响也更大的example,即hard positive/negative example。注意easy/hard, positive/negative examples概念的不同,hard positive/negative 更有利于学习过程
- 总之,由于negative过多(easy negative占很大部分),导致positive对loss贡献被淹没,以及单个negative对loss的贡献小
- 主要通过
α
\alpha
α调整正负平衡; 用(
1
−
p
)
γ
(1-p)^\gamma
(1−p)γ用于平衡容易和难例的
1.2 Faster RCNN两级结构的特性
- FasterRCNN 会对RPN输出的区域推荐进行过滤,过滤出高分数的推荐框(1k-2k个),这个过程将大量easy negative过滤掉,这解决了起那么第二个问题。
- 然后,还对正负例的比例进行调整,用IOU进行pos与neg的比例,如设置为1:3。这样就防止了negative过多的情况(同时防止了easy negative和hard negative)。解决了前面第一个问题,减小negative对loss的过于贡献。
1.3 OHEM
OHEM是一种example筛选方法,使得模型在训练过程中仅学习hard examples;在计算损失时,先通过对loss排序,选出loss最大的example进行训练,这就是保证金仅仅学习hard examples。但是这个方法存在一个不足,就是把所有的easy example都去除掉了,对于easy positive example它也给过滤了,导致这样的正例无法进一步提升训练精度。
下图给出easy positive/negative example,hard positive/negative example的示意图:
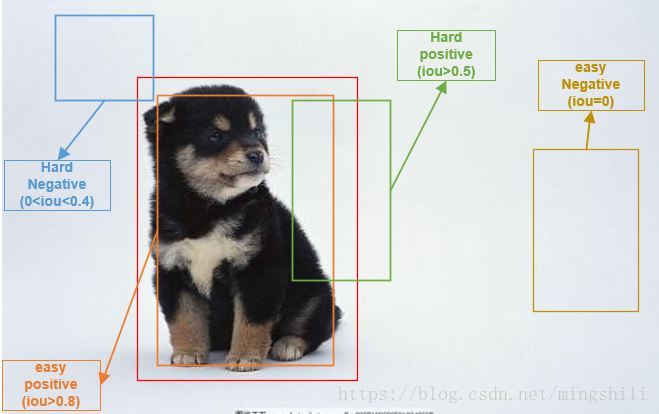
2. 损失的作用
![]()
-
(
1
−
p
t
)
(1-p_{t})
(1−pt)是用于对easy example进行权重抑制。无论正负例,当p
t
p_t
pt越大,说明预测越好,则它的权重(
1
−
p
t
)
(1-p_{t})
(1−pt)越小。 -
γ
\gamma
γ起到smoothly adjust,轮滑这个权重抑制 -
α
t
\alpha_{t}
αt用于调节正负例比例的,正例使用α
t
\alpha_{t}
αt,负例(背景)使用1
−
α
t
1-\alpha_{t}
1−αt。
需要注意的是:
- 计算
p
t
p_t
pt时,用sigmoid更好; - 在训练前期,因为positivie和negative的分类概率基本一致,会造成FocalLoss起不到抑制easy example的作用;为了避免这种情况,作者对最后一级用于分类的卷积的bias作了一些修改,把它初始化成一个特殊的值b=-log((1-π)/π)。π在论文中取0.01,这样做能在训练初始阶段提高positive的分类概率。
##3. 启示
- 这个论文分析了单级物体检测网络的弊端,对class imbalance进行了深入分析,并从损失函数入手,解决存在的问题。对于class imbalance问题,我们是否还能从其他方面入手,或者还有更好的损失对这个问题进行优化。
- 在进行网络训练时,我们可以根据实际数据情况,定义一些约束性的损失函数,是网络学习更加有目的性。
参考文献
1:https://www.jianshu.com/p/204d9ad9507f
2:https://arxiv.org/abs/1708.02002